README.md
In mountainMath/dotdensity: Convenience Methods for Dot Density Maps
dotdensity
To install the package from GitHub use
remotes::install.packages('mountainMath/dotdensity')
Please refer to the documentation and reference guide for further details.
Why dotdensity?
This package provides several convenience function for muti-category dot-density maps. Dot-density maps are fairly straight-forward but there are a couple of pitfalls to pay attention to. This package attempts to
deal with some of these, in particular
- Scaling to more than 1 dot per unit (e.g. person)
- Re-aggregating and weighting through hierarchical geographic levels
Scaling
Dot-density maps can get very messy if we draw one dot of each person (or whatever the unit is). Scaling, by
only drawing 1 dot for every n people is a good way to alleviate this. But this process can introduce bias. Take
the example where we draw 1 dot for every 50 people of a category, say German speakers. Suppose German speakers
are distributed uniformly, so that each geographic area has 50 people, 20 of which are German speakers. Standard rounding will produce a
map without any German speakers, severely misrepresenting the data. To remedy this we should use a rounding algorithm that is unbiased. Statistical rounding, just like what is employed in the census, will produce unbiased results. So our convenience method that converts counts for categories (e.g. languages) in each geographic regions to dots does exactly that. We also shuffle the order of the dots to ensure that not all people of a certain category end up getting visually over-represented by drawing on top of all others.
Re-Aggregating
Census data a fine geographies may under-count the total number of people due to omissions of data because of privacy or quality concerns. We can deal with this by re-distributing the missing number of people found at a higher geographic aggregation level to lower levels. This will introduce some problems because we won't know exactly where to distribute the missing people, but it will ensure that the overall number of dots drawn accurately reflect overall counts. Typically we will weight the re-distribution by population, but other possibilities exist.
Furthermore, the same method allows the geographic weighting of data to fine block-level population data, where
we don't have general census variables available. Again, this kind of weighted re-distribution emphasise the problem with dot-density maps that they suggest an accuracy that does not exist, but on the other hand it produces very accurate representations of other aspects of the data, like general population density.
API Considerations
Dot-density maps re-aggregating the data down to census block level hits the CensusMapper API pretty hard, and
you may blow through your free API quota in no time. We may be able to find funding to increase the free quote in
the future, but for now it's a good thing to test the API call before executing. The example vignetts are safe to
run though, the data comes packaged with the R package and it will only hit the cache and not the CensusMapper server,
so no API points will get deducted. In fact, you don't even have to get your API key to run them.
Examples
This package has been designed to be used in conjunction with cancensus to pull in census data, but it also works with other data.
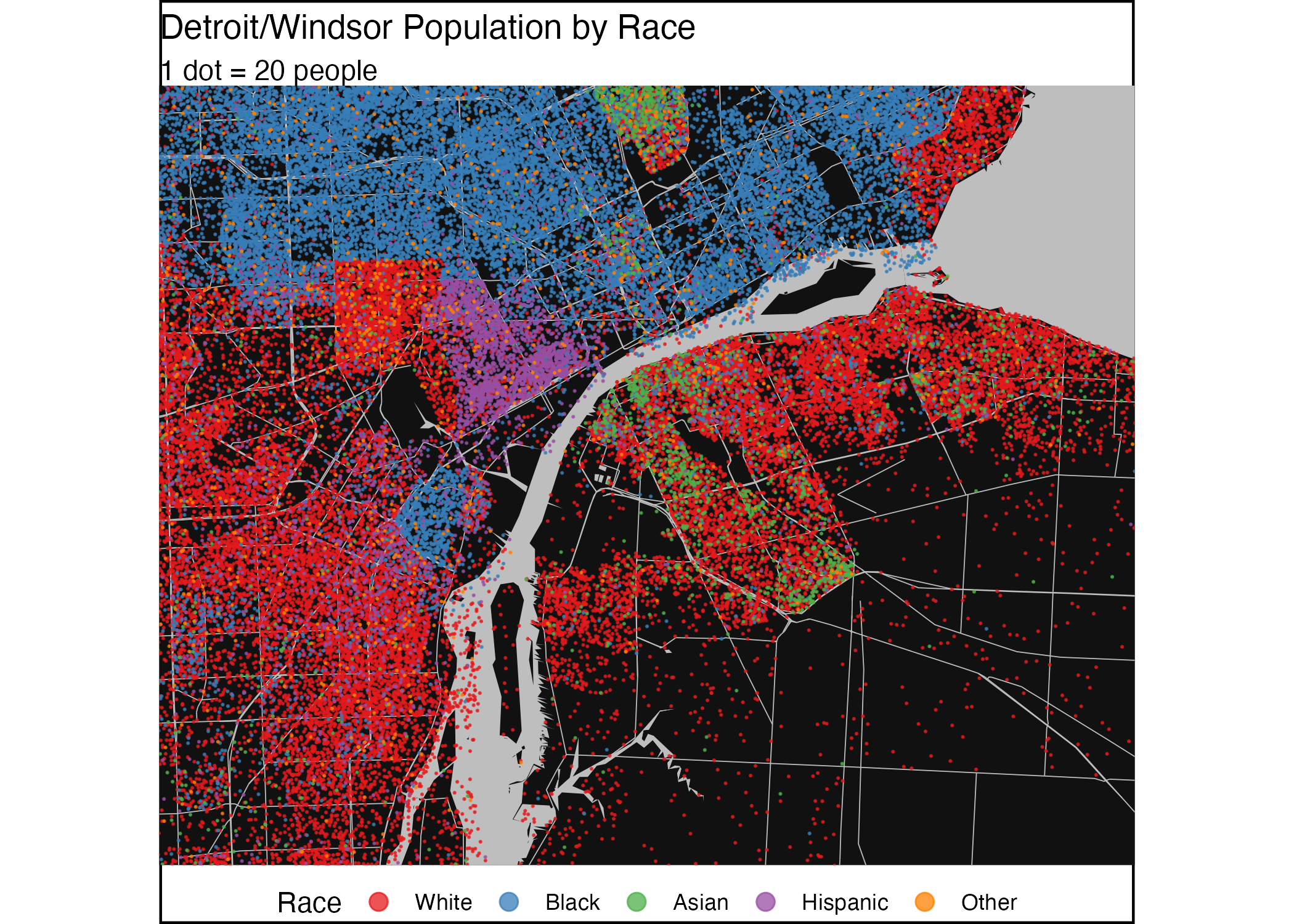
The main example is a cross-border map by ethnicity in the Detroit-Windsor region, where the data is pulled in using the cancensus package for Canada and the tidycensus package for the US. For details view the code.
The recent immigrants example was created using cancensus and dotdensity, it utilizes the census hierarchy for better placement of the dots. You can find more details in the vignette.
mountainMath/dotdensity documentation built on April 6, 2022, 5:51 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
dotdensity
To install the package from GitHub use
remotes::install.packages('mountainMath/dotdensity')
Please refer to the documentation and reference guide for further details.
Why dotdensity?
This package provides several convenience function for muti-category dot-density maps. Dot-density maps are fairly straight-forward but there are a couple of pitfalls to pay attention to. This package attempts to deal with some of these, in particular
- Scaling to more than 1 dot per unit (e.g. person)
- Re-aggregating and weighting through hierarchical geographic levels
Scaling
Dot-density maps can get very messy if we draw one dot of each person (or whatever the unit is). Scaling, by only drawing 1 dot for every n people is a good way to alleviate this. But this process can introduce bias. Take the example where we draw 1 dot for every 50 people of a category, say German speakers. Suppose German speakers are distributed uniformly, so that each geographic area has 50 people, 20 of which are German speakers. Standard rounding will produce a map without any German speakers, severely misrepresenting the data. To remedy this we should use a rounding algorithm that is unbiased. Statistical rounding, just like what is employed in the census, will produce unbiased results. So our convenience method that converts counts for categories (e.g. languages) in each geographic regions to dots does exactly that. We also shuffle the order of the dots to ensure that not all people of a certain category end up getting visually over-represented by drawing on top of all others.
Re-Aggregating
Census data a fine geographies may under-count the total number of people due to omissions of data because of privacy or quality concerns. We can deal with this by re-distributing the missing number of people found at a higher geographic aggregation level to lower levels. This will introduce some problems because we won't know exactly where to distribute the missing people, but it will ensure that the overall number of dots drawn accurately reflect overall counts. Typically we will weight the re-distribution by population, but other possibilities exist.
Furthermore, the same method allows the geographic weighting of data to fine block-level population data, where we don't have general census variables available. Again, this kind of weighted re-distribution emphasise the problem with dot-density maps that they suggest an accuracy that does not exist, but on the other hand it produces very accurate representations of other aspects of the data, like general population density.
API Considerations
Dot-density maps re-aggregating the data down to census block level hits the CensusMapper API pretty hard, and you may blow through your free API quota in no time. We may be able to find funding to increase the free quote in the future, but for now it's a good thing to test the API call before executing. The example vignetts are safe to run though, the data comes packaged with the R package and it will only hit the cache and not the CensusMapper server, so no API points will get deducted. In fact, you don't even have to get your API key to run them.
Examples
This package has been designed to be used in conjunction with cancensus to pull in census data, but it also works with other data.
The main example is a cross-border map by ethnicity in the Detroit-Windsor region, where the data is pulled in using the cancensus package for Canada and the tidycensus package for the US. For details view the code.
The recent immigrants example was created using cancensus and dotdensity, it utilizes the census hierarchy for better placement of the dots. You can find more details in the vignette.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.