README.md
In opardo/dlmRStan: Dynamic Linear Models, using RStan.
dlmRStan
Author
Carlos Omar Pardo Gomez (cop2108@columbia.edu)
Overview
Bayesian linear model in a time series context, with a different beta for each time period, and considering a correlation structure between all of them. This kind of models are also regularly known as dynamic linear models (dlm).
This package uses RStan to develop and run the MCMC algorithm.
Model
Be one dependent random variable yt, and a vector of independent variables xt, so P(yt|xt) makes sense. It is important to remark that the subindex t is not exchangable, that is to say, the subindex represents the chronological order. Then, this package's model can be expressed as
&space;\\&space;\sigma^2&space;&\sim&space;Gamma(\sigma_\gamma,&space;\sigma_\delta)&space;\\&space;\beta_t&space;|&space;\beta_{t-1},&space;AF&space;&\sim&space;\mathcal{N}(\beta_{t-1},&space;AF&space;*&space;B),&space;t&space;\geq&space;2\\&space;\beta_1&space;|&space;\mu_1,&space;AF&space;&\sim&space;\mathcal{N}(\mu_1,&space;AF&space;*&space;B)&space;\\&space;\mu_1&space;&\sim&space;\mathcal{N}(b,B)&space;\\&space;AF&space;&\sim&space;Beta(AF_\gamma,AF_\delta).&space;\end{aligned})
This package introduces a novelty with regard to other dlm packages: it allows the modeler to constraint the beta and squared-sigma values with the following restrictions:
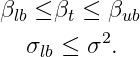
Installation
First of all, you must install RTools, since the algorithm runs in C++.
Then you should run the following code to install the package from Github.
install.packages("devtools")
library(devtools)
install_github("opardo/dlmRStan")
Example
Context
The next example takes place in the market research context, trying to explain corporate brand's Awareness with the TV investment data. Awareness is a KPI defined as the percentage of people who declares to know the corporate brand. The TV investment is in Adstocked GRPs, an unit which removes the currency fluctuations, and takes into account how many people and how frequently were exposed to the ad. Also assumes the ad is reminded for some time, even if people don't see it again.
For this specific case, 4 covariates are used:
- Main Thrust: commercials about corporate brand's image
- Sub-brands: advertising for specific products
- Competitor 1
- Competitor 2
Awareness is a special metric because the competitors' effect is almost always non-negative. Worst case scenario, customers don't associate the competitors' ads with the studied brand and the contribution to Awareness is 0. But in other cases, there is a confussion effect within the category, and the competitors' contribution is positive. So it makes sense to set a restriction about non-negative betas.
Also, there is a belief Awareness' base level exists. That means, there is a group of people who will recognize the brand, even if they didn't see any ad. In the model this is captured by the Intercept, so we expect it to be positive and lower than Awareness.
Code
The dataset is contained inside the package and is called in the next way:
# Load package
library(dlmRStan)
# Load Market Research data
data("dlmRStan3")
dataset <- dlmRStan3
We have defined the Awareness as the dependent variable, and the intercept's presence has been explained, so the formula should be
formula <- awareness ~ .
If the intercept's presence didn't make sense, formula would be written
formula <- awareness ~ . + 0
Then, the model is fitted, restricting some parameters' values because of the context. Also the MCMC algorithm's parameters are modified for the fitting process to run faster.
model <- dlmRStan(
formula = formula,
dataset = dataset,
betas_range = c(0, 0.07),
intercept_range = c(30,50),
chains = 4,
iter = 1000,
warmup = 500
)
Once the model is fitted, a validation is done. This includes
- Mean squared errors (MSE),
- Mean absolute errors (MAE)
- Soft pseudo-squared R (squared correlation between the real data and the model's mean prediction)
- Hard pseudo-squared R (squared correlation between the real data's deltas and the model's ones, regarding the previous period)
- loo
- waic
```{r}s
model$validation
Some standard insights are extracted and ploted, including the model's adjustment, the mean betas' values (efficiencies) and the covariates' contribution for each period.
```{r}
model$insights$plots



The data used to create these plots is accessible by writing
```{r}s
model$insights$tables
Finally, if an uncertainity's measure is needed, the standard deviation for each parameter estimation can be found in
```{r}s
model$fit$parameters$beta_sd
model$fit$parameters$contribution_sd
Test
TODO
opardo/dlmRStan documentation built on May 20, 2019, 7:59 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
dlmRStan
Author
Carlos Omar Pardo Gomez (cop2108@columbia.edu)
Overview
Bayesian linear model in a time series context, with a different beta for each time period, and considering a correlation structure between all of them. This kind of models are also regularly known as dynamic linear models (dlm).
This package uses RStan to develop and run the MCMC algorithm.
Model
Be one dependent random variable yt, and a vector of independent variables xt, so P(yt|xt) makes sense. It is important to remark that the subindex t is not exchangable, that is to say, the subindex represents the chronological order. Then, this package's model can be expressed as
This package introduces a novelty with regard to other dlm packages: it allows the modeler to constraint the beta and squared-sigma values with the following restrictions:
Installation
First of all, you must install RTools, since the algorithm runs in C++.
Then you should run the following code to install the package from Github.
install.packages("devtools")
library(devtools)
install_github("opardo/dlmRStan")
Example
Context
The next example takes place in the market research context, trying to explain corporate brand's Awareness with the TV investment data. Awareness is a KPI defined as the percentage of people who declares to know the corporate brand. The TV investment is in Adstocked GRPs, an unit which removes the currency fluctuations, and takes into account how many people and how frequently were exposed to the ad. Also assumes the ad is reminded for some time, even if people don't see it again.
For this specific case, 4 covariates are used: - Main Thrust: commercials about corporate brand's image - Sub-brands: advertising for specific products - Competitor 1 - Competitor 2
Awareness is a special metric because the competitors' effect is almost always non-negative. Worst case scenario, customers don't associate the competitors' ads with the studied brand and the contribution to Awareness is 0. But in other cases, there is a confussion effect within the category, and the competitors' contribution is positive. So it makes sense to set a restriction about non-negative betas.
Also, there is a belief Awareness' base level exists. That means, there is a group of people who will recognize the brand, even if they didn't see any ad. In the model this is captured by the Intercept, so we expect it to be positive and lower than Awareness.
Code
The dataset is contained inside the package and is called in the next way:
# Load package
library(dlmRStan)
# Load Market Research data
data("dlmRStan3")
dataset <- dlmRStan3
We have defined the Awareness as the dependent variable, and the intercept's presence has been explained, so the formula should be
formula <- awareness ~ .
If the intercept's presence didn't make sense, formula would be written
formula <- awareness ~ . + 0
Then, the model is fitted, restricting some parameters' values because of the context. Also the MCMC algorithm's parameters are modified for the fitting process to run faster.
model <- dlmRStan(
formula = formula,
dataset = dataset,
betas_range = c(0, 0.07),
intercept_range = c(30,50),
chains = 4,
iter = 1000,
warmup = 500
)
Once the model is fitted, a validation is done. This includes - Mean squared errors (MSE), - Mean absolute errors (MAE) - Soft pseudo-squared R (squared correlation between the real data and the model's mean prediction) - Hard pseudo-squared R (squared correlation between the real data's deltas and the model's ones, regarding the previous period) - loo - waic ```{r}s model$validation
Some standard insights are extracted and ploted, including the model's adjustment, the mean betas' values (efficiencies) and the covariates' contribution for each period.
```{r}
model$insights$plots
The data used to create these plots is accessible by writing ```{r}s model$insights$tables
Finally, if an uncertainity's measure is needed, the standard deviation for each parameter estimation can be found in
```{r}s
model$fit$parameters$beta_sd
model$fit$parameters$contribution_sd
Test
TODO
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.