README.md
In DanOvando/sraplus: Run sraplus Assessments
sraplus
sraplus is a flexible assessment package developed for Ovando et
al. 2021 At
the most “data limited” end, the model approximates the behavior of
catch-msy, sampling from prior distributions to obtain parameter values
that given a catch history do not crash the population and satisfy
supplied priors on initial and final depletion. At the most data rich
end the model can be fit to an abundance index or catch-per-unit-effort
data, while incorporating priors on recent stock status based on
Fisheries Management Index (FMI) scores or swept-area ratio data.
Installing
This is an in-development package hosted on GitHub, so you will need to
do a few things to install it.
-
open R
-
If you don’t have the remotes package installed yet, run
install.packages("remotes")
You’ll need to be connected to the internet.
- Once
remotes has been installed, you can then install sraplus by
running
remotes::install_github("danovando/sraplus")
That’s probably going to ask you to install many other packages, agree
to the prompts.
Troubleshooting
Make sure you try the install with a fresh R session (go to
“Session>Restart R” to make sure)
If you run into an error, first off try updating your R packages. From
there….
If your version of R is lower than 4.0, you might want to consider
updating R itself. Updating from 3.51 to 3.52 shouldn’t be any hassle.
BIG WARNING THOUGH, updating from say R 3.1 to 3.5 is a major update,
and you’ll lose all your installed packages in the process. I recommend
following the instructions
here to deal
with that, but even with that fix it can take a while, so I don’t
recommend doing a major R update if you’re on a deadline. There are also
packages to help you with this process, specifically
installR for Windows
and updateR for Mac.
From there…
- On Windows, make sure you have the appropriate version of Rtools
installed (here)
- Make sure that you select the box that says something about
adding Rtools to the PATH variable
- See instructions
here
- On macOS, there might be some issues with the your compiler. If you
get an error that says something like
clang: error: unsupported option '-fopenmp', follow the
instructions
here
Once you’ve tried those, restart your computer and try running
install.packages("remotes")
remotes::install_github("danovando/sraplus")
Example Use
Once you’ve successfully installed sraplus you can take for a test
drive with these examples. We’ll now work through a couple examples,
from simple to complex, of using sraplus
First, load sraplus
library(sraplus)
“Catch-only” SIR model
For the first example we’ll use a sampling-importance-resampling (SIR)
algorithm with a “catch-only” version of the model. In this mode, we use
catch heuristics (in the manner of the @anderson2014 adaptation of
Catch-MSY). The catch-heuristics are if catch in the first year is less
than 70% of the maximum reported catch, we set an expectation of
depletion in the initial year of 70% of carrying capacity. Otherwise,
the expectation is 40% of carrying capacity. For final depletion, the
heuristic prior is if catch in the final year is greater than 50% of
maximum catch final depletion is assumed to be 60% of carrying capacity,
otherwise 40% of carrying capacity.
The first step in running sraplus is the sraplus::format_driors
(data and priors) function. In this case, we will use example data for
Atlantic cod (Gadus morhua) that is included in the sraplus package.
example_taxa <- "gadus morhua"
data(cod)
head(cod)
#> # A tibble: 6 × 56
#> stockid scien…¹ commo…² year catch stock…³ TBmsy…⁴ ERmsy…⁵ MSYbest TBmgt…⁶
#> <chr> <chr> <chr> <int> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 CODIIIaW… Gadus … Atlant… 1963 118000 Atlant… 971321. 0.455 267310. 436865.
#> 2 CODIIIaW… Gadus … Atlant… 1964 144000 Atlant… 971321. 0.455 267310. 436865.
#> 3 CODIIIaW… Gadus … Atlant… 1965 198000 Atlant… 971321. 0.455 267310. 436865.
#> 4 CODIIIaW… Gadus … Atlant… 1966 241000 Atlant… 971321. 0.455 267310. 436865.
#> 5 CODIIIaW… Gadus … Atlant… 1967 287000 Atlant… 971321. 0.455 267310. 436865.
#> 6 CODIIIaW… Gadus … Atlant… 1968 292000 Atlant… 971321. 0.455 267310. 436865.
#> # … with 46 more variables: ERmgtbest <dbl>, TBmsy <dbl>, SSBmsy <dbl>,
#> # Nmsy <dbl>, MSY <dbl>, Fmsy <dbl>, ERmsy <dbl>, TBmgt <dbl>, SSBmgt <dbl>,
#> # Fmgt <dbl>, ERmgt <dbl>, TB0 <dbl>, SSB0 <dbl>, M <dbl>, TBlim <dbl>,
#> # SSBlim <dbl>, Flim <dbl>, ERlim <dbl>, b_v_bmsy <dbl>, u_v_umsy <dbl>,
#> # exploitation_rate <dbl>, effort <dbl>, total_biomass <dbl>,
#> # ss_biomass <dbl>, tsn <chr>, areaid <chr>, stocklong.y <chr>, region <chr>,
#> # primary_country <chr>, primary_FAOarea <chr>, inmyersdb <chr>, …
From there, we’ll pass the catch data, and the years corresponding to
the catch data, to format_driors, and tell the model to use catch-msy
style heuristics by setting use_hueristics = TRUE. You’ll note that
sraplus prints a warning use_hueristics = TRUE reminding you that
any estimates of stock status are simply a transformation of your prior
beliefs expressed through the catch heuristics.
catch_only_driors <- format_driors(
taxa = example_taxa,
catch = cod$catch,
years = cod$year,
use_heuristics = TRUE
)
You can take a look at the information in the catch_only_driors object
by using sraplus::plot_driors
plot_driors(catch_only_driors)

From there, we pass the driors object to sraplus::fit_sraplus, and
plot the results using sraplus::plot_sraplus. The engine argument
specifies how the model will be fit. When not actually “fitting” to
anything (rather simply sampling from priors that don’t crash the
population), we recommend setting engine to “sir”. The draws argument
tells sraplus how many draws from the SIR algorithm to generate, and
n_keep how many draws to sample from the total draws iterations. So
in this case the SIR algorithm will run 1 million iterations, and sample
2000 entries from those million in proportion to their likelihood.
sfs <- purrr::safely(fit_sraplus)
catch_only_fit <- fit_sraplus(driors = catch_only_driors,
engine = "sir",
draws = 1e5,
n_keep = 4000,
estimate_proc_error = TRUE,
estimate_shape = TRUE,
max_time = Inf,
tune_prior_predictive = FALSE)
sraplus::plot_sraplus(catch_only = catch_only_fit)

Running fit_sraplus always produces a list with two objects: results
and fit. results is (mostly) standardized across engines set of
summary outputs from the fitted model. This allows us to easily plot and
compare outputs from models fit using sir, TMB, or stan. The fit
object contains the actual fitted model, which will of course vary
dramatically depending on what engine was used.
Let’s take a quick look at the results object.
head(catch_only_fit$results)
#> # A tibble: 6 × 6
#> year variable mean sd lower upper
#> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 1963 b_div_bmsy 0.616 0.0843 0.495 0.756
#> 2 1963 b 4606126. 4533220. 2208838. 8996789.
#> 3 1963 c_div_msy 0.312 0.101 0.107 0.461
#> 4 1963 crashed 0 0 0 0
#> 5 1963 depletion 0.402 0.0397 0.343 0.477
#> 6 1963 index_hat_t 222014. 255390. 13755. 546064.
results is organized as a dataframe tracking different variables over
years. mean is the mean value for a given variable, sd the estimated
standard deviation around the mean, and lower and upper being the
10th and 90th percentiles of the estimates.
You can access other variables from the raw fit object, though this is
not standardized by engine and so requires knowing how to for example
get outputs out of stanfit objects. In the catch_only_fit, the fit
object is the output of the SIR algorithm.
head(catch_only_fit$fit)
#> variable year draw value draw_id
#> 1 b_t 1963 1 2683442 21163
#> 2 b_t 1964 1 2810188 21163
#> 3 b_t 1965 1 2859159 21163
#> 4 b_t 1966 1 2993687 21163
#> 5 b_t 1967 1 2973050 21163
#> 6 b_t 1968 1 2887932 21163
From there, we can generate some standard plots of B/Bmsy (b_div_bmsy),
Catch/MSY, U/Umsy, and depletion over time using plot_sraplus.
sraplus::plot_sraplus(catch_only = catch_only_fit, years = catch_only_driors$years)

Fisheries Management Index and Swept Area Ratio
Now suppose that we obtain some FMI and SAR data for this fishery. We
can use these values to provide updated priors on current fishing
mortality rates and stock status (see full report for details on how
this is accomplished). Note that the FMI and SAR values year are
entirely fictional and any resemblance to any real fishery is purely
coincidental!
You’ll notice that we now add a few more options to format_driors. We’ll
manually set priors on initial depletion, with a prior of initial
biomass equal to carrying capacity (initial_state = 1), with a
standard deviation of 0.2. We’ll explicitly tell the model not to use
catch heuristics (though you don’t always need to specify this, FALSE is
the default). We’ll then pass the driors a swept area ratio of 2
(sar = 2), and a named vector of FMI scores (where FMI scores range
from 0 to 1). Note that FMI scores should be obtained through the formal
FMI survey process and not made up on the spot. W
fmi_sar_driors <- format_driors(
taxa = example_taxa,
catch = cod$catch,
years = cod$year,
initial_state = 1,
initial_state_cv = 0.25,
use_heuristics = FALSE,
sar = 10,
fmi = c("research" = 0.5, "management" = 0.5, "socioeconomics" = 0.5, 'enforcement' = 0.5),
sar_cv = NA,
use_b_reg = FALSE,
b_ref_type = "k")
# fmi_sar_driors <- format_driors(
# taxa = example_taxa,
# catch = cod$catch,
# years = cod$year,
# use_heuristics = FALSE,
# initial_state = NA,
# initial_state_cv = NA,
# b_ref_type = "k",
# use_catch_prior = TRUE
# )
#
sraplus::plot_driors(fmi_sar_driors)

We’ll then fit and plot our model. Note that you can pass multiple
sraplus fits, and can name each run whatever you would like.
fmi_sar_fit <- fit_sraplus(
driors = fmi_sar_driors,
engine = "sir",
draws = 1e6,
n_keep = 4000,
estimate_shape = TRUE,
estimate_proc_error = TRUE
)
plot_sraplus(fmi_sar = fmi_sar_fit,
catch_only = catch_only_fit)

You can also use the function sraplus::diagnose_sraplus to look at
some brief diagnostics of the model fit. Note that these diagnostics are
not exhaustive, and users should carefully assess the quality of any
model fits on their own as well. diagnose_sraplus will inform the user
whether FishLife found an exact match for the species, and provide
some summary diagnostics for each model type (SIR, TMB, or Stan). For
the SIR case, the diagnostics include the number of unique samples in
the posterior, and a plot of the mean terminal values as a function of
the number of unique samples used. n
sraplus::diagnose_sraplus(fit = fmi_sar_fit, driors = fmi_sar_driors )
#> $fishlife_match
#> [1] "fishlife matched supplied species"
#>
#> $distinct_sir_draws
#> [1] 2024
#>
#> $sir_convergence_plot

Abundance Index via Maximum Likelihood
We’ll now try adding in some actual data to fit to. For illustration
purposes (and since we’re no longer using FMI/SAR data which can’t
really be simulated), we’ll use a simulated fishery. Let’s start with a
very simple example,using a simple fishery simulator built into
sraplus.
set.seed(42)
sim <-
sraplus_simulator(
sigma_proc = 0.05,
sigma_u = 0,
q_slope = 0,
r = 0.4,
years = 25,
q = 1e-3,
m = 1.01,
init_u_umsy = 1
)
# sim$pop %>%
# dplyr::select(year, depletion,catch, effort,u) %>%
# gather(metric, value, -year) %>%
# ggplot(aes(year, value)) +
# geom_point() +
# facet_wrap(~metric, scales = "free_y") +
# labs(y = "Value", x = "Year") +
# sraplus::theme_sraplus()
Now, let’s pretend that we have a perfect index of abundance, which is
just biomass * 1e-3. We pass indices to sraplus inside
format_driors as index and index_years, where index_years is a
vector of the same length of index specifying which years index data
are available. Well now use Template Model Builder (TMB) to estimate
stock status based on this index of abundance. We’ll add in some priors
on the growth rate and the shape of the Pella-Tomlinson model (1.01
roughly corresponds to a Fox model, where Bmsy/K \~= 0.4). Note that we
now set engine = "tmb" to fit the model via maximum likelihood using
TMB.
index_driors <- format_driors(
catch = sim$pop$catch,
years = sim$pop$year,
index = sim$pop$biomass * 1e-3,
index_years = sim$pop$year,
initial_state = 1,
initial_state_cv = 0.005)
plot_driors(index_driors)

index_fit <- fit_sraplus(driors = index_driors,
engine = "tmb",
model = "sraplus_tmb",
estimate_proc_error = FALSE)
plot_sraplus(index = index_fit,years = index_driors$years)

plot_prior_posterior(index_fit, index_driors)

Looks good, now let’s try something a bit trickier.
Fit Bayesian CPUE model with stan
We’ll now simulate a fishery with random-walk effort dynamics,
increasing catchability, and process error.
set.seed(42)
sim <-
sraplus_simulator(
sigma_proc = 0.05,
sigma_u = 0.05,
q_slope = 0.025,
r = 0.2,
years = 25,
q = 1e-3,
m = 1.01,
init_u_umsy = 0.75
)
Now suppose we no longer have a perfect index of abundance, but instead
data on the catch and effort (CPUE!). But, there are a few problems with
these CPUE data. First, we know from the simulation that q is increasing
over time, so simply treating Catch/Effort as an index of abundance will
be biased (since a unit of effort in the past is not the same as a unit
of effort in the present). Second, we need to account for diminishing
returns from increasing amounts of effort, and in-season losses to
natural mortality. sraplus provides some support to these problems.
sraplus will estimate a q. If desired it allows the user to either
specify an assumed slope in catchability (where
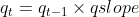 ),
or to attempt to estimate
),
or to attempt to estimate qslope directly. Second, given values of q
and qslope (and estimates of natural mortality either supplied by the
user or drawn from FishLife), sraplus uses the Baranov equation to
translate effort into an effective fishing mortality rate.
One important note. By default, sraplus includes estimation of
process error. When running a simplified CPUE like this, the model can’t
really handle estimating both process error and a q_slope_prior (since
the persistent trend in the CPUE values caused by the qslope can be
soaked into the process error or the qslope). So, you need to provide a
VERY imformative prior on the q_slope_prior parameter if you’re going to
try and estimate (i.e. fix the q_slope_prior parameter), or turn off
process error (inside fit_sraplus set estimate_proc_error = FALSE)
(the recommended option in this case).
By now the order of operations should be pretty familiar: pass things to
driors, then driors to fit_sraplus. In this case, instead of passing an
index, we pass effort data, and effort years.
Just to explore functionality of sraplus, we’ll fit the model using
Bayesian estimation through stan (engine = "stan"). We’ll compare two
versions, one trying to estimate qslope, and one not. Note that we can
pass standard rstan options to fit_sraplus.
cpue_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0,
q_slope_prior_cv = 0.2)
cpue_fit <- fit_sraplus(driors = cpue_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = FALSE)
cpue_qslope_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0.025,
q_slope_prior_cv = 0.05)
cpue_qslope_fit <- fit_sraplus(driors = cpue_qslope_driors,
engine = "stan",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 4,
cores = 4,
estimate_qslope = TRUE,
estimate_proc_error = FALSE,
non_centered = FALSE)
plot_sraplus(`CPUE fit no qslope` = cpue_fit, `CPUE fit with qslope` = cpue_qslope_fit)

As a final step, we can try adding in some fictional SAR data to our
fake fishery, just to see how it works. We can weight the SAR data using
the sar_cv input. Leaving sar_cv = NA uses the srandard deviation
from the posterior predictive of the fitted relationahip between SAR and
U/Umsy contained in the model. In other words, setting sar_cv = NA
lets the data tell you how much weight to assign to the SAR data. You
can however overwrite this if desired and pass a stronger weight to the
SAR data if desired.
cpue_sar_qslope_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0.025,
q_slope_prior_cv = 0.25,
f_ref_type = "f",
sar = 2,
sar_cv = 0.1)
cpue_sar_qslope_fit <- fit_sraplus(driors = cpue_sar_qslope_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = TRUE,
estimate_proc_error = FALSE)
plot_sraplus(cpue_sar_qslope_fit)

And for good measure one more with SAR data and process error instead of
qslope
cpue_sar_proc_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0,
q_slope_prior_cv = 0.25,
sar = 4,
sar_cv = .05,
f_ref_type = "f")
cpue_sar_proc_fit <- fit_sraplus(driors = cpue_sar_proc_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = FALSE,
estimate_proc_error = TRUE)
plot_sraplus(`no process error and no qslope ` = cpue_fit,
`no process error with qslope` = cpue_qslope_fit,
`no process error with qslope and sar` = cpue_sar_qslope_fit,
`process error and sar` = cpue_sar_proc_fit)

You can also produce Kobe plots by simply setting kobe = TRUE in
plot_sralpus
plot_sraplus(`no process error and no qslope ` = cpue_fit,
`no process error with qslope` = cpue_qslope_fit,
`no process error with qslope and sar` = cpue_sar_qslope_fit,
`process error and sar` = cpue_sar_proc_fit,
kobe = TRUE)

We can also use several built-in processing functions to display and
store the results
plot_prior_posterior displays the prior and posterior distributions
for selected parameters
plot_prior_posterior(cpue_sar_proc_fit, cpue_sar_proc_driors)

We can plot a summary of the most recent status estimates, along with
key outcomes such as MSY
summarize_sralpus(cpue_sar_proc_fit, output = "plot")

Or produce a summary table that can be saved to a .csv file.
knitr::kable(summarize_sralpus(cpue_sar_proc_fit, output = "table"), digits = 2)
| variable | mean | sd | lower | upper | year |
|:----------------|-------:|------:|-------:|-------:|-----:|
| sigma_proc | 0.22 | 0.04 | 0.16 | 0.29 | 1 |
| sigma_obs | 0.22 | 0.04 | 0.16 | 0.29 | 1 |
| log_sigma_ratio | 0.00 | 0.01 | -0.02 | 0.02 | 1 |
| sigma_ratio | 1.00 | 0.01 | 0.98 | 1.02 | 1 |
| log_ihat | 4.19 | 0.05 | 4.11 | 4.27 | 25 |
| log_b_div_bmsy | -1.03 | 0.15 | -1.28 | -0.79 | 25 |
| log_b | 4.19 | 0.05 | 4.11 | 4.27 | 25 |
| log_depletion | -2.03 | 0.15 | -2.27 | -1.78 | 25 |
| log_u_div_umsy | 0.89 | 0.17 | 0.61 | 1.16 | 25 |
| log_c_div_msy | -0.15 | 0.09 | -0.29 | -0.01 | 25 |
| u_t | 1.14 | 0.06 | 1.05 | 1.23 | 25 |
| proc_errors | 0.67 | 0.13 | 0.45 | 0.88 | 24 |
| plim | 0.05 | 0.00 | 0.05 | 0.05 | 1 |
| b_to_k | 0.37 | 0.00 | 0.37 | 0.37 | 1 |
| crashed | 0.00 | 0.00 | 0.00 | 0.00 | 1 |
| index_hat_t | 66.00 | 3.35 | 60.65 | 71.36 | 25 |
| r | 0.48 | 0.08 | 0.35 | 0.60 | 1 |
| m | 1.01 | 0.00 | 1.01 | 1.01 | 1 |
| msy | 87.16 | 7.60 | 75.01 | 99.30 | 1 |
| umsy | 0.47 | 0.08 | 0.35 | 0.59 | 1 |
| k | 501.06 | 71.18 | 387.29 | 614.82 | 1 |
| q_t | 0.01 | 0.00 | 0.00 | 0.01 | 25 |
| q_slope | 0.00 | 0.00 | 0.00 | 0.00 | 1 |
| sigma_ratio | 1.00 | 0.01 | 0.98 | 1.02 | 1 |
| ihat | 66.00 | 0.05 | 60.86 | 71.58 | 25 |
| b_div_bmsy | 0.36 | 0.15 | 0.28 | 0.45 | 25 |
| b | 66.00 | 0.05 | 60.86 | 71.58 | 25 |
| depletion | 0.13 | 0.15 | 0.10 | 0.17 | 25 |
| u_div_umsy | 2.43 | 0.17 | 1.85 | 3.18 | 25 |
| c_div_msy | 0.86 | 0.09 | 0.75 | 0.99 | 25 |
Implementing References
Ovando, D., Hilborn, R., Monnahan, C., Rudd, M., Sharma, R., Thorson,
J.T., Rousseau, Y., Ye, Y., 2021. Improving estimates of the state of
global fisheries depends on better data. Fish and Fisheries n/a.
https://doi.org/10.1111/faf.12593
Important Note on Building the Package
This package uses the TMBtools
package. If you make modifications to the core model in
src/TMB/sraplus_tmb.hpp, you need to run TMBtools::export_models()
prior to building the package in order for your changes to be reflected.
DanOvando/sraplus documentation built on July 22, 2023, 12:03 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
sraplus
sraplus is a flexible assessment package developed for Ovando et
al. 2021 At
the most “data limited” end, the model approximates the behavior of
catch-msy, sampling from prior distributions to obtain parameter values
that given a catch history do not crash the population and satisfy
supplied priors on initial and final depletion. At the most data rich
end the model can be fit to an abundance index or catch-per-unit-effort
data, while incorporating priors on recent stock status based on
Fisheries Management Index (FMI) scores or swept-area ratio data.
Installing
This is an in-development package hosted on GitHub, so you will need to do a few things to install it.
-
open R
-
If you don’t have the
remotespackage installed yet, run
install.packages("remotes")
You’ll need to be connected to the internet.
- Once
remoteshas been installed, you can then installsraplusby running
remotes::install_github("danovando/sraplus")
That’s probably going to ask you to install many other packages, agree to the prompts.
Troubleshooting
Make sure you try the install with a fresh R session (go to “Session>Restart R” to make sure)
If you run into an error, first off try updating your R packages. From there….
If your version of R is lower than 4.0, you might want to consider
updating R itself. Updating from 3.51 to 3.52 shouldn’t be any hassle.
BIG WARNING THOUGH, updating from say R 3.1 to 3.5 is a major update,
and you’ll lose all your installed packages in the process. I recommend
following the instructions
here to deal
with that, but even with that fix it can take a while, so I don’t
recommend doing a major R update if you’re on a deadline. There are also
packages to help you with this process, specifically
installR for Windows
and updateR for Mac.
From there…
- On Windows, make sure you have the appropriate version of Rtools
installed (here)
- Make sure that you select the box that says something about adding Rtools to the PATH variable
- See instructions here
- On macOS, there might be some issues with the your compiler. If you
get an error that says something like
clang: error: unsupported option '-fopenmp', follow the instructions here
Once you’ve tried those, restart your computer and try running
install.packages("remotes")
remotes::install_github("danovando/sraplus")
Example Use
Once you’ve successfully installed sraplus you can take for a test
drive with these examples. We’ll now work through a couple examples,
from simple to complex, of using sraplus
First, load sraplus
library(sraplus)
“Catch-only” SIR model
For the first example we’ll use a sampling-importance-resampling (SIR) algorithm with a “catch-only” version of the model. In this mode, we use catch heuristics (in the manner of the @anderson2014 adaptation of Catch-MSY). The catch-heuristics are if catch in the first year is less than 70% of the maximum reported catch, we set an expectation of depletion in the initial year of 70% of carrying capacity. Otherwise, the expectation is 40% of carrying capacity. For final depletion, the heuristic prior is if catch in the final year is greater than 50% of maximum catch final depletion is assumed to be 60% of carrying capacity, otherwise 40% of carrying capacity.
The first step in running sraplus is the sraplus::format_driors
(data and priors) function. In this case, we will use example data for
Atlantic cod (Gadus morhua) that is included in the sraplus package.
example_taxa <- "gadus morhua"
data(cod)
head(cod)
#> # A tibble: 6 × 56
#> stockid scien…¹ commo…² year catch stock…³ TBmsy…⁴ ERmsy…⁵ MSYbest TBmgt…⁶
#> <chr> <chr> <chr> <int> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 CODIIIaW… Gadus … Atlant… 1963 118000 Atlant… 971321. 0.455 267310. 436865.
#> 2 CODIIIaW… Gadus … Atlant… 1964 144000 Atlant… 971321. 0.455 267310. 436865.
#> 3 CODIIIaW… Gadus … Atlant… 1965 198000 Atlant… 971321. 0.455 267310. 436865.
#> 4 CODIIIaW… Gadus … Atlant… 1966 241000 Atlant… 971321. 0.455 267310. 436865.
#> 5 CODIIIaW… Gadus … Atlant… 1967 287000 Atlant… 971321. 0.455 267310. 436865.
#> 6 CODIIIaW… Gadus … Atlant… 1968 292000 Atlant… 971321. 0.455 267310. 436865.
#> # … with 46 more variables: ERmgtbest <dbl>, TBmsy <dbl>, SSBmsy <dbl>,
#> # Nmsy <dbl>, MSY <dbl>, Fmsy <dbl>, ERmsy <dbl>, TBmgt <dbl>, SSBmgt <dbl>,
#> # Fmgt <dbl>, ERmgt <dbl>, TB0 <dbl>, SSB0 <dbl>, M <dbl>, TBlim <dbl>,
#> # SSBlim <dbl>, Flim <dbl>, ERlim <dbl>, b_v_bmsy <dbl>, u_v_umsy <dbl>,
#> # exploitation_rate <dbl>, effort <dbl>, total_biomass <dbl>,
#> # ss_biomass <dbl>, tsn <chr>, areaid <chr>, stocklong.y <chr>, region <chr>,
#> # primary_country <chr>, primary_FAOarea <chr>, inmyersdb <chr>, …
From there, we’ll pass the catch data, and the years corresponding to
the catch data, to format_driors, and tell the model to use catch-msy
style heuristics by setting use_hueristics = TRUE. You’ll note that
sraplus prints a warning use_hueristics = TRUE reminding you that
any estimates of stock status are simply a transformation of your prior
beliefs expressed through the catch heuristics.
catch_only_driors <- format_driors(
taxa = example_taxa,
catch = cod$catch,
years = cod$year,
use_heuristics = TRUE
)
You can take a look at the information in the catch_only_driors object
by using sraplus::plot_driors
plot_driors(catch_only_driors)
From there, we pass the driors object to sraplus::fit_sraplus, and
plot the results using sraplus::plot_sraplus. The engine argument
specifies how the model will be fit. When not actually “fitting” to
anything (rather simply sampling from priors that don’t crash the
population), we recommend setting engine to “sir”. The draws argument
tells sraplus how many draws from the SIR algorithm to generate, and
n_keep how many draws to sample from the total draws iterations. So
in this case the SIR algorithm will run 1 million iterations, and sample
2000 entries from those million in proportion to their likelihood.
sfs <- purrr::safely(fit_sraplus)
catch_only_fit <- fit_sraplus(driors = catch_only_driors,
engine = "sir",
draws = 1e5,
n_keep = 4000,
estimate_proc_error = TRUE,
estimate_shape = TRUE,
max_time = Inf,
tune_prior_predictive = FALSE)
sraplus::plot_sraplus(catch_only = catch_only_fit)
Running fit_sraplus always produces a list with two objects: results
and fit. results is (mostly) standardized across engines set of
summary outputs from the fitted model. This allows us to easily plot and
compare outputs from models fit using sir, TMB, or stan. The fit
object contains the actual fitted model, which will of course vary
dramatically depending on what engine was used.
Let’s take a quick look at the results object.
head(catch_only_fit$results)
#> # A tibble: 6 × 6
#> year variable mean sd lower upper
#> <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 1963 b_div_bmsy 0.616 0.0843 0.495 0.756
#> 2 1963 b 4606126. 4533220. 2208838. 8996789.
#> 3 1963 c_div_msy 0.312 0.101 0.107 0.461
#> 4 1963 crashed 0 0 0 0
#> 5 1963 depletion 0.402 0.0397 0.343 0.477
#> 6 1963 index_hat_t 222014. 255390. 13755. 546064.
results is organized as a dataframe tracking different variables over
years. mean is the mean value for a given variable, sd the estimated
standard deviation around the mean, and lower and upper being the
10th and 90th percentiles of the estimates.
You can access other variables from the raw fit object, though this is
not standardized by engine and so requires knowing how to for example
get outputs out of stanfit objects. In the catch_only_fit, the fit
object is the output of the SIR algorithm.
head(catch_only_fit$fit)
#> variable year draw value draw_id
#> 1 b_t 1963 1 2683442 21163
#> 2 b_t 1964 1 2810188 21163
#> 3 b_t 1965 1 2859159 21163
#> 4 b_t 1966 1 2993687 21163
#> 5 b_t 1967 1 2973050 21163
#> 6 b_t 1968 1 2887932 21163
From there, we can generate some standard plots of B/Bmsy (b_div_bmsy),
Catch/MSY, U/Umsy, and depletion over time using plot_sraplus.
sraplus::plot_sraplus(catch_only = catch_only_fit, years = catch_only_driors$years)
Fisheries Management Index and Swept Area Ratio
Now suppose that we obtain some FMI and SAR data for this fishery. We can use these values to provide updated priors on current fishing mortality rates and stock status (see full report for details on how this is accomplished). Note that the FMI and SAR values year are entirely fictional and any resemblance to any real fishery is purely coincidental!
You’ll notice that we now add a few more options to format_driors. We’ll
manually set priors on initial depletion, with a prior of initial
biomass equal to carrying capacity (initial_state = 1), with a
standard deviation of 0.2. We’ll explicitly tell the model not to use
catch heuristics (though you don’t always need to specify this, FALSE is
the default). We’ll then pass the driors a swept area ratio of 2
(sar = 2), and a named vector of FMI scores (where FMI scores range
from 0 to 1). Note that FMI scores should be obtained through the formal
FMI survey process and not made up on the spot. W
fmi_sar_driors <- format_driors(
taxa = example_taxa,
catch = cod$catch,
years = cod$year,
initial_state = 1,
initial_state_cv = 0.25,
use_heuristics = FALSE,
sar = 10,
fmi = c("research" = 0.5, "management" = 0.5, "socioeconomics" = 0.5, 'enforcement' = 0.5),
sar_cv = NA,
use_b_reg = FALSE,
b_ref_type = "k")
# fmi_sar_driors <- format_driors(
# taxa = example_taxa,
# catch = cod$catch,
# years = cod$year,
# use_heuristics = FALSE,
# initial_state = NA,
# initial_state_cv = NA,
# b_ref_type = "k",
# use_catch_prior = TRUE
# )
#
sraplus::plot_driors(fmi_sar_driors)
We’ll then fit and plot our model. Note that you can pass multiple
sraplus fits, and can name each run whatever you would like.
fmi_sar_fit <- fit_sraplus(
driors = fmi_sar_driors,
engine = "sir",
draws = 1e6,
n_keep = 4000,
estimate_shape = TRUE,
estimate_proc_error = TRUE
)
plot_sraplus(fmi_sar = fmi_sar_fit,
catch_only = catch_only_fit)
You can also use the function sraplus::diagnose_sraplus to look at
some brief diagnostics of the model fit. Note that these diagnostics are
not exhaustive, and users should carefully assess the quality of any
model fits on their own as well. diagnose_sraplus will inform the user
whether FishLife found an exact match for the species, and provide
some summary diagnostics for each model type (SIR, TMB, or Stan). For
the SIR case, the diagnostics include the number of unique samples in
the posterior, and a plot of the mean terminal values as a function of
the number of unique samples used. n
sraplus::diagnose_sraplus(fit = fmi_sar_fit, driors = fmi_sar_driors )
#> $fishlife_match
#> [1] "fishlife matched supplied species"
#>
#> $distinct_sir_draws
#> [1] 2024
#>
#> $sir_convergence_plot
Abundance Index via Maximum Likelihood
We’ll now try adding in some actual data to fit to. For illustration
purposes (and since we’re no longer using FMI/SAR data which can’t
really be simulated), we’ll use a simulated fishery. Let’s start with a
very simple example,using a simple fishery simulator built into
sraplus.
set.seed(42)
sim <-
sraplus_simulator(
sigma_proc = 0.05,
sigma_u = 0,
q_slope = 0,
r = 0.4,
years = 25,
q = 1e-3,
m = 1.01,
init_u_umsy = 1
)
# sim$pop %>%
# dplyr::select(year, depletion,catch, effort,u) %>%
# gather(metric, value, -year) %>%
# ggplot(aes(year, value)) +
# geom_point() +
# facet_wrap(~metric, scales = "free_y") +
# labs(y = "Value", x = "Year") +
# sraplus::theme_sraplus()
Now, let’s pretend that we have a perfect index of abundance, which is
just biomass * 1e-3. We pass indices to sraplus inside
format_driors as index and index_years, where index_years is a
vector of the same length of index specifying which years index data
are available. Well now use Template Model Builder (TMB) to estimate
stock status based on this index of abundance. We’ll add in some priors
on the growth rate and the shape of the Pella-Tomlinson model (1.01
roughly corresponds to a Fox model, where Bmsy/K \~= 0.4). Note that we
now set engine = "tmb" to fit the model via maximum likelihood using
TMB.
index_driors <- format_driors(
catch = sim$pop$catch,
years = sim$pop$year,
index = sim$pop$biomass * 1e-3,
index_years = sim$pop$year,
initial_state = 1,
initial_state_cv = 0.005)
plot_driors(index_driors)
index_fit <- fit_sraplus(driors = index_driors,
engine = "tmb",
model = "sraplus_tmb",
estimate_proc_error = FALSE)
plot_sraplus(index = index_fit,years = index_driors$years)
plot_prior_posterior(index_fit, index_driors)
Looks good, now let’s try something a bit trickier.
Fit Bayesian CPUE model with stan
We’ll now simulate a fishery with random-walk effort dynamics, increasing catchability, and process error.
set.seed(42)
sim <-
sraplus_simulator(
sigma_proc = 0.05,
sigma_u = 0.05,
q_slope = 0.025,
r = 0.2,
years = 25,
q = 1e-3,
m = 1.01,
init_u_umsy = 0.75
)
Now suppose we no longer have a perfect index of abundance, but instead
data on the catch and effort (CPUE!). But, there are a few problems with
these CPUE data. First, we know from the simulation that q is increasing
over time, so simply treating Catch/Effort as an index of abundance will
be biased (since a unit of effort in the past is not the same as a unit
of effort in the present). Second, we need to account for diminishing
returns from increasing amounts of effort, and in-season losses to
natural mortality. sraplus provides some support to these problems.
sraplus will estimate a q. If desired it allows the user to either
specify an assumed slope in catchability (where
),
or to attempt to estimate
qslope directly. Second, given values of q
and qslope (and estimates of natural mortality either supplied by the
user or drawn from FishLife), sraplus uses the Baranov equation to
translate effort into an effective fishing mortality rate.
One important note. By default, sraplus includes estimation of
process error. When running a simplified CPUE like this, the model can’t
really handle estimating both process error and a q_slope_prior (since
the persistent trend in the CPUE values caused by the qslope can be
soaked into the process error or the qslope). So, you need to provide a
VERY imformative prior on the q_slope_prior parameter if you’re going to
try and estimate (i.e. fix the q_slope_prior parameter), or turn off
process error (inside fit_sraplus set estimate_proc_error = FALSE)
(the recommended option in this case).
By now the order of operations should be pretty familiar: pass things to driors, then driors to fit_sraplus. In this case, instead of passing an index, we pass effort data, and effort years.
Just to explore functionality of sraplus, we’ll fit the model using
Bayesian estimation through stan (engine = "stan"). We’ll compare two
versions, one trying to estimate qslope, and one not. Note that we can
pass standard rstan options to fit_sraplus.
cpue_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0,
q_slope_prior_cv = 0.2)
cpue_fit <- fit_sraplus(driors = cpue_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = FALSE)
cpue_qslope_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0.025,
q_slope_prior_cv = 0.05)
cpue_qslope_fit <- fit_sraplus(driors = cpue_qslope_driors,
engine = "stan",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 4,
cores = 4,
estimate_qslope = TRUE,
estimate_proc_error = FALSE,
non_centered = FALSE)
plot_sraplus(`CPUE fit no qslope` = cpue_fit, `CPUE fit with qslope` = cpue_qslope_fit)
As a final step, we can try adding in some fictional SAR data to our
fake fishery, just to see how it works. We can weight the SAR data using
the sar_cv input. Leaving sar_cv = NA uses the srandard deviation
from the posterior predictive of the fitted relationahip between SAR and
U/Umsy contained in the model. In other words, setting sar_cv = NA
lets the data tell you how much weight to assign to the SAR data. You
can however overwrite this if desired and pass a stronger weight to the
SAR data if desired.
cpue_sar_qslope_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0.025,
q_slope_prior_cv = 0.25,
f_ref_type = "f",
sar = 2,
sar_cv = 0.1)
cpue_sar_qslope_fit <- fit_sraplus(driors = cpue_sar_qslope_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = TRUE,
estimate_proc_error = FALSE)
plot_sraplus(cpue_sar_qslope_fit)
And for good measure one more with SAR data and process error instead of qslope
cpue_sar_proc_driors <- format_driors(taxa = example_taxa,
catch = sim$pop$catch,
years = sim$pop$year,
effort = sim$pop$effort,
effort_years = sim$pop$year,
shape_prior = 1.01,
q_slope_prior = 0,
q_slope_prior_cv = 0.25,
sar = 4,
sar_cv = .05,
f_ref_type = "f")
cpue_sar_proc_fit <- fit_sraplus(driors = cpue_sar_proc_driors,
engine = "tmb",
model = "sraplus_tmb",
adapt_delta = 0.9,
max_treedepth = 10,
n_keep = 2000,
chains = 1,
cores = 1,
estimate_qslope = FALSE,
estimate_proc_error = TRUE)
plot_sraplus(`no process error and no qslope ` = cpue_fit,
`no process error with qslope` = cpue_qslope_fit,
`no process error with qslope and sar` = cpue_sar_qslope_fit,
`process error and sar` = cpue_sar_proc_fit)
You can also produce Kobe plots by simply setting kobe = TRUE in
plot_sralpus
plot_sraplus(`no process error and no qslope ` = cpue_fit,
`no process error with qslope` = cpue_qslope_fit,
`no process error with qslope and sar` = cpue_sar_qslope_fit,
`process error and sar` = cpue_sar_proc_fit,
kobe = TRUE)
We can also use several built-in processing functions to display and store the results
plot_prior_posterior displays the prior and posterior distributions
for selected parameters
plot_prior_posterior(cpue_sar_proc_fit, cpue_sar_proc_driors)
We can plot a summary of the most recent status estimates, along with key outcomes such as MSY
summarize_sralpus(cpue_sar_proc_fit, output = "plot")
Or produce a summary table that can be saved to a .csv file.
knitr::kable(summarize_sralpus(cpue_sar_proc_fit, output = "table"), digits = 2)
| variable | mean | sd | lower | upper | year | |:----------------|-------:|------:|-------:|-------:|-----:| | sigma_proc | 0.22 | 0.04 | 0.16 | 0.29 | 1 | | sigma_obs | 0.22 | 0.04 | 0.16 | 0.29 | 1 | | log_sigma_ratio | 0.00 | 0.01 | -0.02 | 0.02 | 1 | | sigma_ratio | 1.00 | 0.01 | 0.98 | 1.02 | 1 | | log_ihat | 4.19 | 0.05 | 4.11 | 4.27 | 25 | | log_b_div_bmsy | -1.03 | 0.15 | -1.28 | -0.79 | 25 | | log_b | 4.19 | 0.05 | 4.11 | 4.27 | 25 | | log_depletion | -2.03 | 0.15 | -2.27 | -1.78 | 25 | | log_u_div_umsy | 0.89 | 0.17 | 0.61 | 1.16 | 25 | | log_c_div_msy | -0.15 | 0.09 | -0.29 | -0.01 | 25 | | u_t | 1.14 | 0.06 | 1.05 | 1.23 | 25 | | proc_errors | 0.67 | 0.13 | 0.45 | 0.88 | 24 | | plim | 0.05 | 0.00 | 0.05 | 0.05 | 1 | | b_to_k | 0.37 | 0.00 | 0.37 | 0.37 | 1 | | crashed | 0.00 | 0.00 | 0.00 | 0.00 | 1 | | index_hat_t | 66.00 | 3.35 | 60.65 | 71.36 | 25 | | r | 0.48 | 0.08 | 0.35 | 0.60 | 1 | | m | 1.01 | 0.00 | 1.01 | 1.01 | 1 | | msy | 87.16 | 7.60 | 75.01 | 99.30 | 1 | | umsy | 0.47 | 0.08 | 0.35 | 0.59 | 1 | | k | 501.06 | 71.18 | 387.29 | 614.82 | 1 | | q_t | 0.01 | 0.00 | 0.00 | 0.01 | 25 | | q_slope | 0.00 | 0.00 | 0.00 | 0.00 | 1 | | sigma_ratio | 1.00 | 0.01 | 0.98 | 1.02 | 1 | | ihat | 66.00 | 0.05 | 60.86 | 71.58 | 25 | | b_div_bmsy | 0.36 | 0.15 | 0.28 | 0.45 | 25 | | b | 66.00 | 0.05 | 60.86 | 71.58 | 25 | | depletion | 0.13 | 0.15 | 0.10 | 0.17 | 25 | | u_div_umsy | 2.43 | 0.17 | 1.85 | 3.18 | 25 | | c_div_msy | 0.86 | 0.09 | 0.75 | 0.99 | 25 |
Implementing References
Ovando, D., Hilborn, R., Monnahan, C., Rudd, M., Sharma, R., Thorson, J.T., Rousseau, Y., Ye, Y., 2021. Improving estimates of the state of global fisheries depends on better data. Fish and Fisheries n/a. https://doi.org/10.1111/faf.12593
Important Note on Building the Package
This package uses the TMBtools
package. If you make modifications to the core model in
src/TMB/sraplus_tmb.hpp, you need to run TMBtools::export_models()
prior to building the package in order for your changes to be reflected.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.