README.md
In boyuren158/DirFactor: Dependent Dirichlet processes factor model for nonparametric ordination fo microbiome data
Dependent Dirichlet processes factor model for nonparametric ordination in Microbiome data (DirFactor)
Boyu Ren
2016-12-22
- Introduction
- How To Run
- Simulation studies for DirFactor
- Estimate the normalized Gram matrix between biological samples using DirFactor
- Shrink the dimension of the latent factros towards the correct dimension
- Borrowing information can increase the accuracy of the estimated probabilities of species
- Ordination with credible regions recover the clustering structure
- Two applications of DirFactor
- References
Introduction
Human microbiome studies use sequencing technologies to measure the abundance of bacterial species or Operational Taxonomic Units (OTUs) in samples of biological material. Typically the data are organized in contingency tables with OTU counts across heterogeneous biological samples. In the microbial ecology community, ordination methods are frequently used to investigate latent factors or clusters that capture and describe variations of OTU counts across biologi- cal samples. It remains important to evaluate how uncertainty in estimates of each biological sample’s microbial distribution propagates to ordination analyses, including visualization of clusters and projections of biological samples on low dimensional spaces.
We propose a Bayesian analysis for dependent distributions to endow frequently used ordinations with estimates of uncertainty. A Bayesian nonparametric prior for dependent normalized random measures is constructed, which is marginally equivalent to the normalized generalized Gamma process, a well-known prior for nonparametric analyses. In our prior the dependence and similarity between microbial distributions is represented by latent factors that concentrate in a low dimensional space. We use a shrinkage prior to tune the dimensionality of the latent factors. The resulting posterior samples of model parameters can be used to evaluate uncertainty in analyses routinely applied in microbiome studies. Specifically, by combining them with multivariate data analysis techniques we can visualize credible regions in ecological ordination plots.
How To Run
Loading
We first need to load the package:
library(DirFactor)
Package Features
The DirFactor package contains six functions:
DirFactor, the main function for running Gibbs sampler on an OTU table.ConvDiagnosis, the diagnosis function to check if the posterior simulation mixed.PlotStatis, the plotting function to visualize nonparametric ordination results as well as its uncertainty given by the DirFactor model.SimDirFactorBlock, SimDirFactorSym,SimDirFactorContour, three related functions used to generate synthetic datasets considered in the simulation studies in (Ren et al. 2016).
Data and Prior Input
For a full and complete description of the possible parameters for DirFactor, their default values, and the output, see
?DirFactor
Required Input
There are two required input for running DirFactor. A data matrix stores the OTU table of species abundance in each biological sample, where biological samples are be in columns and species in rows. A list hyper contains the values of the hyper-parameters of priors. By default, the starting values of the model parameters will be generated from the priors. Below is a minimal example for DirFactor. We use SimDirFactorBlock to simulate a synthetic dataset with 22 biological samples and 68 species with total counts per sample being 106. The true Gram matrix between samples is a block-diagonal matrix with two blocks, which is induced by three latent factors. When running the MCMC, we specify the number of factors to be 10. DirFactor by default save the MCMC results in an temporary path and it will return the path once finished.
library(DirFactor)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
sim.data = SimDirFactorBlock( 1e6, n = 22, p = 68, m = 3, hyper )
mcmc.out = DirFactor( sim.data$data[[1]], hyper )
Simulation studies for DirFactor
We use the code for the simulation studies in (Ren et al. 2016) to illustrate how to use DirFactor in general.
Estimate the normalized Gram matrix between biological samples using DirFactor
Starting at this subsection, we will reproduce the simulation results in (Ren et al. 2016). We first want to check if the procedure can recover the normalized Gram matrix between biological samples accurately. We have already finished the MCMC simulation for 50 replicates on simulated datasets generated by SimDirFactorBlock when the model is correctly specified (a=2) and misspecified (a=1). We also consider the case when the dimensions of true latent factors are 3, 6 and 9 as well as when the total counts per biological sample is 103, 104 and 105. The code below will generate n.rep number of simulation datasets and run them in n.rep cores in parallel. Please make sure your platform has n.rep number of cores available. The MCMC results for the ith simulation will be saved in the subfolder run_i/ under current directory and the truth for the simulation will be saved in truth_i as an RDS object.
library( DirFactor )
# Simulating data and run mcmc for all different scenarios
# Each scenario will be repeated n.rep times
RunSimulation = function( n.rep, n.factor, hyper, a = 2, ... ){
library( snowfall )
# Parallelization, change cpus=50 to reasonable number if running locally
sfInit( parallel=TRUE, cpus=n.rep )
sfLibrary(DirFactor)
sfExport( "hyper" )
# save the simulated parameters to truth_i
# save the mcmc results to run_i/sim_j
sfLapply( 1:n.rep, function(x){
sim.data = SimDirFactorBlock( c(1000,10000,100000), n = 22, p = 68,
m = 3, hyper = hyper, K = 2, a = a )
dir.create( paste( "run_", x, sep = "" ), showWarnings = FALSE )
saveRDS( sim.data, paste( "truth", x, sep = "_" ) )
for( id in 1:length( sim.data$data ) ){
#create the folder to save the MCMC results
dat.ind = sim.data$data[[id]]
DirFactor( dat.ind, hyper,
save.path = paste("run_", x, "/sim_", id, sep = "" ),
... )
}
})
sfStop()
}
# Summarize mcmc results
SummarizeMCMC = function( n.rep, start, end, thin ){
lapply( 1:n.rep, function(x){
tru.res = readRDS(paste("truth", x, sep = "_"))
mcmc.res = lapply( 1:3, function(i)
lapply( paste(paste("run_", x, "/sim_", i, sep = ""),
seq( start, end, thin ), sep = "_"), readRDS ) )
list( truth = tru.res, mcmc = mcmc.res )
})
}
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
# dim(factor) = 3
# correctly specified
RunSimulation( n.rep = 50, n.factor = 3, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.3 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 3, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50, step = 5e4, step.disp = 1e3 )
factor.3.mis = SummarizeMCMC(50, 10050, 5e4, 50)
# dim(factor) = 6
# correctly specified
RunSimulation( n.rep = 50, n.factor = 6, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.6 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 6, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50,step = 5e4, step.disp = 1e3 )
factor.6.mis = SummarizeMCMC(50, 10050, 5e4, 50)
#dim(factor) = 9
# correctly specified
RunSimulation( n.rep = 50, n.factor = 9, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.9 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 9, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50,step = 5e4, step.disp = 1e3 )
factor.9.mis = SummarizeMCMC(50, 10050, 5e4, 50)
############## plot the simulation results ##############
compare_correlation = function( summary.mcmc ){
# for each repeated simulation
# compute the mean correlation matrix
# compare it with the truth
sapply( summary.mcmc, function(x){
corr.tru = cov2cor( t(x$truth$Y.tru)%*%x$truth$Y.tru +
diag( rep(x$truth$er, ncol(x$truth$Y.tru)) ) )
corr.est = lapply( x$mcmc, function(mcmc.tc.ind){
tc.ind.all.corr = lapply( mcmc.tc.ind,
function(mcmc.ind)
cov2cor( t(mcmc.ind$Y)%*%mcmc.ind$Y +
diag( rep( mcmc.ind$er, ncol(mcmc.ind$Y) ) ) ) )
apply( array( unlist(tc.ind.all.corr),
dim = c(dim(tc.ind.all.corr[[1]]), length(tc.ind.all.corr)) ),
1:2, mean )
} )
sapply( corr.est, function(corr.ind) rv.coef( corr.tru, corr.ind ) )
})
# return a matrix of accuracy
# each col is a specific repeat
# each row is a specific number of factors
}
# compute the accuracy (RV coefficients) of the estimated Gram matrices
accuracy.3 = compare_correlation( factor.3 )
accuracy.6 = compare_correlation( factor.6 )
accuracy.9 = compare_correlation( factor.9 )
accuracy.3.mis = compare_correlation( factor.3.mis )
accuracy.6.mis = compare_correlation( factor.6.mis )
accuracy.9.mis = compare_correlation( factor.9.mis )
# boxplots to summarize all the RV coeffients
plot.corr.est = data.frame( rv = c( t(accuracy.3), t(accuracy.6), t(accuracy.9) ),
total = as.factor( rep( rep( c(1000,10000,100000),
each = ncol( accuracy.3 ) ), 3 ) ),
tru.factor = as.factor( rep( c(3,6,9), each = 3*ncol( accuracy.3 ) ) ),
group = as.factor( rep( 1:9, each = ncol( accuracy.3 ) ) ) )
plot.corr.est.mis = data.frame( rv = c( t(accuracy.3.mis), t(accuracy.6.mis), t(accuracy.9.mis) ),
total = as.factor( rep( rep( c(1000,10000,100000),
each = ncol( accuracy.3 ) ), 3 ) ),
tru.factor = as.factor( rep( c(3,6,9),
each = 3*ncol( accuracy.3 ) ) ),
group = as.factor( rep( 1:9, each = ncol( accuracy.3 ) ) ) )
# plot the boxplots
ggplot( data = plot.corr.est, aes( x = total, y = rv, group = group,
dodge = tru.factor, fill = tru.factor ), guide = F ) +
geom_boxplot() + xlab("Total counts") + ylab("Estimate accuracy") +
scale_y_continuous(limits=c(0.5, 1)) + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold") ) +
labs( fill = "No. factors") + ggtitle( "Correctly specified model" )
ggplot( data = plot.corr.est.mis, aes( x = total, y = rv, group = group,
dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot() + xlab("Total counts") + ylab("Estimate accuracy") +
scale_y_continuous(limits=c(0.5, 1)) + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold")) +
labs( fill = "No. factors") + ggtitle( "Misspecified model" )
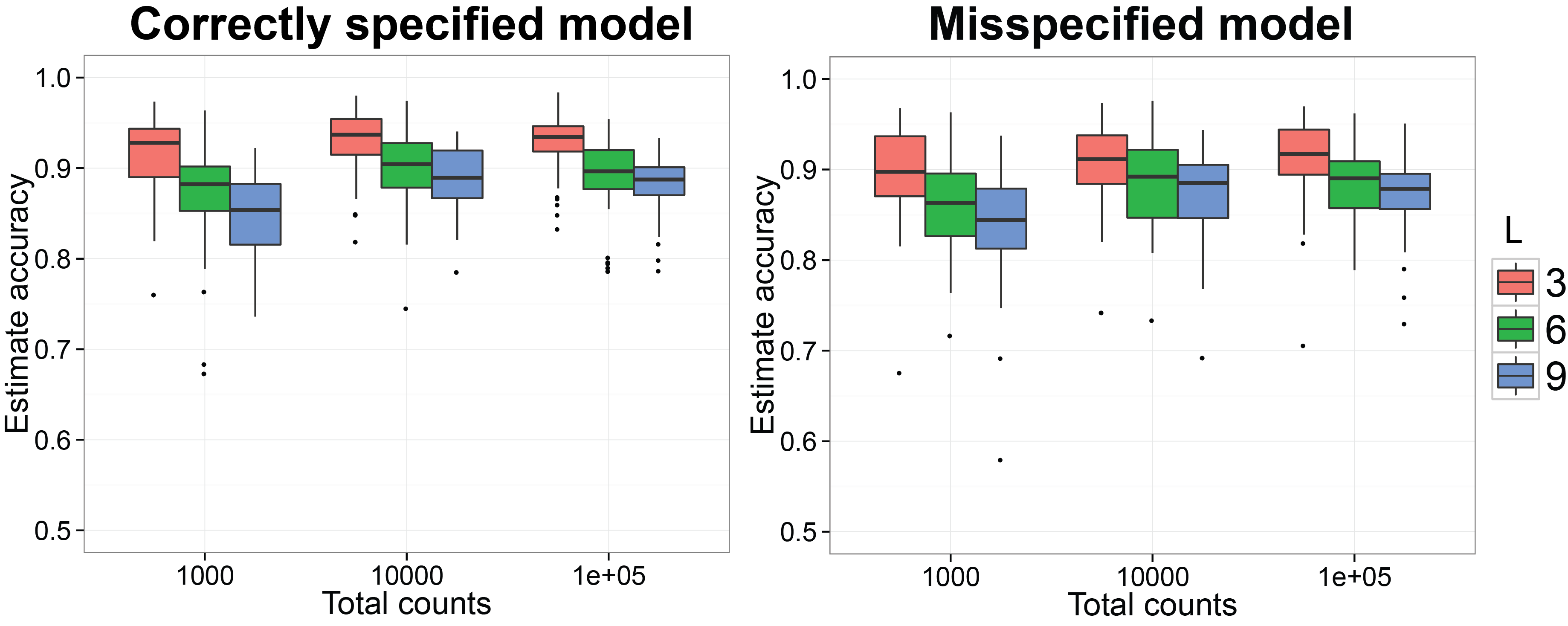
Shrink the dimension of the latent factros towards the correct dimension
We still use the previous MCMC results. In this subsection we want to evaluate whether the estimated latent factors are concentrated on a linear space with the similar dimension as the dimesion of the true latent factors. The code we used is listed below:
library( DirFactor )
calculate_pca = function( summary.mcmc ){
lapply( summary.mcmc, function(x){
lapply( x$mcmc, function(y)
sapply( y, function(z){tmp = princomp(t(z$Y));tmp$sdev^2/sum(tmp$sdev^2)}) )
})
# returns a list of variance explained as a function of index of PC
# for each scenario, for each MCMC iteration
}
pca.3 = calculate_pca( factor.3 )
pca.6 = calculate_pca( factor.6 )
pca.9 = calculate_pca( factor.9 )
pca.3.mis = calculate_pca( factor.3.mis )
pca.6.mis = calculate_pca( factor.6.mis )
pca.9.mis = calculate_pca( factor.9.mis )
pca.3.sub = array( unlist( lapply( pca.3, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.6.sub = array( unlist( lapply( pca.6, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.9.sub = array( unlist( lapply( pca.9, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.3.sub.mis = array( unlist( lapply( pca.3.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.6.sub.mis = array( unlist( lapply( pca.6.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.9.sub.mis = array( unlist( lapply( pca.9.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.plot.data = data.frame( ve = sqrt( c( pca.3.sub, pca.6.sub, pca.9.sub ) ),
comp = as.factor( rep( rep( 1:10, 50 ), 3) ),
tru.factor = as.factor( rep( c(3,6,9), each = 500 ) ) )
pca.plot.data.mis = data.frame( ve = sqrt( c( pca.3.sub.mis, pca.6.sub.mis, pca.9.sub.mis ) ),
comp = as.factor( rep( rep( 1:10, 50 ), 3) ),
tru.factor = as.factor( rep( c(3,6,9), each = 500 ) ) )
x = rep( c( 0.75, 1, 1.25 ), 10 ) + rep( 0:9, each = 3 ) - 0.125
xend = rep( c( 0.75, 1, 1.25 ), 10 ) + rep( 0:9, each = 3 ) + 0.125
y = rep( 0.6, 30 )
yend = rep( 0.6, 30 )
ggplot( data = pca.plot.data, aes( x = comp, y = ve, dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot(outlier.size = 0) + xlab("Principal component") +
ylab("Sqrt variance explained") + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold" ) ) +
labs( fill = "No. factors") + ggtitle( "Correctly specified model")
ggplot( data = pca.plot.data.mis, aes( x = comp, y = ve, dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot(outlier.size = 0) + xlab("Principal component") +
ylab("Sqrt variance explained") + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold" )) +
labs( fill = "No. factors") + ggtitle( "Misspecified model" )
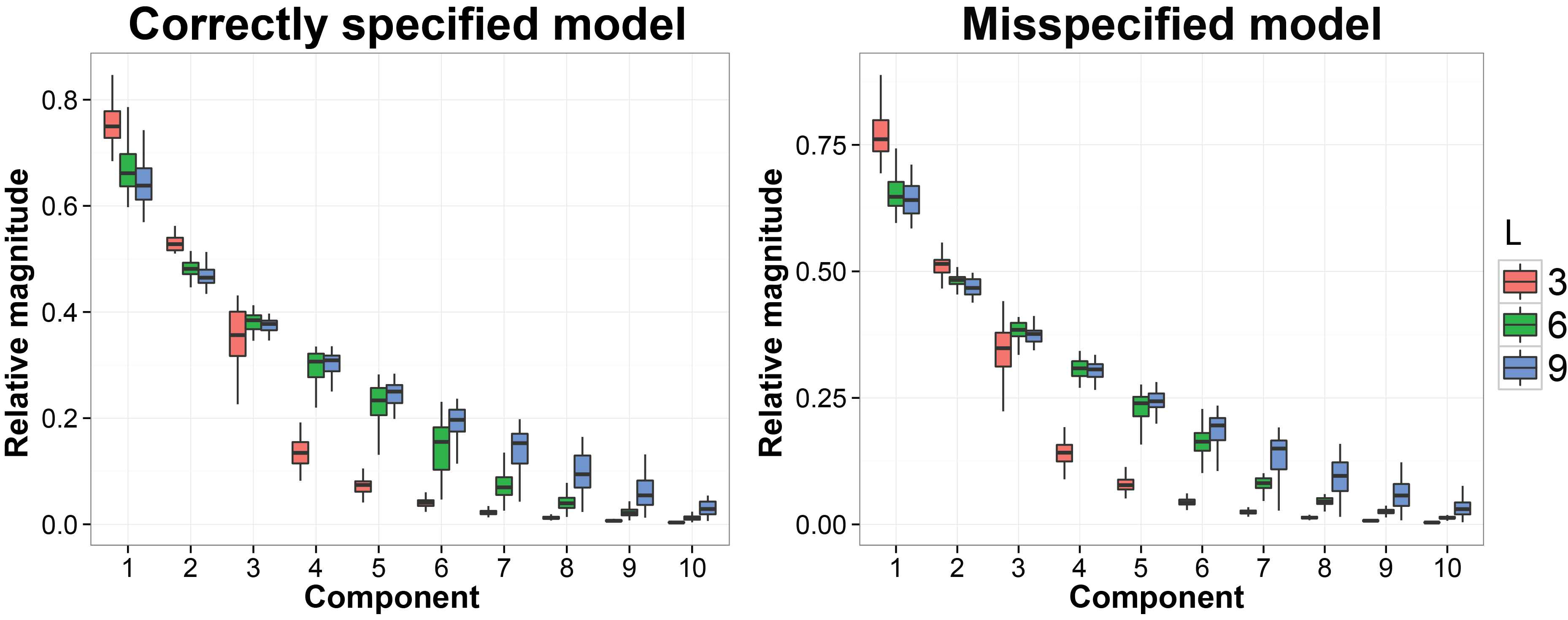
Borrowing information can increase the accuracy of the estimated probabilities of species
We then use a different simulation method to verify using a dependent prior on the probabilities of species can increase the accuracy on their estimates. The function we are using is SimDirFactorSym. It has an argument Y.corr controls the similarity between biological samples. When Y.corr approaches one, the similarity between a pair of biological will be maximized. We simulate data with 68 species and 22 biological samples with 3 latent factors. We consider the scenarios where Y.corr is 0.5, 0.75 and 0.95, the misspecification parameter a is 1, 2, 3 and the total counts per biological samples is varying from 10 to 100.
library( DirFactor )
prediction.pw.ind = function( sim.res, hyper, read.depth, save.path, Q.power, ... ){
res.cache = c()
final.weights = sim.res$sigma*(sim.res$Q*(sim.res$Q>0))^Q.power
for( i in 1:length( read.depth ) ){
cat( sprintf( "Read depth is %d\n", read.depth[i] ) )
#simulate data
dat.ind = apply( final.weights, 2, function(x) rmultinom( 1, read.depth[i], prob=x ) )
#Bayesian method
DirFactor( dat.ind, hyper, save.path = paste( save.path, "res", sep = "/"), ... )
res = lapply( list.files( save.path, pattern = "res", full.names=T ), readRDS )
bayes.est.ls = lapply( res, function(x){
weight = x$sigma*(x$Q)^2*(x$Q>0)
t(t(weight)/colSums(weight) )
})
bayes.est.mt = array( unlist( bayes.est.ls ),
dim = c( dim( bayes.est.ls[[1]] ),
length( bayes.est.ls ) ) )
bayes.est.mean = apply( bayes.est.mt, 1:2, mean )
bayes.diff = bayes.est.mean - t(t(final.weights)/colSums(final.weights))
bayes.error = apply( bayes.diff, 2, function(x) sum(x[x>0]) )
#direct normalization method
dat.diff = t(t(dat.ind)/colSums(dat.ind)) - t(t(final.weights)/colSums(final.weights))
dat.error = apply( dat.diff, 2, function(x) sum(x[x>0]) )
#gain in each population for bayesian method
res.cache = rbind( res.cache, dat.error - bayes.error )
}
res.cache
}
prediction.calc = function( read.depth, a, Y.corr, hyper, n.rep = 50, ...){
library(snowfall)
sfInit( parallel=TRUE, cpus=n.rep )
sfLibrary( DirFactor )
sfExport( list = c("read.depth", "hyper", "prediction.pw.ind") )
res.all = sfLapply( 1:n.rep, function(rep){
cat( sprintf( "Replication %d\n", rep ) )
save.path = paste( "pw_sim", rep, sep = "_" )
dir.create( save.path, showWarnings = FALSE )
sim.res = SimDirFactorSym( 1e4, 22, 68, 3, hyper, a = a, Y.corr = Y.corr )
prediction.pw.ind( sim.res, hyper, read.depth, save.path, a, ... )
} )
sfStop()
res.all
}
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
read.depth = seq(10,100,10)
#between sample correlation 0.5
pw.corr05.a05 = prediction.calc( read.depth, 0.5, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a1 = prediction.calc( read.depth, 1, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a2 = prediction.calc( read.depth, 2, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a3 = prediction.calc( read.depth, 3, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
#between sample correlation 0.75
pw.corr075.a05 = prediction.calc( read.depth, 0.5, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a1 = prediction.calc( read.depth, 1, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a2 = prediction.calc( read.depth, 2, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a3 = prediction.calc( read.depth, 3, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
#between sample correlation 0.95
pw.corr095.a05 = prediction.calc( read.depth, 0.5, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a1 = prediction.calc( read.depth, 1, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a2 = prediction.calc( read.depth, 2, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a3 = prediction.calc( read.depth, 3, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
all.gains = lapply( list(pw.corr05.a05,pw.corr05.a1,pw.corr05.a2,pw.corr05.a3,
pw.corr075.a05,pw.corr075.a1,pw.corr075.a2,pw.corr075.a3,
pw.corr095.a05,pw.corr095.a1,pw.corr095.a2,pw.corr095.a3),
function(x) rowMeans( sapply( x, rowMeans ) ) )
plot.data = data.frame( read.depth = rep( read.depth,length(all.gains) ),
gain = unlist( all.gains ),
similarity = rep( as.factor(c(0.5,0.75,0.95)), each = 4*length(read.depth) ),
Q.power = rep( rep( as.factor(c(2,1,0.5,3)), each = length(read.depth) ), 3 ) )
ggplot( data = plot.data, aes(x=read.depth, y=gain, color=similarity, shape = Q.power) ) +
geom_line() + geom_point(size=5) + theme_bw() + xlab("Read depth") +
ylab("Gain in estimate accuracy" ) + scale_shape_manual( values = c(15:17,4)) +
scale_x_continuous( breaks = read.depth ) +
theme( axis.title = element_text( size = 18 ), axis.text= element_text( size = 15 ),
legend.title = element_text( size = 15, face = "bold" ),
plot.title = element_text( size = 15, face = "bold") )
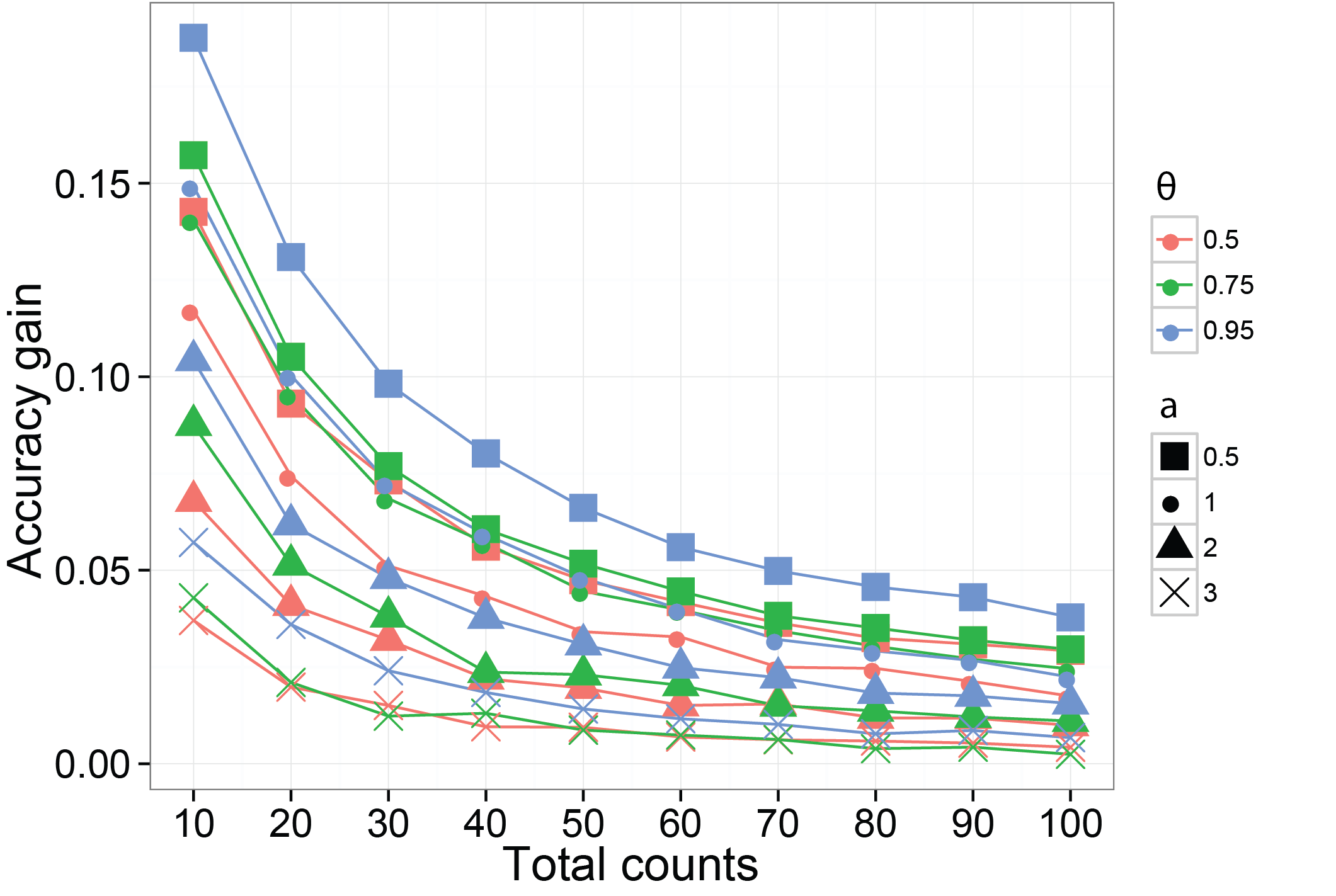
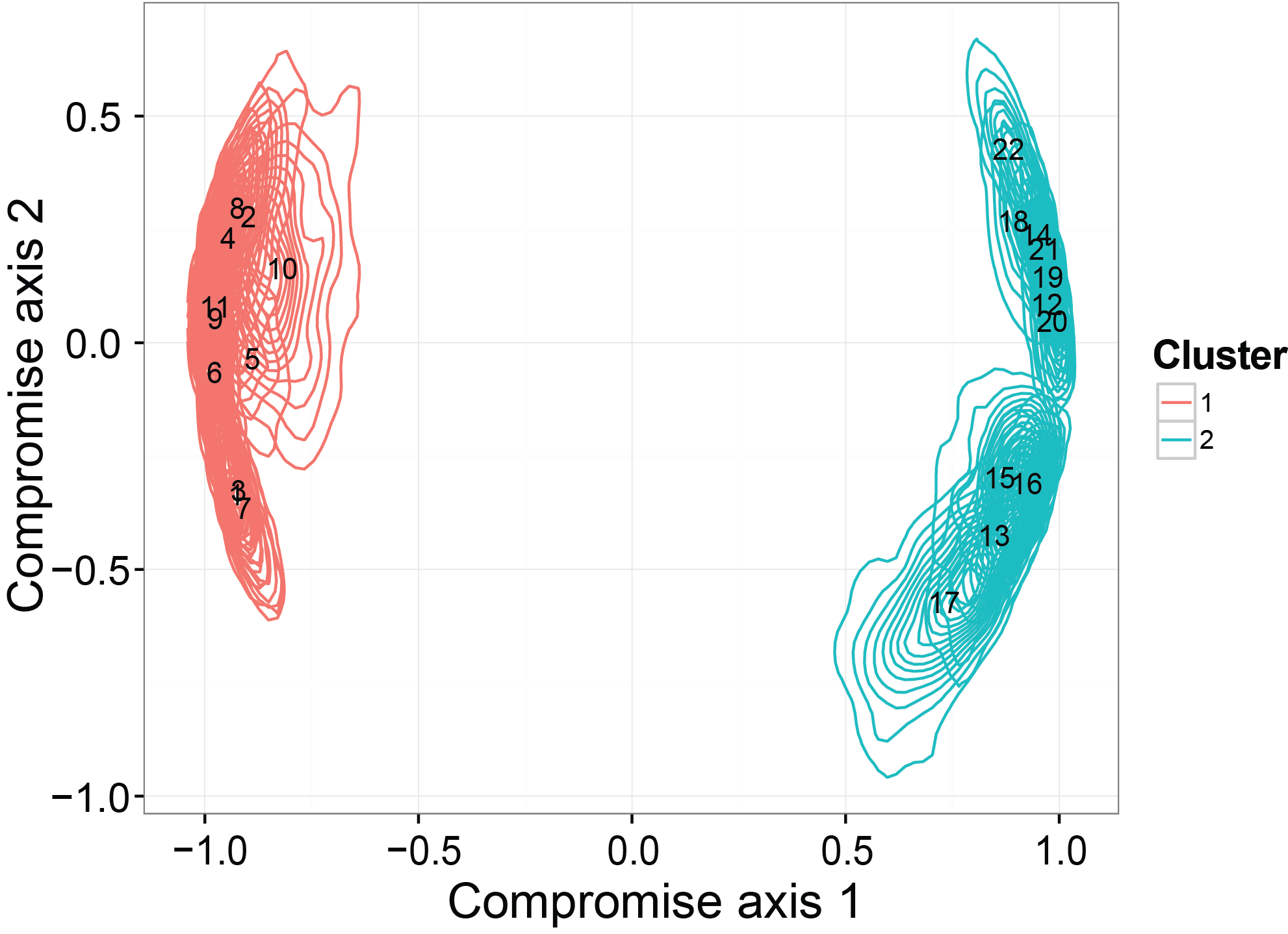
Ordination with credible regions recover the clustering structure
The last thing we checked in the simulation studies is whether the ordination results generated from our model can detect a binary clustering pattern in the simulated dataset. Moreover, we want to see if the credible region will be consistent with the truth. The simulated dataset is generated by SimDirFactorContour. The distance between the two clusters is 3, which is much larger than the noise level (er=0.1).
library(DirFactor)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
sim.data.contour = SimDirFactorContour( strength = 3, 1000, n = 22, p = 68, m = 3, hyper )
mcmc.res.contour = DirFactor( sim.data.contour$data[[1]], hyper, step = 50000, thin=5 )
all.res = lapply( paste( mcmc.res.contour$save.path, seq( 20005,50000,5), sep = "_" ), readRDS )
all.corr = lapply( all.res, function(x) cov2cor( t(x$Y)%*%x$Y + diag( rep( x$er, ncol(x$Y) ) ) ) )
all.corr.use = all.corr[sample(1:length(all.corr),size = 1000, replace = T)]
statis.res = PlotStatis( all.corr.use, n.dim = 2, types = rep( c(1:2), each = 11 ), labels = 1:22 )
statis.res[[1]]
Two applications of DirFactor
GlobalPatterns dataset
The GlobalPatterns dataset (Caporaso et al. 2011) includes 26 biological samples derived from both human and environmental specimens. There are a total of 19,216 OTUs and the average total counts per biological sample is larger than 100,000. We collapsed all taxa OTUs to the genus level--a standard operation in microbiome studies--and yielded 996 distinct genera. We treated these genera as OTUs and fit our model to this collapsed dataset. We ran one MCMC chain for 50,000 iterations and recorded posterior samples every 10 iterations.
We first performed a cluster analysis of biological samples based on their microbial compositions. We then visualized the biological samples using ordination plots with the associated credible intervals. We specify the number of axes we considered in ordination as three. In both analyses, we choose to use the distance matrix calculated from the estimated probabilities of species to capture the relationship between biological samples. The distance metric is Bray-Curtis dissimilarity. The code for the clustering analysis and ordination plots are listed below.
library( vegan )
library( DirFactor )
library( phyloseq )
library( fpc )
data( GlobalPatterns )
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
gp.genus = tax_glom( GlobalPatterns, "Genus")
gp.metadata = sample_data( GlobalPatterns )
data = otu_table( gp.genus )
gp.mcmc = DirFactor( data, hyper, step = 50000, thinning=10 )
gp.all.res = lapply( paste( gp.mcmc$save.path, seq(10010,50000,10), sep = "_" ), readRDS )
#get bray-curtis distance matrix
all.bc.gp = lapply( gp.all.res, function(x){
weights = x$Q^2*(x$Q>0)*x$sigma
w.norm = t(weights)/colSums(weights)
vegdist( w.norm, method = "bray" )
})
use.idx = sample( 1:length(gp.all.res), 1000, replace = F )
#distatis
sub.bc.ls.gp = lapply( all.bc.gp[use.idx], as.matrix )
plot.bc.gp = PlotStatis( sub.bc.ls.gp, n.dim = 3, labels = gp.metadata$SampleType,
types = gp.metadata$SampleType )
plot.bc.gp[[1]]
plot.bc.gp[[2]]
plot.bc.gp[[3]]
#clustering plot
PlotClustering( all.bc.gp, gp.metadata$SampleType )
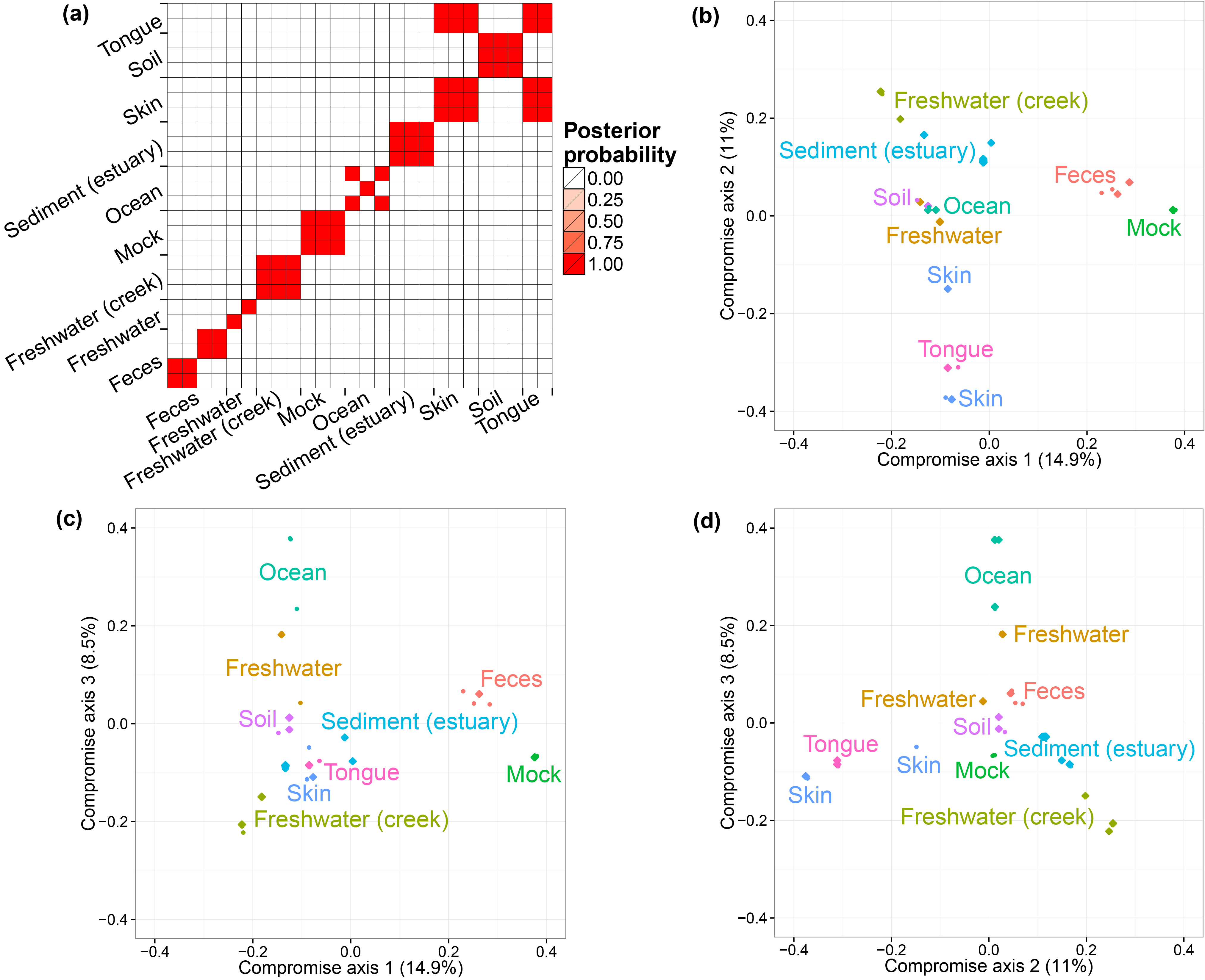
Ravel's vaginal microbiome dataset
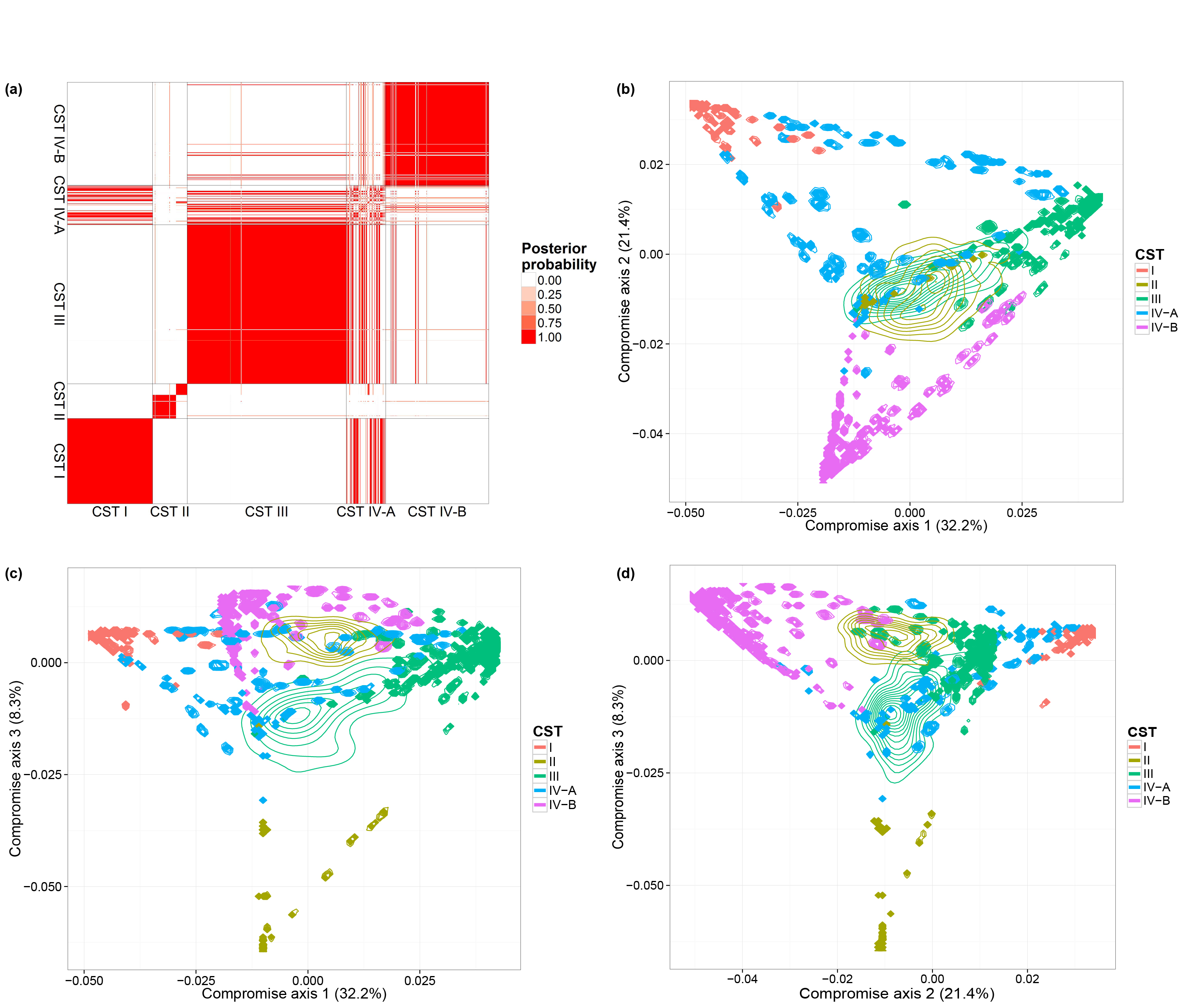
We also consider a vaginal dataset (Ravel et al. 2011) which contains a larger number of biological samples (900) and a simpler bacterial community structure. These biological samples are derived from 54 healthy women. Multiple biological samples are taken from each individual, ranging from one to 32 biological samples per individual. Each woman has been classified, before our microbiome sequencing data were generated, into vaginal community state subtypes (CST). This dataset contains only species level taxonomic information and we filtered OTUs by occurrence. We only retain species with more than 5 reads in at least 10% of biological samples. This filtering resulted in 31 distinct OTUs. We ran one MCMC chain with 50,000 iterations.
We performed the same analyses as in the previous subsection and will load the MCMC results directly. The code for generating the figures are listed below:
library(DirFactor)
library(phyloseq)
data(JRphylo)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
# filtering Ravel's data by occurence
JRfilt = genefilter_sample(JRphylo, filterfun_sample(function(x) x > 5), A = 0.1 * nsamples(JRphylo))
JR1 = prune_taxa(JRfilt, JRphylo)
ravel.mcmc = DirFactor( t(otu_table(JR1)), hyper, step = 50000, thinning = 10 )
ravel.all.res = lapply( paste( ravel.mcmc$save.path, seq( 10010, 50000, 10 ), sep = "_" ), readRDS )
#get bray-curtis distance matrix
all.bc.ravel = lapply( ravel.all.res, function(x){
weights = x$Q^2*(x$Q>0)*x$sigma
w.norm = t(weights)/colSums(weights)
vegdist( w.norm, method = "bray" )
})
use.idx = sample( 1:length(all.bc.ravel), 1000, replace = F )
#distatis
sub.bc.ls.ravel = lapply( all.bc.ravel[use.idx], as.matrix )
plot.bc.ravle = PlotStatis( sub.bc.ls.ravel, n.dim = 3,
types = sample_data(JR1)$CST )
plot.bc[[1]]
plot.bc[[2]]
plot.bc[[3]]
#clustering using bc
PlotClustering( all.bc.ravel, sample_data(JR1)$CST )
References
Caporaso, J. G., C. L. Lauber, W. A. Walters, D. Berg-Lyons, C. A. Lozupone, P. J. Turnbaugh, N. Fierer, and R. Knight. 2011. “Global Patterns of 16S RRNA Diversity at a Depth of Millions of Sequences Per Sample.” Proceedings of the National Academy of Sciences 108 (Supplement 1). National Acad Sciences: 4516–22.
Ravel, J., P. Gajer, Z. Abdo, G. M. Schneider, Sara S. K. K., S. L. McCulle, S. Karlebach, et al. 2011. “Vaginal Microbiome of Reproductive-Age Women.” Proceedings of the National Academy of Sciences 108 (Supplement 1). National Acad Sciences: 4680–7.
Ren, Boyu, Sergio Bacallado, Stefano Favaro, Susan Holmes, and Lorenzo Trippa. 2016. “Bayesian Nonparametric Ordination for the Analysis of Microbial Communities.” ArXiv Preprint ArXiv:1601.05156.
boyuren158/DirFactor documentation built on May 13, 2019, 1:38 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Dependent Dirichlet processes factor model for nonparametric ordination in Microbiome data (DirFactor)
Boyu Ren 2016-12-22
- Introduction
- How To Run
- Simulation studies for DirFactor
- Estimate the normalized Gram matrix between biological samples using DirFactor
- Shrink the dimension of the latent factros towards the correct dimension
- Borrowing information can increase the accuracy of the estimated probabilities of species
- Ordination with credible regions recover the clustering structure
- Two applications of DirFactor
- References
Introduction
Human microbiome studies use sequencing technologies to measure the abundance of bacterial species or Operational Taxonomic Units (OTUs) in samples of biological material. Typically the data are organized in contingency tables with OTU counts across heterogeneous biological samples. In the microbial ecology community, ordination methods are frequently used to investigate latent factors or clusters that capture and describe variations of OTU counts across biologi- cal samples. It remains important to evaluate how uncertainty in estimates of each biological sample’s microbial distribution propagates to ordination analyses, including visualization of clusters and projections of biological samples on low dimensional spaces.
We propose a Bayesian analysis for dependent distributions to endow frequently used ordinations with estimates of uncertainty. A Bayesian nonparametric prior for dependent normalized random measures is constructed, which is marginally equivalent to the normalized generalized Gamma process, a well-known prior for nonparametric analyses. In our prior the dependence and similarity between microbial distributions is represented by latent factors that concentrate in a low dimensional space. We use a shrinkage prior to tune the dimensionality of the latent factors. The resulting posterior samples of model parameters can be used to evaluate uncertainty in analyses routinely applied in microbiome studies. Specifically, by combining them with multivariate data analysis techniques we can visualize credible regions in ecological ordination plots.
How To Run
Loading
We first need to load the package:
library(DirFactor)
Package Features
The DirFactor package contains six functions:
DirFactor, the main function for running Gibbs sampler on an OTU table.ConvDiagnosis, the diagnosis function to check if the posterior simulation mixed.PlotStatis, the plotting function to visualize nonparametric ordination results as well as its uncertainty given by the DirFactor model.SimDirFactorBlock,SimDirFactorSym,SimDirFactorContour, three related functions used to generate synthetic datasets considered in the simulation studies in (Ren et al. 2016).
Data and Prior Input
For a full and complete description of the possible parameters for DirFactor, their default values, and the output, see
?DirFactor
Required Input
There are two required input for running DirFactor. A data matrix stores the OTU table of species abundance in each biological sample, where biological samples are be in columns and species in rows. A list hyper contains the values of the hyper-parameters of priors. By default, the starting values of the model parameters will be generated from the priors. Below is a minimal example for DirFactor. We use SimDirFactorBlock to simulate a synthetic dataset with 22 biological samples and 68 species with total counts per sample being 106. The true Gram matrix between samples is a block-diagonal matrix with two blocks, which is induced by three latent factors. When running the MCMC, we specify the number of factors to be 10. DirFactor by default save the MCMC results in an temporary path and it will return the path once finished.
library(DirFactor)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
sim.data = SimDirFactorBlock( 1e6, n = 22, p = 68, m = 3, hyper )
mcmc.out = DirFactor( sim.data$data[[1]], hyper )
Simulation studies for DirFactor
We use the code for the simulation studies in (Ren et al. 2016) to illustrate how to use DirFactor in general.
Estimate the normalized Gram matrix between biological samples using DirFactor
Starting at this subsection, we will reproduce the simulation results in (Ren et al. 2016). We first want to check if the procedure can recover the normalized Gram matrix between biological samples accurately. We have already finished the MCMC simulation for 50 replicates on simulated datasets generated by SimDirFactorBlock when the model is correctly specified (a=2) and misspecified (a=1). We also consider the case when the dimensions of true latent factors are 3, 6 and 9 as well as when the total counts per biological sample is 103, 104 and 105. The code below will generate n.rep number of simulation datasets and run them in n.rep cores in parallel. Please make sure your platform has n.rep number of cores available. The MCMC results for the ith simulation will be saved in the subfolder run_i/ under current directory and the truth for the simulation will be saved in truth_i as an RDS object.
library( DirFactor )
# Simulating data and run mcmc for all different scenarios
# Each scenario will be repeated n.rep times
RunSimulation = function( n.rep, n.factor, hyper, a = 2, ... ){
library( snowfall )
# Parallelization, change cpus=50 to reasonable number if running locally
sfInit( parallel=TRUE, cpus=n.rep )
sfLibrary(DirFactor)
sfExport( "hyper" )
# save the simulated parameters to truth_i
# save the mcmc results to run_i/sim_j
sfLapply( 1:n.rep, function(x){
sim.data = SimDirFactorBlock( c(1000,10000,100000), n = 22, p = 68,
m = 3, hyper = hyper, K = 2, a = a )
dir.create( paste( "run_", x, sep = "" ), showWarnings = FALSE )
saveRDS( sim.data, paste( "truth", x, sep = "_" ) )
for( id in 1:length( sim.data$data ) ){
#create the folder to save the MCMC results
dat.ind = sim.data$data[[id]]
DirFactor( dat.ind, hyper,
save.path = paste("run_", x, "/sim_", id, sep = "" ),
... )
}
})
sfStop()
}
# Summarize mcmc results
SummarizeMCMC = function( n.rep, start, end, thin ){
lapply( 1:n.rep, function(x){
tru.res = readRDS(paste("truth", x, sep = "_"))
mcmc.res = lapply( 1:3, function(i)
lapply( paste(paste("run_", x, "/sim_", i, sep = ""),
seq( start, end, thin ), sep = "_"), readRDS ) )
list( truth = tru.res, mcmc = mcmc.res )
})
}
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
# dim(factor) = 3
# correctly specified
RunSimulation( n.rep = 50, n.factor = 3, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.3 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 3, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50, step = 5e4, step.disp = 1e3 )
factor.3.mis = SummarizeMCMC(50, 10050, 5e4, 50)
# dim(factor) = 6
# correctly specified
RunSimulation( n.rep = 50, n.factor = 6, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.6 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 6, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50,step = 5e4, step.disp = 1e3 )
factor.6.mis = SummarizeMCMC(50, 10050, 5e4, 50)
#dim(factor) = 9
# correctly specified
RunSimulation( n.rep = 50, n.factor = 9, hyper, save.obj = c("Y", "er"), thinning = 50,
step = 5e4, step.disp = 1e3 )
factor.9 = SummarizeMCMC(50, 10050, 5e4, 50)
# misspecified
RunSimulation( n.rep = 50, n.factor = 9, hyper, a = 1, save.obj = c("Y", "er"),
thinning = 50,step = 5e4, step.disp = 1e3 )
factor.9.mis = SummarizeMCMC(50, 10050, 5e4, 50)
############## plot the simulation results ##############
compare_correlation = function( summary.mcmc ){
# for each repeated simulation
# compute the mean correlation matrix
# compare it with the truth
sapply( summary.mcmc, function(x){
corr.tru = cov2cor( t(x$truth$Y.tru)%*%x$truth$Y.tru +
diag( rep(x$truth$er, ncol(x$truth$Y.tru)) ) )
corr.est = lapply( x$mcmc, function(mcmc.tc.ind){
tc.ind.all.corr = lapply( mcmc.tc.ind,
function(mcmc.ind)
cov2cor( t(mcmc.ind$Y)%*%mcmc.ind$Y +
diag( rep( mcmc.ind$er, ncol(mcmc.ind$Y) ) ) ) )
apply( array( unlist(tc.ind.all.corr),
dim = c(dim(tc.ind.all.corr[[1]]), length(tc.ind.all.corr)) ),
1:2, mean )
} )
sapply( corr.est, function(corr.ind) rv.coef( corr.tru, corr.ind ) )
})
# return a matrix of accuracy
# each col is a specific repeat
# each row is a specific number of factors
}
# compute the accuracy (RV coefficients) of the estimated Gram matrices
accuracy.3 = compare_correlation( factor.3 )
accuracy.6 = compare_correlation( factor.6 )
accuracy.9 = compare_correlation( factor.9 )
accuracy.3.mis = compare_correlation( factor.3.mis )
accuracy.6.mis = compare_correlation( factor.6.mis )
accuracy.9.mis = compare_correlation( factor.9.mis )
# boxplots to summarize all the RV coeffients
plot.corr.est = data.frame( rv = c( t(accuracy.3), t(accuracy.6), t(accuracy.9) ),
total = as.factor( rep( rep( c(1000,10000,100000),
each = ncol( accuracy.3 ) ), 3 ) ),
tru.factor = as.factor( rep( c(3,6,9), each = 3*ncol( accuracy.3 ) ) ),
group = as.factor( rep( 1:9, each = ncol( accuracy.3 ) ) ) )
plot.corr.est.mis = data.frame( rv = c( t(accuracy.3.mis), t(accuracy.6.mis), t(accuracy.9.mis) ),
total = as.factor( rep( rep( c(1000,10000,100000),
each = ncol( accuracy.3 ) ), 3 ) ),
tru.factor = as.factor( rep( c(3,6,9),
each = 3*ncol( accuracy.3 ) ) ),
group = as.factor( rep( 1:9, each = ncol( accuracy.3 ) ) ) )
# plot the boxplots
ggplot( data = plot.corr.est, aes( x = total, y = rv, group = group,
dodge = tru.factor, fill = tru.factor ), guide = F ) +
geom_boxplot() + xlab("Total counts") + ylab("Estimate accuracy") +
scale_y_continuous(limits=c(0.5, 1)) + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold") ) +
labs( fill = "No. factors") + ggtitle( "Correctly specified model" )
ggplot( data = plot.corr.est.mis, aes( x = total, y = rv, group = group,
dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot() + xlab("Total counts") + ylab("Estimate accuracy") +
scale_y_continuous(limits=c(0.5, 1)) + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold")) +
labs( fill = "No. factors") + ggtitle( "Misspecified model" )
Shrink the dimension of the latent factros towards the correct dimension
We still use the previous MCMC results. In this subsection we want to evaluate whether the estimated latent factors are concentrated on a linear space with the similar dimension as the dimesion of the true latent factors. The code we used is listed below:
library( DirFactor )
calculate_pca = function( summary.mcmc ){
lapply( summary.mcmc, function(x){
lapply( x$mcmc, function(y)
sapply( y, function(z){tmp = princomp(t(z$Y));tmp$sdev^2/sum(tmp$sdev^2)}) )
})
# returns a list of variance explained as a function of index of PC
# for each scenario, for each MCMC iteration
}
pca.3 = calculate_pca( factor.3 )
pca.6 = calculate_pca( factor.6 )
pca.9 = calculate_pca( factor.9 )
pca.3.mis = calculate_pca( factor.3.mis )
pca.6.mis = calculate_pca( factor.6.mis )
pca.9.mis = calculate_pca( factor.9.mis )
pca.3.sub = array( unlist( lapply( pca.3, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.6.sub = array( unlist( lapply( pca.6, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.9.sub = array( unlist( lapply( pca.9, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.3.sub.mis = array( unlist( lapply( pca.3.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.6.sub.mis = array( unlist( lapply( pca.6.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.9.sub.mis = array( unlist( lapply( pca.9.mis, function(x)
apply( x[[1]], 1, function(vec) c( mean(vec), quantile( vec, probs = c(0.025,0.975 ) ) ) ) ) ),
dim = c( 3,10,50 ) )[1,,]
pca.plot.data = data.frame( ve = sqrt( c( pca.3.sub, pca.6.sub, pca.9.sub ) ),
comp = as.factor( rep( rep( 1:10, 50 ), 3) ),
tru.factor = as.factor( rep( c(3,6,9), each = 500 ) ) )
pca.plot.data.mis = data.frame( ve = sqrt( c( pca.3.sub.mis, pca.6.sub.mis, pca.9.sub.mis ) ),
comp = as.factor( rep( rep( 1:10, 50 ), 3) ),
tru.factor = as.factor( rep( c(3,6,9), each = 500 ) ) )
x = rep( c( 0.75, 1, 1.25 ), 10 ) + rep( 0:9, each = 3 ) - 0.125
xend = rep( c( 0.75, 1, 1.25 ), 10 ) + rep( 0:9, each = 3 ) + 0.125
y = rep( 0.6, 30 )
yend = rep( 0.6, 30 )
ggplot( data = pca.plot.data, aes( x = comp, y = ve, dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot(outlier.size = 0) + xlab("Principal component") +
ylab("Sqrt variance explained") + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold" ) ) +
labs( fill = "No. factors") + ggtitle( "Correctly specified model")
ggplot( data = pca.plot.data.mis, aes( x = comp, y = ve, dodge = tru.factor, fill = tru.factor ) ) +
geom_boxplot(outlier.size = 0) + xlab("Principal component") +
ylab("Sqrt variance explained") + theme_bw() +
theme( axis.text = element_text( size = 15 ), axis.title = element_text( size = 18 ),
legend.title = element_text( size = 15 ), legend.text = element_text( size = 15 ),
plot.title = element_text( size = 18, face = "bold" )) +
labs( fill = "No. factors") + ggtitle( "Misspecified model" )
Borrowing information can increase the accuracy of the estimated probabilities of species
We then use a different simulation method to verify using a dependent prior on the probabilities of species can increase the accuracy on their estimates. The function we are using is SimDirFactorSym. It has an argument Y.corr controls the similarity between biological samples. When Y.corr approaches one, the similarity between a pair of biological will be maximized. We simulate data with 68 species and 22 biological samples with 3 latent factors. We consider the scenarios where Y.corr is 0.5, 0.75 and 0.95, the misspecification parameter a is 1, 2, 3 and the total counts per biological samples is varying from 10 to 100.
library( DirFactor )
prediction.pw.ind = function( sim.res, hyper, read.depth, save.path, Q.power, ... ){
res.cache = c()
final.weights = sim.res$sigma*(sim.res$Q*(sim.res$Q>0))^Q.power
for( i in 1:length( read.depth ) ){
cat( sprintf( "Read depth is %d\n", read.depth[i] ) )
#simulate data
dat.ind = apply( final.weights, 2, function(x) rmultinom( 1, read.depth[i], prob=x ) )
#Bayesian method
DirFactor( dat.ind, hyper, save.path = paste( save.path, "res", sep = "/"), ... )
res = lapply( list.files( save.path, pattern = "res", full.names=T ), readRDS )
bayes.est.ls = lapply( res, function(x){
weight = x$sigma*(x$Q)^2*(x$Q>0)
t(t(weight)/colSums(weight) )
})
bayes.est.mt = array( unlist( bayes.est.ls ),
dim = c( dim( bayes.est.ls[[1]] ),
length( bayes.est.ls ) ) )
bayes.est.mean = apply( bayes.est.mt, 1:2, mean )
bayes.diff = bayes.est.mean - t(t(final.weights)/colSums(final.weights))
bayes.error = apply( bayes.diff, 2, function(x) sum(x[x>0]) )
#direct normalization method
dat.diff = t(t(dat.ind)/colSums(dat.ind)) - t(t(final.weights)/colSums(final.weights))
dat.error = apply( dat.diff, 2, function(x) sum(x[x>0]) )
#gain in each population for bayesian method
res.cache = rbind( res.cache, dat.error - bayes.error )
}
res.cache
}
prediction.calc = function( read.depth, a, Y.corr, hyper, n.rep = 50, ...){
library(snowfall)
sfInit( parallel=TRUE, cpus=n.rep )
sfLibrary( DirFactor )
sfExport( list = c("read.depth", "hyper", "prediction.pw.ind") )
res.all = sfLapply( 1:n.rep, function(rep){
cat( sprintf( "Replication %d\n", rep ) )
save.path = paste( "pw_sim", rep, sep = "_" )
dir.create( save.path, showWarnings = FALSE )
sim.res = SimDirFactorSym( 1e4, 22, 68, 3, hyper, a = a, Y.corr = Y.corr )
prediction.pw.ind( sim.res, hyper, read.depth, save.path, a, ... )
} )
sfStop()
res.all
}
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 10, alpha = 10, beta = 0 )
read.depth = seq(10,100,10)
#between sample correlation 0.5
pw.corr05.a05 = prediction.calc( read.depth, 0.5, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a1 = prediction.calc( read.depth, 1, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a2 = prediction.calc( read.depth, 2, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr05.a3 = prediction.calc( read.depth, 3, 0.5, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
#between sample correlation 0.75
pw.corr075.a05 = prediction.calc( read.depth, 0.5, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a1 = prediction.calc( read.depth, 1, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a2 = prediction.calc( read.depth, 2, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr075.a3 = prediction.calc( read.depth, 3, 0.75, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
#between sample correlation 0.95
pw.corr095.a05 = prediction.calc( read.depth, 0.5, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a1 = prediction.calc( read.depth, 1, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a2 = prediction.calc( read.depth, 2, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
pw.corr095.a3 = prediction.calc( read.depth, 3, 0.95, hyper, 50, save.obj = c("sigma", "Q"), thinning = 50,
step = 5e4 )
all.gains = lapply( list(pw.corr05.a05,pw.corr05.a1,pw.corr05.a2,pw.corr05.a3,
pw.corr075.a05,pw.corr075.a1,pw.corr075.a2,pw.corr075.a3,
pw.corr095.a05,pw.corr095.a1,pw.corr095.a2,pw.corr095.a3),
function(x) rowMeans( sapply( x, rowMeans ) ) )
plot.data = data.frame( read.depth = rep( read.depth,length(all.gains) ),
gain = unlist( all.gains ),
similarity = rep( as.factor(c(0.5,0.75,0.95)), each = 4*length(read.depth) ),
Q.power = rep( rep( as.factor(c(2,1,0.5,3)), each = length(read.depth) ), 3 ) )
ggplot( data = plot.data, aes(x=read.depth, y=gain, color=similarity, shape = Q.power) ) +
geom_line() + geom_point(size=5) + theme_bw() + xlab("Read depth") +
ylab("Gain in estimate accuracy" ) + scale_shape_manual( values = c(15:17,4)) +
scale_x_continuous( breaks = read.depth ) +
theme( axis.title = element_text( size = 18 ), axis.text= element_text( size = 15 ),
legend.title = element_text( size = 15, face = "bold" ),
plot.title = element_text( size = 15, face = "bold") )
Ordination with credible regions recover the clustering structure
The last thing we checked in the simulation studies is whether the ordination results generated from our model can detect a binary clustering pattern in the simulated dataset. Moreover, we want to see if the credible region will be consistent with the truth. The simulated dataset is generated by SimDirFactorContour. The distance between the two clusters is 3, which is much larger than the noise level (er=0.1).
library(DirFactor)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
sim.data.contour = SimDirFactorContour( strength = 3, 1000, n = 22, p = 68, m = 3, hyper )
mcmc.res.contour = DirFactor( sim.data.contour$data[[1]], hyper, step = 50000, thin=5 )
all.res = lapply( paste( mcmc.res.contour$save.path, seq( 20005,50000,5), sep = "_" ), readRDS )
all.corr = lapply( all.res, function(x) cov2cor( t(x$Y)%*%x$Y + diag( rep( x$er, ncol(x$Y) ) ) ) )
all.corr.use = all.corr[sample(1:length(all.corr),size = 1000, replace = T)]
statis.res = PlotStatis( all.corr.use, n.dim = 2, types = rep( c(1:2), each = 11 ), labels = 1:22 )
statis.res[[1]]
Two applications of DirFactor
GlobalPatterns dataset
The GlobalPatterns dataset (Caporaso et al. 2011) includes 26 biological samples derived from both human and environmental specimens. There are a total of 19,216 OTUs and the average total counts per biological sample is larger than 100,000. We collapsed all taxa OTUs to the genus level--a standard operation in microbiome studies--and yielded 996 distinct genera. We treated these genera as OTUs and fit our model to this collapsed dataset. We ran one MCMC chain for 50,000 iterations and recorded posterior samples every 10 iterations.
We first performed a cluster analysis of biological samples based on their microbial compositions. We then visualized the biological samples using ordination plots with the associated credible intervals. We specify the number of axes we considered in ordination as three. In both analyses, we choose to use the distance matrix calculated from the estimated probabilities of species to capture the relationship between biological samples. The distance metric is Bray-Curtis dissimilarity. The code for the clustering analysis and ordination plots are listed below.
library( vegan )
library( DirFactor )
library( phyloseq )
library( fpc )
data( GlobalPatterns )
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
gp.genus = tax_glom( GlobalPatterns, "Genus")
gp.metadata = sample_data( GlobalPatterns )
data = otu_table( gp.genus )
gp.mcmc = DirFactor( data, hyper, step = 50000, thinning=10 )
gp.all.res = lapply( paste( gp.mcmc$save.path, seq(10010,50000,10), sep = "_" ), readRDS )
#get bray-curtis distance matrix
all.bc.gp = lapply( gp.all.res, function(x){
weights = x$Q^2*(x$Q>0)*x$sigma
w.norm = t(weights)/colSums(weights)
vegdist( w.norm, method = "bray" )
})
use.idx = sample( 1:length(gp.all.res), 1000, replace = F )
#distatis
sub.bc.ls.gp = lapply( all.bc.gp[use.idx], as.matrix )
plot.bc.gp = PlotStatis( sub.bc.ls.gp, n.dim = 3, labels = gp.metadata$SampleType,
types = gp.metadata$SampleType )
plot.bc.gp[[1]]
plot.bc.gp[[2]]
plot.bc.gp[[3]]
#clustering plot
PlotClustering( all.bc.gp, gp.metadata$SampleType )
Ravel's vaginal microbiome dataset
We also consider a vaginal dataset (Ravel et al. 2011) which contains a larger number of biological samples (900) and a simpler bacterial community structure. These biological samples are derived from 54 healthy women. Multiple biological samples are taken from each individual, ranging from one to 32 biological samples per individual. Each woman has been classified, before our microbiome sequencing data were generated, into vaginal community state subtypes (CST). This dataset contains only species level taxonomic information and we filtered OTUs by occurrence. We only retain species with more than 5 reads in at least 10% of biological samples. This filtering resulted in 31 distinct OTUs. We ran one MCMC chain with 50,000 iterations.
We performed the same analyses as in the previous subsection and will load the MCMC results directly. The code for generating the figures are listed below:
library(DirFactor)
library(phyloseq)
data(JRphylo)
hyper = list( nv = 3, a.er = 1, b.er = 0.3, a1 = 3, a2 = 4, m = 22, alpha = 10, beta = 0 )
# filtering Ravel's data by occurence
JRfilt = genefilter_sample(JRphylo, filterfun_sample(function(x) x > 5), A = 0.1 * nsamples(JRphylo))
JR1 = prune_taxa(JRfilt, JRphylo)
ravel.mcmc = DirFactor( t(otu_table(JR1)), hyper, step = 50000, thinning = 10 )
ravel.all.res = lapply( paste( ravel.mcmc$save.path, seq( 10010, 50000, 10 ), sep = "_" ), readRDS )
#get bray-curtis distance matrix
all.bc.ravel = lapply( ravel.all.res, function(x){
weights = x$Q^2*(x$Q>0)*x$sigma
w.norm = t(weights)/colSums(weights)
vegdist( w.norm, method = "bray" )
})
use.idx = sample( 1:length(all.bc.ravel), 1000, replace = F )
#distatis
sub.bc.ls.ravel = lapply( all.bc.ravel[use.idx], as.matrix )
plot.bc.ravle = PlotStatis( sub.bc.ls.ravel, n.dim = 3,
types = sample_data(JR1)$CST )
plot.bc[[1]]
plot.bc[[2]]
plot.bc[[3]]
#clustering using bc
PlotClustering( all.bc.ravel, sample_data(JR1)$CST )
References
Caporaso, J. G., C. L. Lauber, W. A. Walters, D. Berg-Lyons, C. A. Lozupone, P. J. Turnbaugh, N. Fierer, and R. Knight. 2011. “Global Patterns of 16S RRNA Diversity at a Depth of Millions of Sequences Per Sample.” Proceedings of the National Academy of Sciences 108 (Supplement 1). National Acad Sciences: 4516–22.
Ravel, J., P. Gajer, Z. Abdo, G. M. Schneider, Sara S. K. K., S. L. McCulle, S. Karlebach, et al. 2011. “Vaginal Microbiome of Reproductive-Age Women.” Proceedings of the National Academy of Sciences 108 (Supplement 1). National Acad Sciences: 4680–7.
Ren, Boyu, Sergio Bacallado, Stefano Favaro, Susan Holmes, and Lorenzo Trippa. 2016. “Bayesian Nonparametric Ordination for the Analysis of Microbial Communities.” ArXiv Preprint ArXiv:1601.05156.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.