README.md
In nadinesk/proPubBills: 'ProPublica' U.S. Congress Bills API wrapper
Overview
This R package, ProPubBills, is an API wrapper around the ProPublica API for U.S. Congressional Bills. Users can include their API key, U.S. Congress, branch, and offset ranges, to return a dataframe of all results within those parameters.
Explanation
Usage
getBills(key, congress, branch, type, numFrom, numTo)
Arguments
- key is the api key
- congress it the number of the U.S. Congress: for example, 114 for the 114th U.S. Congress
- branch is the House or the Senate branch
- type is the type of bills; options are introduced, updated, active, passed, enacted, vetoed
- numFrom is the offset number beginning range: for example, 1 will get the first 20 bills
- numTo is the offset number to: for example, 40 will get bills 40 to 60. Entering numFrom as 1 and numTo as 40 will return bills 1 to 60
Return Value
returns a dataframe with all bills and info from the API within the arguments’ parameters
Examples
These examples (code on Github here) compare the number of enacted legislations by political party, from the 116th Congress (current) to the 113th Congress. For Congresses 110 to 112, the examples show word clouds for the top 50 words all introduced bills.
Graphs
Here are the graphs created, with the code below
Parties and Enacted Legislation
House Enacted Legislation by Party, 113th to 115th Congress
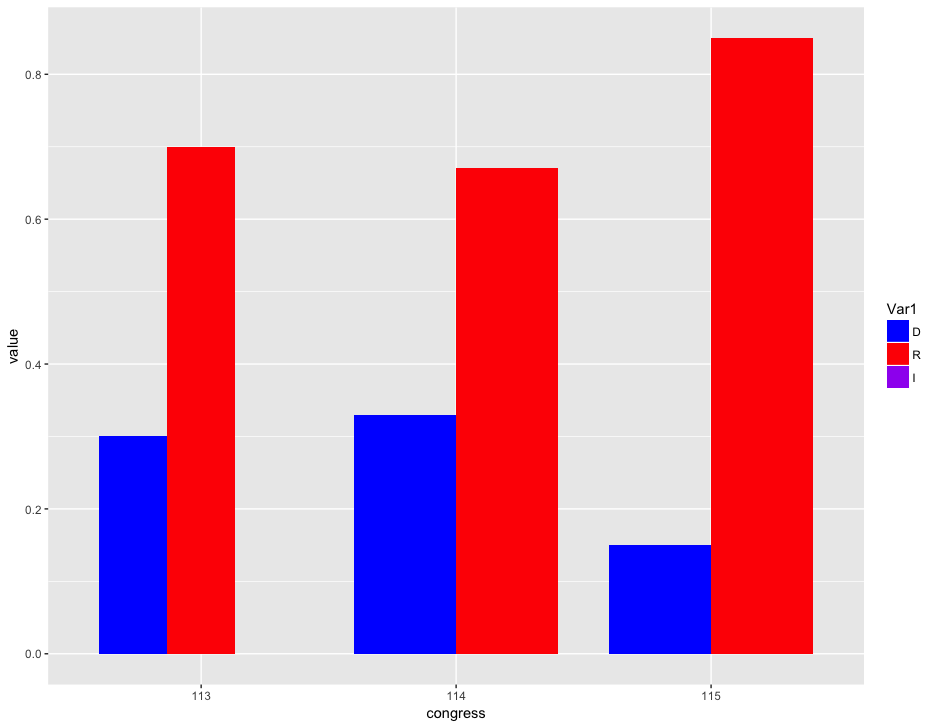
Senate Enacted Legislation by Party, 113th to 115th Congress
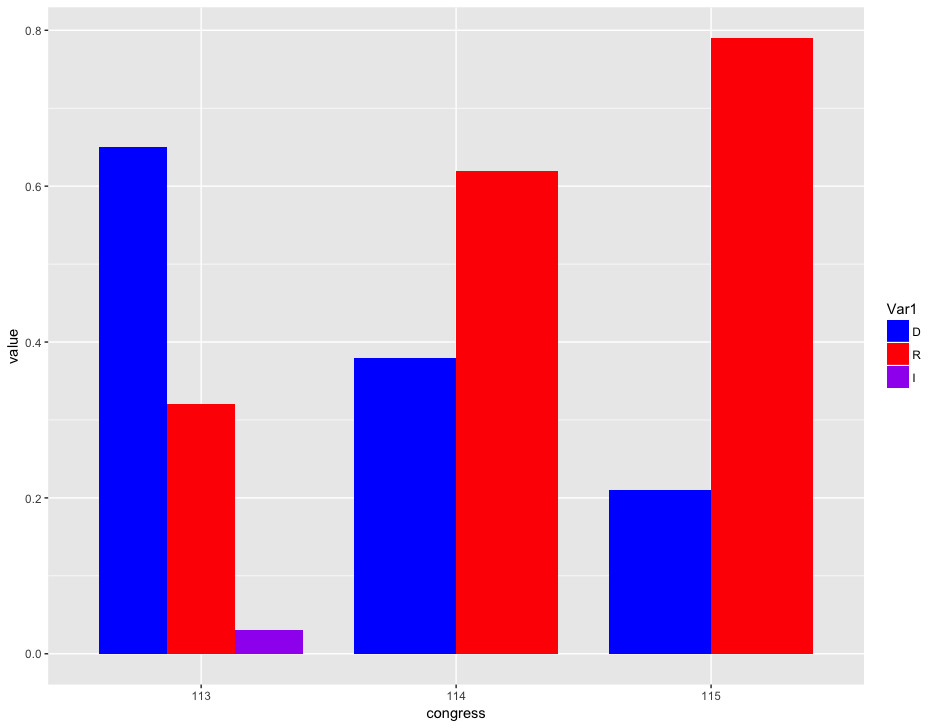
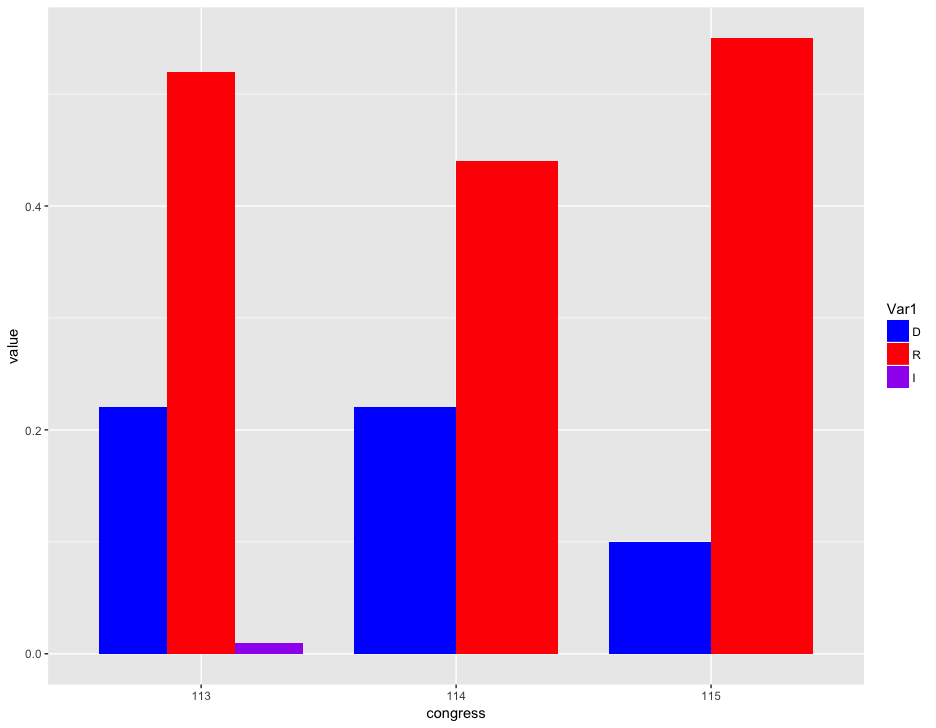
House and Senate Enacted Legislation by Party, 113th to 115th Congress
Code
library(proPubBills)
library(reshape2)
library(dplyr)
library(ggplot2)
library(stringr)
library(tm)
library(wordcloud)
library(RColorBrewer)
library(SnowballC)
api_key <- Sys.getenv('api_key')
h_enact_115 <- getBills(api_key, "115", "house","enacted",1,8000 )
s_enact_115 <- getBills(api_key, "115", "senate","enacted",1,8000 )
h_enact_114 <- getBills(api_key,"114", "house","enacted",1,8000 )
s_enact_114 <- getBills(api_key,"114", "senate","enacted",1,8000 )
h_enact_113 <- getBills(api_key,"113", "house","enacted",1,500 )
s_enact_113 <- getBills(api_key,"113", "senate","enacted",1,500 )
h_enact_115$dup <- duplicated(h_enact_115$bill_id)
s_enact_115$dup <- duplicated(s_enact_115$bill_id)
hs_enact_115 <- rbind(h_enact_115, s_enact_115) %>%
filter(dup == FALSE) %>%
filter(!(str_detect(latest_major_action, "^Presented")))
h_enact_114$dup <- duplicated(h_enact_114$bill_id)
s_enact_114$dup <- duplicated(s_enact_114$bill_id)
hs_enact_114 <- rbind(h_enact_114, s_enact_114) %>%
filter(dup == FALSE)
hs_enact_114_1 <- hs_enact_114 %>%
filter((str_detect(latest_major_action, "^Became")) | (str_detect(latest_major_action, "^By")) | (str_detect(latest_major_action, "^Referred")))
h_enact_113$dup <- duplicated(h_enact_113$bill_id)
s_enact_113$dup <- duplicated(s_enact_113$bill_id)
hs_enact_113 <- rbind(h_enact_113, s_enact_113) %>%
filter(dup == FALSE)
hs_115_party <- as.data.frame(table(hs_enact_115$sponsor_party, hs_enact_115$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '115')
hs_114_party <- as.data.frame(table(hs_enact_114_1$sponsor_party, hs_enact_114_1$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '114')
hs_113_party <- as.data.frame(table(hs_enact_113$sponsor_party, hs_enact_113$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '113')
hs_113_to_115 <- rbind(hs_115_party, hs_114_party, hs_113_party) %>%
mutate(chamber = ifelse(str_detect(Var2, "^h"),"H","S")) %>%
select(-Var2) %>%
group_by(Var1, congress, chamber,total_p) %>%
summarise_all(funs(sum)) %>%
arrange(congress)
hs_113_to_115_1 <- hs_113_to_115 %>%
group_by(congress, chamber) %>%
summarise(chamber_total_p = sum(Freq))
hs_113_to_115_2 <- hs_113_to_115 %>%
left_join(hs_113_to_115_1, by=c("congress", "chamber")) %>%
mutate(party_chamber_percent = round((Freq/chamber_total_p),2)) %>%
mutate(party_congress_percent = round((Freq/total_p),2)) %>%
data.frame()
hs_113_to_115_3 <- hs_113_to_115_2 %>%
select(Var1, congress, chamber, party_chamber_percent) %>%
melt(id.var=c("Var1", "congress","chamber"))
hs_113_to_115_3_h <- hs_113_to_115_3 %>%
filter(chamber == 'H')
hs_113_to_115_3_s <- hs_113_to_115_3 %>%
filter(chamber == 'S')
house_113_to_115_graph <- ggplot(hs_113_to_115_3_h, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
senate_113_to_115_graph <- ggplot(hs_113_to_115_3_s, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
hs_113_to_115_4 <- hs_113_to_115_2 %>%
select(Var1, congress, party_congress_percent) %>%
melt(id.var=c("Var1", "congress"))
house_senate_113_to_115_graph <- ggplot(hs_113_to_115_4, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
Wordclouds, 110th to 112th Congress
110th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
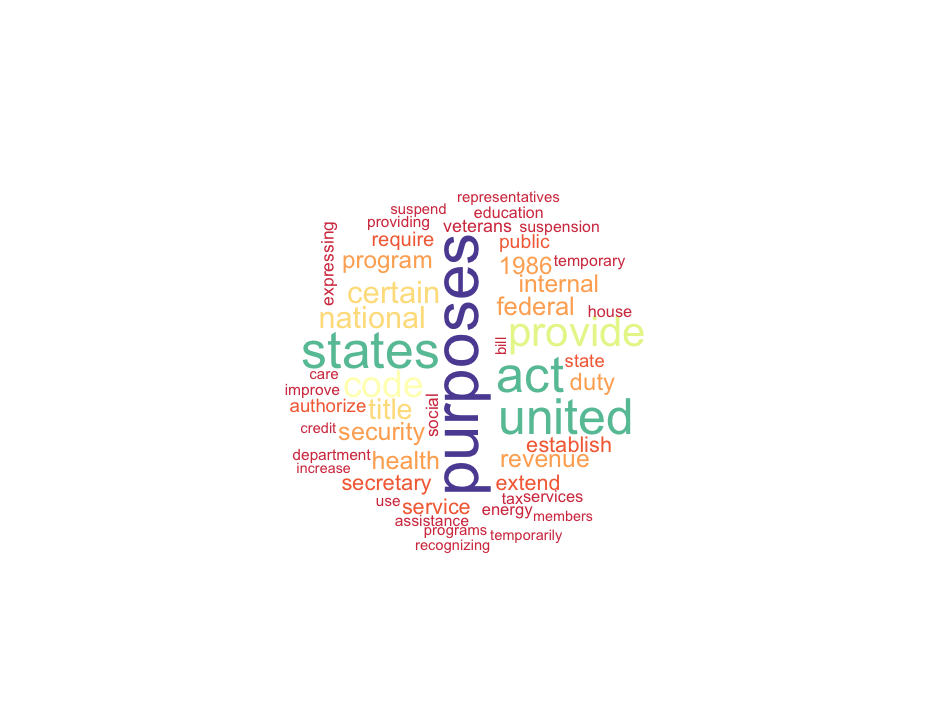
111th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
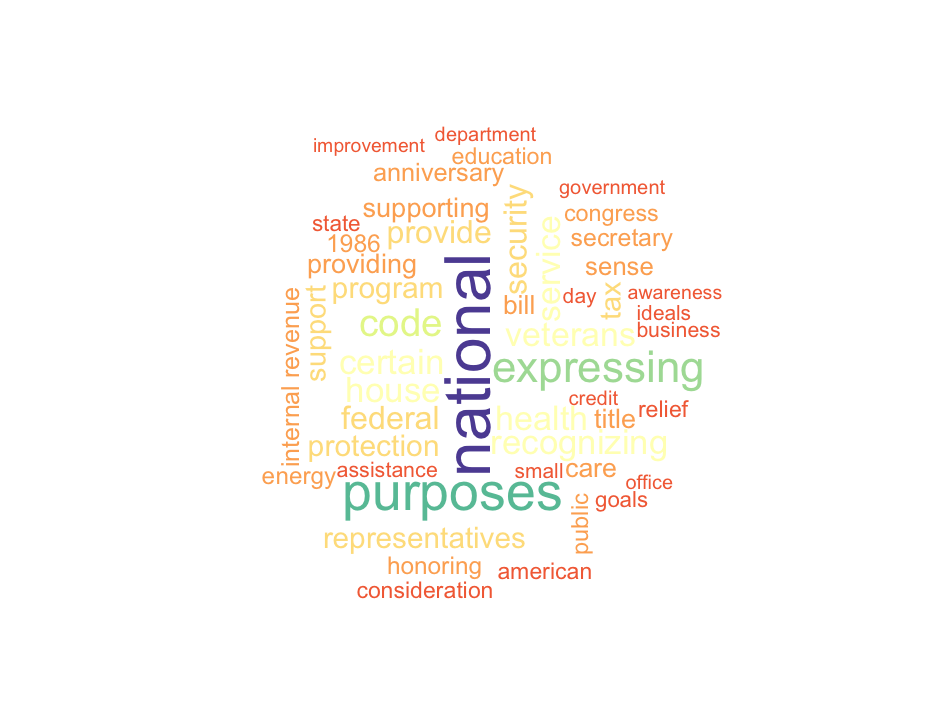
112th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
Code
h_intro_112 <- getBills(api_key,"112","house", "introduced", 1,12000)
s_intro_112 <- getBills(api_key,"112","senate", "introduced", 1,6000)
t112 <- as.data.frame(as.character(h_intro_112$title))
t112$`as.character(h_intro_112$title)` <- gsub('Act', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('2011', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('2012', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('United States', 'U.S.', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('amend', '', t112$`as.character(h_intro_112$title)`)
t112_2 <- paste(unlist(t112), collapse =" ")
t112_3 <- Corpus(VectorSource(t112_2))
t112_4 <- as.data.frame(as.character(t112_3))
t112_5 <- tm_map(t112_3, PlainTextDocument)
t112_6 <- tm_map(t112_5, removePunctuation)
t112_7 <- tm_map(t112_6, removeWords, stopwords('english'))
pal2 <- brewer.pal(11,"Spectral")
wordcloud_112 <- wordcloud(t112_7, max.words = 50, random.order = FALSE, color=pal2)
wordcloud_112
h_intro_111 <- getBills(api_key,"111","house", "introduced", 1,12000)
s_intro_111 <- getBills(api_key,"111","senate", "introduced", 1,6000)
t111 <- as.data.frame(as.character(h_intro_111$title))
t111$`as.character(h_intro_111$title)` <- gsub('Act', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('2010', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('2009', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('United States', 'U.S.', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('amend', '', t111$`as.character(h_intro_111$title)`)
t111_2 <- paste(unlist(t111), collapse =" ")
t111_3 <- Corpus(VectorSource(t111_2))
t111_5 <- tm_map(t111_3, PlainTextDocument)
t111_6 <- tm_map(t111_5, removePunctuation)
t111_7 <- tm_map(t111_6, removeWords, stopwords('english'))
wordcloud_111 <- wordcloud(t111_7, max.words = 50, random.order = FALSE, colors=pal2)
h_intro_110 <- getBills(api_key,"110","house", "introduced", 1,12000)
s_intro_110 <- getBills(api_key,"110","senate", "introduced", 1,6000)
t110 <- as.data.frame(as.character(h_intro_110$title))
t110$`as.character(h_intro_111$title)` <- gsub('Act', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('2010', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('2009', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('United States', 'U.S.', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('amend', '', t110$`as.character(h_intro_110$title)`)
t110_2 <- paste(unlist(t110), collapse =" ")
t110_3 <- Corpus(VectorSource(t110_2))
t110_5 <- tm_map(t110_3, PlainTextDocument)
t110_6 <- tm_map(t110_5, removePunctuation)
t110_7 <- tm_map(t110_6, removeWords, stopwords('english'))
wordcloud_110 <- wordcloud(t110_7, max.words = 50, random.order = FALSE, colors=pal2)
Contributing
Bug reports and pull requests are welcome on GitHub here. This project is intended to be a safe, welcoming space for collaboration, and contributors are expected to adhere to the Contributor Covenant code of conduct.
nadinesk/proPubBills documentation built on May 29, 2019, 6:40 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Overview
This R package, ProPubBills, is an API wrapper around the ProPublica API for U.S. Congressional Bills. Users can include their API key, U.S. Congress, branch, and offset ranges, to return a dataframe of all results within those parameters.
Explanation
Usage
getBills(key, congress, branch, type, numFrom, numTo)
Arguments
- key is the api key
- congress it the number of the U.S. Congress: for example, 114 for the 114th U.S. Congress
- branch is the House or the Senate branch
- type is the type of bills; options are introduced, updated, active, passed, enacted, vetoed
- numFrom is the offset number beginning range: for example, 1 will get the first 20 bills
- numTo is the offset number to: for example, 40 will get bills 40 to 60. Entering numFrom as 1 and numTo as 40 will return bills 1 to 60
Return Value
returns a dataframe with all bills and info from the API within the arguments’ parameters
Examples
These examples (code on Github here) compare the number of enacted legislations by political party, from the 116th Congress (current) to the 113th Congress. For Congresses 110 to 112, the examples show word clouds for the top 50 words all introduced bills.
Graphs
Here are the graphs created, with the code below
Parties and Enacted Legislation
House Enacted Legislation by Party, 113th to 115th Congress
Senate Enacted Legislation by Party, 113th to 115th Congress
House and Senate Enacted Legislation by Party, 113th to 115th Congress
Code
library(proPubBills)
library(reshape2)
library(dplyr)
library(ggplot2)
library(stringr)
library(tm)
library(wordcloud)
library(RColorBrewer)
library(SnowballC)
api_key <- Sys.getenv('api_key')
h_enact_115 <- getBills(api_key, "115", "house","enacted",1,8000 )
s_enact_115 <- getBills(api_key, "115", "senate","enacted",1,8000 )
h_enact_114 <- getBills(api_key,"114", "house","enacted",1,8000 )
s_enact_114 <- getBills(api_key,"114", "senate","enacted",1,8000 )
h_enact_113 <- getBills(api_key,"113", "house","enacted",1,500 )
s_enact_113 <- getBills(api_key,"113", "senate","enacted",1,500 )
h_enact_115$dup <- duplicated(h_enact_115$bill_id)
s_enact_115$dup <- duplicated(s_enact_115$bill_id)
hs_enact_115 <- rbind(h_enact_115, s_enact_115) %>%
filter(dup == FALSE) %>%
filter(!(str_detect(latest_major_action, "^Presented")))
h_enact_114$dup <- duplicated(h_enact_114$bill_id)
s_enact_114$dup <- duplicated(s_enact_114$bill_id)
hs_enact_114 <- rbind(h_enact_114, s_enact_114) %>%
filter(dup == FALSE)
hs_enact_114_1 <- hs_enact_114 %>%
filter((str_detect(latest_major_action, "^Became")) | (str_detect(latest_major_action, "^By")) | (str_detect(latest_major_action, "^Referred")))
h_enact_113$dup <- duplicated(h_enact_113$bill_id)
s_enact_113$dup <- duplicated(s_enact_113$bill_id)
hs_enact_113 <- rbind(h_enact_113, s_enact_113) %>%
filter(dup == FALSE)
hs_115_party <- as.data.frame(table(hs_enact_115$sponsor_party, hs_enact_115$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '115')
hs_114_party <- as.data.frame(table(hs_enact_114_1$sponsor_party, hs_enact_114_1$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '114')
hs_113_party <- as.data.frame(table(hs_enact_113$sponsor_party, hs_enact_113$bill_type)) %>%
mutate(total_p = sum(Freq)) %>%
mutate(congress = '113')
hs_113_to_115 <- rbind(hs_115_party, hs_114_party, hs_113_party) %>%
mutate(chamber = ifelse(str_detect(Var2, "^h"),"H","S")) %>%
select(-Var2) %>%
group_by(Var1, congress, chamber,total_p) %>%
summarise_all(funs(sum)) %>%
arrange(congress)
hs_113_to_115_1 <- hs_113_to_115 %>%
group_by(congress, chamber) %>%
summarise(chamber_total_p = sum(Freq))
hs_113_to_115_2 <- hs_113_to_115 %>%
left_join(hs_113_to_115_1, by=c("congress", "chamber")) %>%
mutate(party_chamber_percent = round((Freq/chamber_total_p),2)) %>%
mutate(party_congress_percent = round((Freq/total_p),2)) %>%
data.frame()
hs_113_to_115_3 <- hs_113_to_115_2 %>%
select(Var1, congress, chamber, party_chamber_percent) %>%
melt(id.var=c("Var1", "congress","chamber"))
hs_113_to_115_3_h <- hs_113_to_115_3 %>%
filter(chamber == 'H')
hs_113_to_115_3_s <- hs_113_to_115_3 %>%
filter(chamber == 'S')
house_113_to_115_graph <- ggplot(hs_113_to_115_3_h, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
senate_113_to_115_graph <- ggplot(hs_113_to_115_3_s, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
hs_113_to_115_4 <- hs_113_to_115_2 %>%
select(Var1, congress, party_congress_percent) %>%
melt(id.var=c("Var1", "congress"))
house_senate_113_to_115_graph <- ggplot(hs_113_to_115_4, aes(x=congress, y=value, group=Var1, fill=Var1)) +
geom_bar(stat="identity", position="dodge", size=0.25, width=0.8) +
scale_fill_manual(values=c("blue","red", "purple"))
Wordclouds, 110th to 112th Congress
110th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
111th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
112th Congress, Introduced Bills' Titles Wordcloud: Top 50 Words
Code
h_intro_112 <- getBills(api_key,"112","house", "introduced", 1,12000)
s_intro_112 <- getBills(api_key,"112","senate", "introduced", 1,6000)
t112 <- as.data.frame(as.character(h_intro_112$title))
t112$`as.character(h_intro_112$title)` <- gsub('Act', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('2011', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('2012', '', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('United States', 'U.S.', t112$`as.character(h_intro_112$title)`)
t112$`as.character(h_intro_112$title)` <- gsub('amend', '', t112$`as.character(h_intro_112$title)`)
t112_2 <- paste(unlist(t112), collapse =" ")
t112_3 <- Corpus(VectorSource(t112_2))
t112_4 <- as.data.frame(as.character(t112_3))
t112_5 <- tm_map(t112_3, PlainTextDocument)
t112_6 <- tm_map(t112_5, removePunctuation)
t112_7 <- tm_map(t112_6, removeWords, stopwords('english'))
pal2 <- brewer.pal(11,"Spectral")
wordcloud_112 <- wordcloud(t112_7, max.words = 50, random.order = FALSE, color=pal2)
wordcloud_112
h_intro_111 <- getBills(api_key,"111","house", "introduced", 1,12000)
s_intro_111 <- getBills(api_key,"111","senate", "introduced", 1,6000)
t111 <- as.data.frame(as.character(h_intro_111$title))
t111$`as.character(h_intro_111$title)` <- gsub('Act', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('2010', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('2009', '', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('United States', 'U.S.', t111$`as.character(h_intro_111$title)`)
t111$`as.character(h_intro_111$title)` <- gsub('amend', '', t111$`as.character(h_intro_111$title)`)
t111_2 <- paste(unlist(t111), collapse =" ")
t111_3 <- Corpus(VectorSource(t111_2))
t111_5 <- tm_map(t111_3, PlainTextDocument)
t111_6 <- tm_map(t111_5, removePunctuation)
t111_7 <- tm_map(t111_6, removeWords, stopwords('english'))
wordcloud_111 <- wordcloud(t111_7, max.words = 50, random.order = FALSE, colors=pal2)
h_intro_110 <- getBills(api_key,"110","house", "introduced", 1,12000)
s_intro_110 <- getBills(api_key,"110","senate", "introduced", 1,6000)
t110 <- as.data.frame(as.character(h_intro_110$title))
t110$`as.character(h_intro_111$title)` <- gsub('Act', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('2010', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('2009', '', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('United States', 'U.S.', t110$`as.character(h_intro_110$title)`)
t110$`as.character(h_intro_111$title)` <- gsub('amend', '', t110$`as.character(h_intro_110$title)`)
t110_2 <- paste(unlist(t110), collapse =" ")
t110_3 <- Corpus(VectorSource(t110_2))
t110_5 <- tm_map(t110_3, PlainTextDocument)
t110_6 <- tm_map(t110_5, removePunctuation)
t110_7 <- tm_map(t110_6, removeWords, stopwords('english'))
wordcloud_110 <- wordcloud(t110_7, max.words = 50, random.order = FALSE, colors=pal2)
Contributing
Bug reports and pull requests are welcome on GitHub here. This project is intended to be a safe, welcoming space for collaboration, and contributors are expected to adhere to the Contributor Covenant code of conduct.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.