Nothing
inst/include/bench.md
In sparsepp: 'Rcpp' Interface to 'sparsepp'
Improving on Google's excellent Sparsehash
[tl;dr]
1. Looking for a great hash map
2. Google Sparsehash: brilliant idea, sparse version a bit slow and dated
3. Introducing Sparsepp: fast, memory efficient, C++11, single header
Hashtables, sparse and dense, maps and btrees - Memory usage
First, let's compare two separate versions of std::unordered_map, from Boost and g++ (the test was done using Boost version 1.55 and g++ version 4.8.4 on Ubuntu 14.02, running on a VM with 5.8GB of total memory space (under VirtualBox), 5.7GB free before benchmarks. For all tests that follow, hash entries were inserted in an initially empty, default sized container, without calling resize to preallocate the necessary memory. The code for the benchmarks is listed at the end of this article.
The graph below shows the memory usage when inserting std::pair<uint64_t, uint64_t> into the unordered_map.
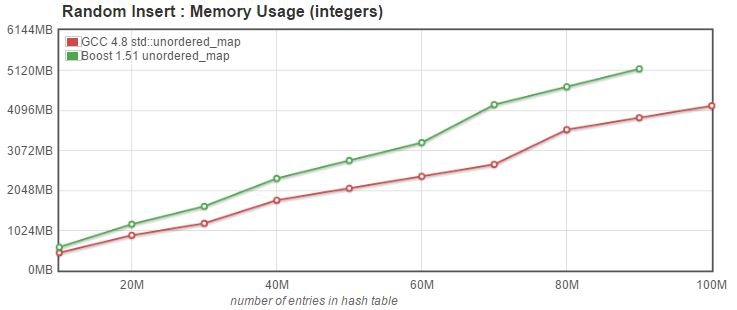
With this test, we see that Boost's implementation uses significantly more memory that the g++ version, and indeed it is unable to insert 100 Million entries into the map without running out of memory. Since the pairs we insert into the map are 16 bytes each, the minimum expected memory usage would be 1.6 GB. We see on the graph that g++ needs just a hair over 4 GB.
Now, let's add to the comparison Google's offerings: the Sparsehash and cpp-btree libraries.
The Sparsehash library is a header-only library, open-sourced by Google in 2005. It offers two separate hash map implementations with very different performance characteristics. sparse_hash_map is designed to use as little memory as possible, at the expense of speed if necessary. dense_hash_map is extremely fast, but gobbles memory.
The cpp-btree library was open-sourced by Google in 2013. Although not a hash map, but a map storing ordered elements, I thought it would be interesting to include it because it claims low memory usage, and good performance thanks to cache friendliness.
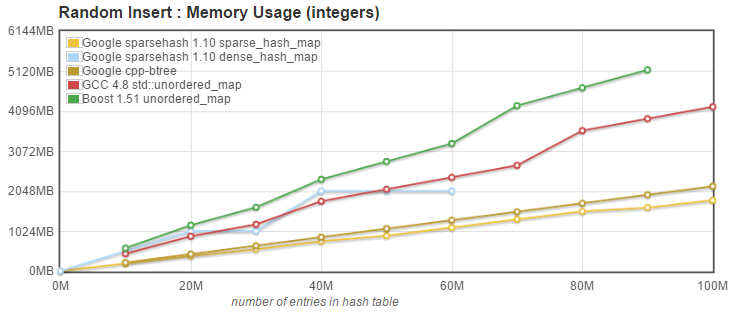
So what do we see here?
Google's dense_hash_map (blue curve) was doing well below 60 Million entries, using an amount of memory somewhat in between the Boost and g++ unordered_map implementations, but ran out of memory when trying to insert 70 Million entries.
This is easily understood because Google's dense_hash_map stores all the entries in a large contiguous array, and resizes the array by doubling its size when the array is 50% full.
For 40M to 60M elements, the dense_hash_map used 2GB. Indeed, 60M entries, each 16 byte in size, would occupy 960Mb. So 70M entries would require over 50% of 2GB, causing a resize to 4Gb. And when the resize occurs, a total of 6GB is allocated, as the entries have to be transferred from the 2GB array to the 4GB array.
So we see that the dense_hash_map has pretty dramatic spikes in memory usage when resizing, equal to six times the space required for the actual entries. For big data cases, and unless the final size of the container can be accurately predicted and the container sized appropriately, the memory demands of dense_hash_map when resizing may remove it from consideration for many applications.
On the contrary, both Google's sparse_hash_map and btree_map (from cpp-btree) have excellent memory usage characteristics. The sparse_hash_map, as promised, has a very small overhead (it uses about 1.9GB, just 18% higher than the theorical minimum 1.6GB). The btree_map uses a little over 2GB, still excellent.
Interestingly, the memory usage of both sparse_hash_map and btree_map increases regularly without significant spikes when resizing, which allows them to grow gracefully and use all the memory available.
The two std::unordered_map implementations do have memory usage spikes when resizing, but less drastic than Google's dense_hash_map. This is because std::unordered_map implementations typically implement the hash map as an array of buckets (all entries with the same hash value go into the same bucket), and buckets store entries into something equivalent to a std::forward_list. So, when resizing, while the bucket array has to be reallocated, the actual map entries can be moved to their new bucket without requiring extra memory.
What about performance?
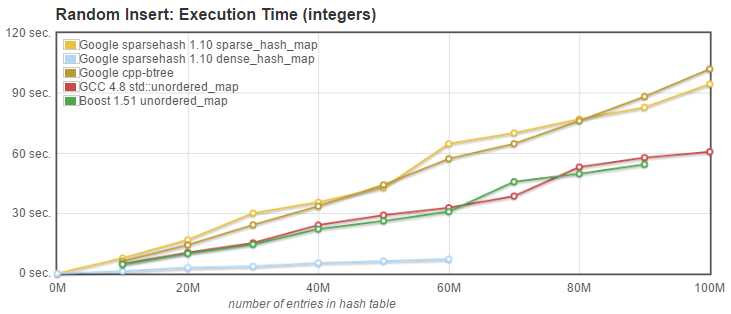
Memory usage is one thing, but we also need efficient containers allowing fast insertion and lookup. We ran series of three benchmarks, still using the same std::pair<uint64_t, uint64_t> value_type. While randomized, the sequence of keys was the same for each container tested.
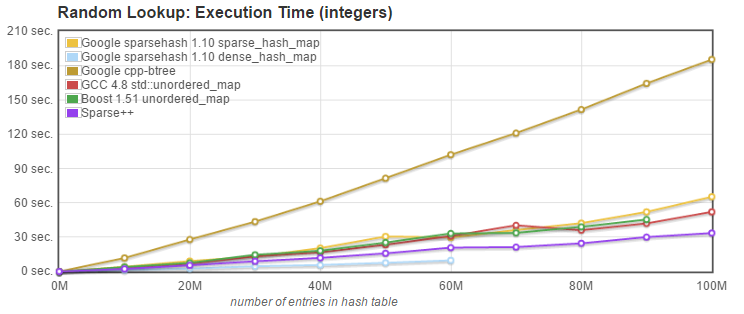
- Random Insert: we measured the time needed to insert N entries into an initially empty, default sized container, without calling resize to preallocate the necessary memory. Keys were inserted in random order, i.e. the integer keys were not sorted.
API used:
pair<iterator,bool> insert(const value_type& val);
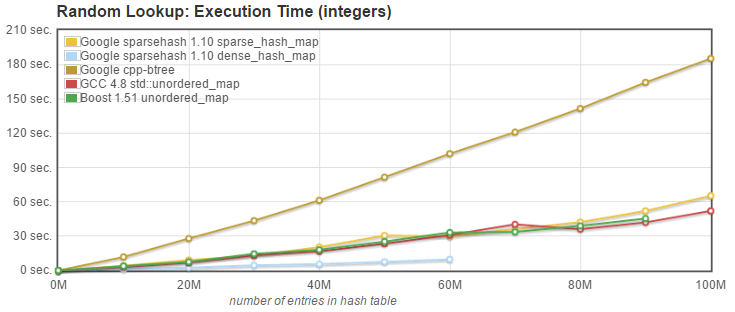
- Random Lookup: we measured the time needed to retrieve N entries known to be present in the array, plus N entries with only a 10% probablility to be present.
API used:
iterator find(const key_type& k);
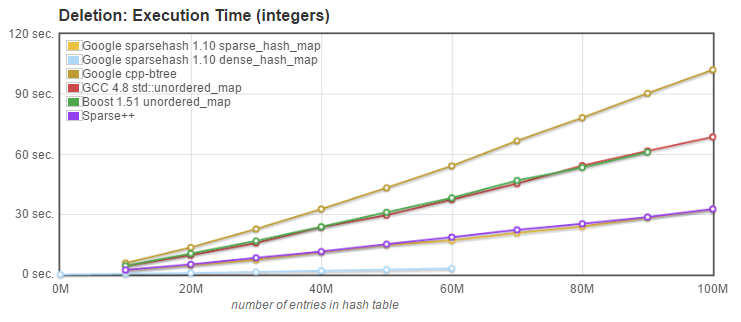
- Delete: we measured the time needed to delete the N entries known to be present in the array. Entries had been inserted in random order, and are deleted in a different random order.
API used:
size_type erase(const key_type& k);
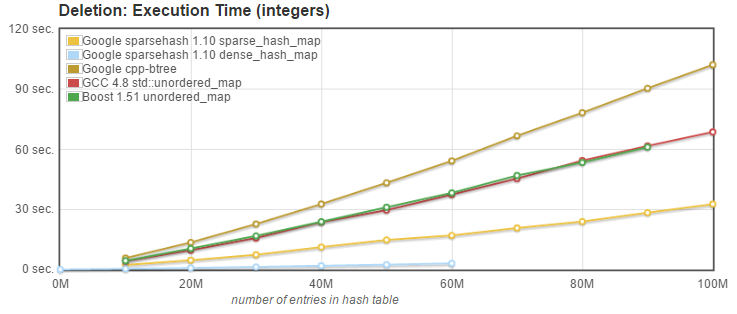
What can we conclude from these tests? Here are my observations:
-
Until it runs out of memory at 60M entries, Google's dense_hash_map is consistently the fastest, often by a quite significant margin.
-
Both Boost and g++ unordered_maps have very similar performance, which I would qualify as average amoung the alternatives tested.
-
Google's btree_map (from cpp-btree) does not perform very well on these tests (where the fact that it maintains the ordering of entries is not used). While it is competitive with the sparse_hash_map for insertion, the lookup time is typically at least 3 time higher than the slowest hash map, and deletion is slower as well. This is not unexpected as the btree complexity on insert, lookup and delete is O(log n).
-
Google's sparse_hash_map is very competitive, as fast as the std::unordered_maps on lookup, faster at deletion, but slower on insert. Considering its excellent memory usage characteristics, I would say it is the best compromise.
So, if we are looking for a non-ordered associative container on linux[^1], I think the two Google offerings are most attractive:
-
Google's dense_hash_map: extremely fast, very high memory requirement (unless the maximum numbers of entries is known in advance, and is not just a little bit greater than a power of two).
-
Google's sparse_hash_map: very memory efficient, fast lookup and deletion, however slower that std::unordered_map on insertion.
Introducing Sparsepp
At this point, I started wondering about the large speed difference between the sparse and dense hash_maps by Google. Could that performance gap be reduced somewhat? After all, both use open adressing with internal quadratic probing.
I was also intrigued by the remarkable sparse_hash_map memory efficiency, and wanted to fully understand its implementation, which is based on a sparsetable.
As I read the code and followed it under the debugger, I started having ideas on how to speed-up the sparse_hash_map, without significantly increasing the memory usage. That little game was addictive, and I found myself trying various ideas: some which provided significant benefits, and some that didn't pan out.
Regardless, after a few months of work on evenings and week-ends, I am proud to present Sparsepp, a heavily modified version of Google's sparse_hash_map which offers significant performance improvements, while maintaining a a very low memory profile.
The graphs below show the relative performance (purple line) of the Sparsepp sparse_hash_map compared to the other implementations:
Note: "Sparse++" in the graphs legend is actually "Sparsepp".
- Random Insert: Sparsepp, while still slower than the dense_hash_map, is significantly faster than the original sparse_hash_map and the btree_map, and as fast as the two std::unordered_map implementations.
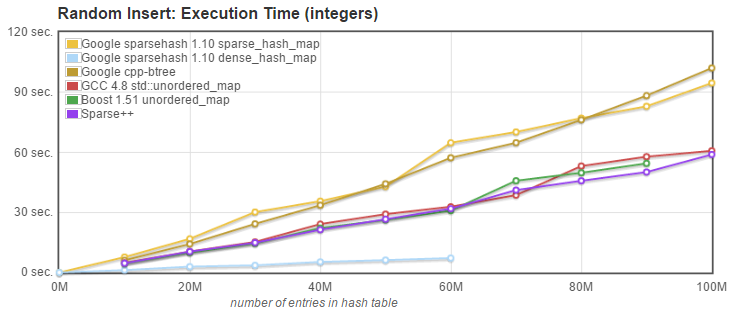
- Random Lookup (find): Sparsepp is faster than all other alternatives, except for dense_hash_map.
- Delete (erase): Sparsepp is again doing very well, outperformed only by dense_hash_map. We should note that unlike the original sparse_hash_map, Sparsepp's sparse_hash_map does release the memory on erase, instead of just overwriting the memory with the deleted key value. Indeed, the non-standard APIs set_deleted_key() and set_empty_key(), while still present for compatibility with the original sparse_hash_map, are no longer necessary or useful.
Looks good, but what is the cost of using Sparsepp versus the original sparse_hash_map in memory usage:
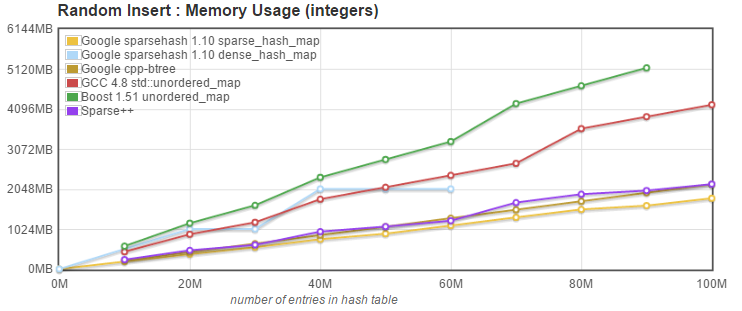
Not bad! While Sparsepp memory usage is a little bit higher than the original sparse_hash_map, it is still memory friendly, and there are no memory spikes when the map resizes. We can see that when moving from 60M entries to 70M entries, both Google's dense and Sparsepp hash_maps needed a resize to accomodate the 70M elements. The resize proved fatal for the dense_hash_map, who could not allocate the 6GB needed for the resize + copy, while the Sparsepp sparse_hash_map had no problem.
In order to validate that the sparse hash tables can indeed grow to accomodate many more entries than regular hash tables, we decided to run a test that would gounsert items until all tables run out of memory, the result of which is presented in the two graphs below:
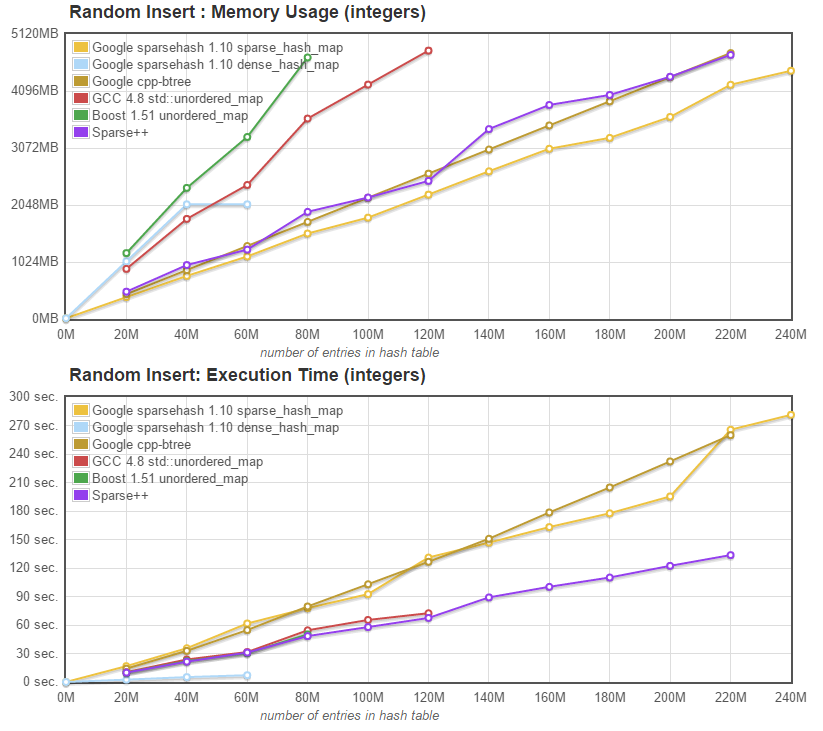
The table below display the maximum number of entries that could be added to each map before it ran out of memory. As a reminder, the VM had 5.7GB free before each test, and each entry is 16 bytes.
Max entries | Google's dense_hash | Boost unordered | g++ unordered | Google's btree_map | Sparsepp | Google's sparse_hash
------------ | -------------- | --------------- | -------------- | --------- | -------- | ---------------
in millions | 60 M | 80 M | 120 M | 220 M | 220 M | 240 M
Both sparse hash implementations, as well as Google's btree_map are significantly more memory efficient than the classic unordered_maps. They are also significantly slower that Sparsepp.
If we are willing to sacrifice a little bit of insertion performance for improved memory efficiency, it is easily done with a simple change in Sparsepp header file sparsepp.h. Just change:
#define SPP_ALLOC_SZ 0
to
#define SPP_ALLOC_SZ 1
With this change, we get the graphs below:
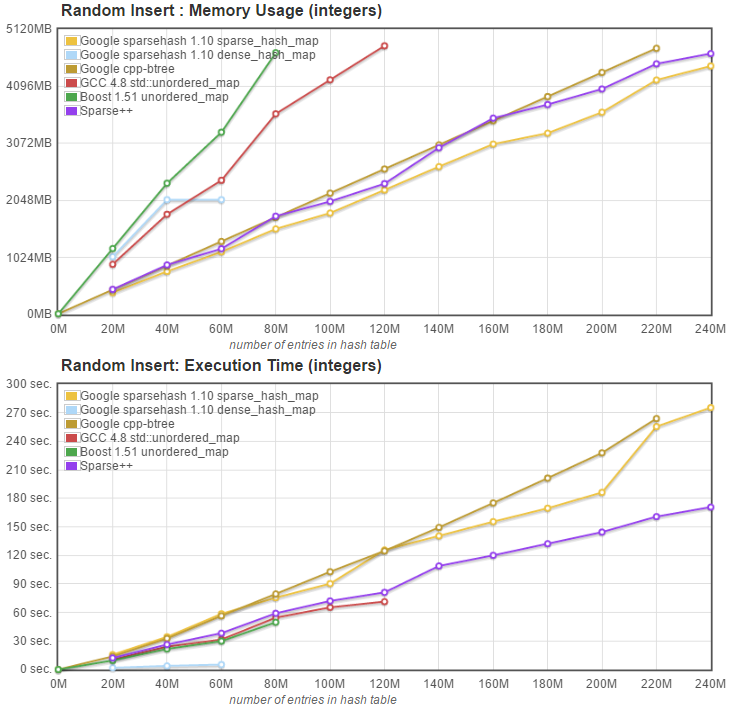
Now the memory usage of Sparsepp is reduced to just a little bit more than Google's sparse_hash_map, and both sparse map implementations are able to insert 240 Million entries, but choke at 260 Million. Sparsepp is a little bit slower on insert, but still significantly faster than Google's sparse_hash_map. Lookup performance (not graphed) is unchanged.
To conclude, we feel that Sparsepp provides an unusual combination of performance and memory economy, and will be a useful addition to every developer toolkit.
Here are some other features of Sparsepp you may find attractive:
-
Single header implementation: the full Sparsepp resides in the single header file sparsepp.h. Just copy this file in your project, #include it, and you are good to go.
-
C++11 compatible: move semantics, cbegin()/cend(), stateful allocators
Benchmarks code
template <class T>
void _fill(vector<T> &v)
{
srand(1); // for a fair/deterministic comparison
for (size_t i = 0, sz = v.size(); i < sz; ++i)
v[i] = (T)(i * 10 + rand() % 10);
}
template <class T>
void _shuffle(vector<T> &v)
{
for (size_t n = v.size(); n >= 2; --n)
std::swap(v[n - 1], v[static_cast<unsigned>(rand()) % n]);
}
template <class T, class HT>
double _fill_random(vector<T> &v, HT &hash)
{
_fill<T>(v);
_shuffle<T>(v);
double start_time = get_time();
for (size_t i = 0, sz = v.size(); i < sz; ++i)
hash.insert(typename HT::value_type(v[i], 0));
return start_time;
}
template <class T, class HT>
double _lookup(vector<T> &v, HT &hash, size_t &num_present)
{
_fill_random(v, hash);
num_present = 0;
size_t max_val = v.size() * 10;
double start_time = get_time();
for (size_t i = 0, sz = v.size(); i < sz; ++i)
{
num_present += (size_t)(hash.find(v[i]) != hash.end());
num_present += (size_t)(hash.find((T)(rand() % max_val)) != hash.end());
}
return start_time;
}
template <class T, class HT>
double _delete(vector<T> &v, HT &hash)
{
_fill_random(v, hash);
_shuffle(v); // don't delete in insertion order
double start_time = get_time();
for(size_t i = 0, sz = v.size(); i < sz; ++i)
hash.erase(v[i]);
return start_time;
}
[^1]: Google's hash maps were most likely developed on linux/g++. When built on Windows with Visual Studio (2015), the lookup of items is very slow, to the point that the sparse hashtable is not much faster than Google's btree_map (from the cpp-btree library). The reason for this poor performance is that Google's implementation uses by default the hash functions provided by the compiler, and those provided by the Visual C++ compiler turn out to be very inefficient. If you are using Google's sparse_hash_map on Windows, you can look forward to an even greater performance increase when switching to Sparsepp.
Try the sparsepp package in your browser
Any scripts or data that you put into this service are public.
sparsepp documentation built on May 2, 2019, 9:16 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Improving on Google's excellent Sparsehash
[tl;dr]
1. Looking for a great hash map
2. Google Sparsehash: brilliant idea, sparse version a bit slow and dated
3. Introducing Sparsepp: fast, memory efficient, C++11, single header
Hashtables, sparse and dense, maps and btrees - Memory usage
First, let's compare two separate versions of std::unordered_map, from Boost and g++ (the test was done using Boost version 1.55 and g++ version 4.8.4 on Ubuntu 14.02, running on a VM with 5.8GB of total memory space (under VirtualBox), 5.7GB free before benchmarks. For all tests that follow, hash entries were inserted in an initially empty, default sized container, without calling resize to preallocate the necessary memory. The code for the benchmarks is listed at the end of this article.
The graph below shows the memory usage when inserting std::pair<uint64_t, uint64_t> into the unordered_map.
With this test, we see that Boost's implementation uses significantly more memory that the g++ version, and indeed it is unable to insert 100 Million entries into the map without running out of memory. Since the pairs we insert into the map are 16 bytes each, the minimum expected memory usage would be 1.6 GB. We see on the graph that g++ needs just a hair over 4 GB.
Now, let's add to the comparison Google's offerings: the Sparsehash and cpp-btree libraries.
The Sparsehash library is a header-only library, open-sourced by Google in 2005. It offers two separate hash map implementations with very different performance characteristics. sparse_hash_map is designed to use as little memory as possible, at the expense of speed if necessary. dense_hash_map is extremely fast, but gobbles memory.
The cpp-btree library was open-sourced by Google in 2013. Although not a hash map, but a map storing ordered elements, I thought it would be interesting to include it because it claims low memory usage, and good performance thanks to cache friendliness.
So what do we see here?
Google's dense_hash_map (blue curve) was doing well below 60 Million entries, using an amount of memory somewhat in between the Boost and g++ unordered_map implementations, but ran out of memory when trying to insert 70 Million entries.
This is easily understood because Google's dense_hash_map stores all the entries in a large contiguous array, and resizes the array by doubling its size when the array is 50% full.
For 40M to 60M elements, the dense_hash_map used 2GB. Indeed, 60M entries, each 16 byte in size, would occupy 960Mb. So 70M entries would require over 50% of 2GB, causing a resize to 4Gb. And when the resize occurs, a total of 6GB is allocated, as the entries have to be transferred from the 2GB array to the 4GB array.
So we see that the dense_hash_map has pretty dramatic spikes in memory usage when resizing, equal to six times the space required for the actual entries. For big data cases, and unless the final size of the container can be accurately predicted and the container sized appropriately, the memory demands of dense_hash_map when resizing may remove it from consideration for many applications.
On the contrary, both Google's sparse_hash_map and btree_map (from cpp-btree) have excellent memory usage characteristics. The sparse_hash_map, as promised, has a very small overhead (it uses about 1.9GB, just 18% higher than the theorical minimum 1.6GB). The btree_map uses a little over 2GB, still excellent.
Interestingly, the memory usage of both sparse_hash_map and btree_map increases regularly without significant spikes when resizing, which allows them to grow gracefully and use all the memory available.
The two std::unordered_map implementations do have memory usage spikes when resizing, but less drastic than Google's dense_hash_map. This is because std::unordered_map implementations typically implement the hash map as an array of buckets (all entries with the same hash value go into the same bucket), and buckets store entries into something equivalent to a std::forward_list. So, when resizing, while the bucket array has to be reallocated, the actual map entries can be moved to their new bucket without requiring extra memory.
What about performance?
Memory usage is one thing, but we also need efficient containers allowing fast insertion and lookup. We ran series of three benchmarks, still using the same std::pair<uint64_t, uint64_t> value_type. While randomized, the sequence of keys was the same for each container tested.
- Random Insert: we measured the time needed to insert N entries into an initially empty, default sized container, without calling resize to preallocate the necessary memory. Keys were inserted in random order, i.e. the integer keys were not sorted.
API used:
pair<iterator,bool> insert(const value_type& val);
- Random Lookup: we measured the time needed to retrieve N entries known to be present in the array, plus N entries with only a 10% probablility to be present.
API used:
iterator find(const key_type& k);
- Delete: we measured the time needed to delete the N entries known to be present in the array. Entries had been inserted in random order, and are deleted in a different random order.
API used:
size_type erase(const key_type& k);
What can we conclude from these tests? Here are my observations:
-
Until it runs out of memory at 60M entries, Google's dense_hash_map is consistently the fastest, often by a quite significant margin.
-
Both Boost and g++ unordered_maps have very similar performance, which I would qualify as average amoung the alternatives tested.
-
Google's btree_map (from cpp-btree) does not perform very well on these tests (where the fact that it maintains the ordering of entries is not used). While it is competitive with the sparse_hash_map for insertion, the lookup time is typically at least 3 time higher than the slowest hash map, and deletion is slower as well. This is not unexpected as the btree complexity on insert, lookup and delete is O(log n).
-
Google's sparse_hash_map is very competitive, as fast as the std::unordered_maps on lookup, faster at deletion, but slower on insert. Considering its excellent memory usage characteristics, I would say it is the best compromise.
So, if we are looking for a non-ordered associative container on linux[^1], I think the two Google offerings are most attractive:
-
Google's dense_hash_map: extremely fast, very high memory requirement (unless the maximum numbers of entries is known in advance, and is not just a little bit greater than a power of two).
-
Google's sparse_hash_map: very memory efficient, fast lookup and deletion, however slower that std::unordered_map on insertion.
Introducing Sparsepp
At this point, I started wondering about the large speed difference between the sparse and dense hash_maps by Google. Could that performance gap be reduced somewhat? After all, both use open adressing with internal quadratic probing.
I was also intrigued by the remarkable sparse_hash_map memory efficiency, and wanted to fully understand its implementation, which is based on a sparsetable.
As I read the code and followed it under the debugger, I started having ideas on how to speed-up the sparse_hash_map, without significantly increasing the memory usage. That little game was addictive, and I found myself trying various ideas: some which provided significant benefits, and some that didn't pan out.
Regardless, after a few months of work on evenings and week-ends, I am proud to present Sparsepp, a heavily modified version of Google's sparse_hash_map which offers significant performance improvements, while maintaining a a very low memory profile.
The graphs below show the relative performance (purple line) of the Sparsepp sparse_hash_map compared to the other implementations:
Note: "Sparse++" in the graphs legend is actually "Sparsepp".
- Random Insert: Sparsepp, while still slower than the dense_hash_map, is significantly faster than the original sparse_hash_map and the btree_map, and as fast as the two std::unordered_map implementations.
- Random Lookup (find): Sparsepp is faster than all other alternatives, except for dense_hash_map.
- Delete (erase): Sparsepp is again doing very well, outperformed only by dense_hash_map. We should note that unlike the original sparse_hash_map, Sparsepp's sparse_hash_map does release the memory on erase, instead of just overwriting the memory with the deleted key value. Indeed, the non-standard APIs set_deleted_key() and set_empty_key(), while still present for compatibility with the original sparse_hash_map, are no longer necessary or useful.
Looks good, but what is the cost of using Sparsepp versus the original sparse_hash_map in memory usage:
Not bad! While Sparsepp memory usage is a little bit higher than the original sparse_hash_map, it is still memory friendly, and there are no memory spikes when the map resizes. We can see that when moving from 60M entries to 70M entries, both Google's dense and Sparsepp hash_maps needed a resize to accomodate the 70M elements. The resize proved fatal for the dense_hash_map, who could not allocate the 6GB needed for the resize + copy, while the Sparsepp sparse_hash_map had no problem.
In order to validate that the sparse hash tables can indeed grow to accomodate many more entries than regular hash tables, we decided to run a test that would gounsert items until all tables run out of memory, the result of which is presented in the two graphs below:
The table below display the maximum number of entries that could be added to each map before it ran out of memory. As a reminder, the VM had 5.7GB free before each test, and each entry is 16 bytes.
Max entries | Google's dense_hash | Boost unordered | g++ unordered | Google's btree_map | Sparsepp | Google's sparse_hash ------------ | -------------- | --------------- | -------------- | --------- | -------- | --------------- in millions | 60 M | 80 M | 120 M | 220 M | 220 M | 240 M
Both sparse hash implementations, as well as Google's btree_map are significantly more memory efficient than the classic unordered_maps. They are also significantly slower that Sparsepp.
If we are willing to sacrifice a little bit of insertion performance for improved memory efficiency, it is easily done with a simple change in Sparsepp header file sparsepp.h. Just change:
#define SPP_ALLOC_SZ 0
to
#define SPP_ALLOC_SZ 1
With this change, we get the graphs below:
Now the memory usage of Sparsepp is reduced to just a little bit more than Google's sparse_hash_map, and both sparse map implementations are able to insert 240 Million entries, but choke at 260 Million. Sparsepp is a little bit slower on insert, but still significantly faster than Google's sparse_hash_map. Lookup performance (not graphed) is unchanged.
To conclude, we feel that Sparsepp provides an unusual combination of performance and memory economy, and will be a useful addition to every developer toolkit.
Here are some other features of Sparsepp you may find attractive:
-
Single header implementation: the full Sparsepp resides in the single header file sparsepp.h. Just copy this file in your project, #include it, and you are good to go.
-
C++11 compatible: move semantics, cbegin()/cend(), stateful allocators
Benchmarks code
template <class T>
void _fill(vector<T> &v)
{
srand(1); // for a fair/deterministic comparison
for (size_t i = 0, sz = v.size(); i < sz; ++i)
v[i] = (T)(i * 10 + rand() % 10);
}
template <class T>
void _shuffle(vector<T> &v)
{
for (size_t n = v.size(); n >= 2; --n)
std::swap(v[n - 1], v[static_cast<unsigned>(rand()) % n]);
}
template <class T, class HT>
double _fill_random(vector<T> &v, HT &hash)
{
_fill<T>(v);
_shuffle<T>(v);
double start_time = get_time();
for (size_t i = 0, sz = v.size(); i < sz; ++i)
hash.insert(typename HT::value_type(v[i], 0));
return start_time;
}
template <class T, class HT>
double _lookup(vector<T> &v, HT &hash, size_t &num_present)
{
_fill_random(v, hash);
num_present = 0;
size_t max_val = v.size() * 10;
double start_time = get_time();
for (size_t i = 0, sz = v.size(); i < sz; ++i)
{
num_present += (size_t)(hash.find(v[i]) != hash.end());
num_present += (size_t)(hash.find((T)(rand() % max_val)) != hash.end());
}
return start_time;
}
template <class T, class HT>
double _delete(vector<T> &v, HT &hash)
{
_fill_random(v, hash);
_shuffle(v); // don't delete in insertion order
double start_time = get_time();
for(size_t i = 0, sz = v.size(); i < sz; ++i)
hash.erase(v[i]);
return start_time;
}
[^1]: Google's hash maps were most likely developed on linux/g++. When built on Windows with Visual Studio (2015), the lookup of items is very slow, to the point that the sparse hashtable is not much faster than Google's btree_map (from the cpp-btree library). The reason for this poor performance is that Google's implementation uses by default the hash functions provided by the compiler, and those provided by the Visual C++ compiler turn out to be very inefficient. If you are using Google's sparse_hash_map on Windows, you can look forward to an even greater performance increase when switching to Sparsepp.
Try the sparsepp package in your browser
Any scripts or data that you put into this service are public.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.