README.md
In sbohora/sAUC: Semi-parametric Area Under the Curve (AUC) regression

Semi-parametric Area Under the Curve (sAUC) Regression
Perform AUC analyses with discrete covariates and a semi-parametric estimation
Installation
# This package has not been submitted to CRAN yet. You can install its development version from GitHub:
# install.packages("devtools")
devtools::install_github("sbohora/sAUC")
If any bug is encountered, please raise an issue with a minimal reproducible example on github.
What is sAUC model and why?
In many applications, comparing two groups while adjusting for multiple covariates is desired for the statistical analysis. For instance, in clinical trials, adjusting for covariates is a necessary aspect of the statistical analysis in order to improve the precision of the treatment comparison and to assess effect modification. sAUC is a semi-parametric AUC regression model to compare the effect of two treatment groups in the intended non-normal outcome while adjusting for discrete covariates. More detailed reasons on what it is and why it is proposed are outlined in this paper. A major reason behind the development of this method is that this method is computationally simple and is based on closed-form parameter and standard error estimation.
Model
We consider applications that compare a response variable y between two groups (A and B) while adjusting for k categorical covariates 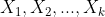 . The response variable y is a continuous or ordinal variable that is not normally distributed. Without loss of generality, we assume each covariate is coded such that
. The response variable y is a continuous or ordinal variable that is not normally distributed. Without loss of generality, we assume each covariate is coded such that 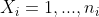 ,for
,for  . For each combination of the levels of the covariates, we define the Area Under the ROC curve (AUC) in the following way:
. For each combination of the levels of the covariates, we define the Area Under the ROC curve (AUC) in the following way:
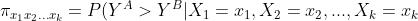 +%5Cfrac%7B1%7D%7B2%7D%20P(Y%5EA%3DY%5EB%7CX_1%3Dx_1,X_2%3Dx_2,...,X_k%3Dx_k%20),)
+%5Cfrac%7B1%7D%7B2%7D%20P(Y%5EA%3DY%5EB%7CX_1%3Dx_1,X_2%3Dx_2,...,X_k%3Dx_k%20),)
where  , and
, and 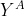 and
and 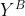 are two randomly chosen observations from Group A and B, respectively. The second term in the above equation is for the purpose of accounting ties.
are two randomly chosen observations from Group A and B, respectively. The second term in the above equation is for the purpose of accounting ties.
For each covariate 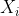 , without loss of generality, we use the last category as the reference category and define (
, without loss of generality, we use the last category as the reference category and define (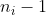 ) dummy variables
) dummy variables 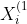 %7D,X_i%5E%7B(2)%7D,...,X_i%5E%7B(n_i-1)%7D) such that
%7D,X_i%5E%7B(2)%7D,...,X_i%5E%7B(n_i-1)%7D) such that
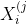 %7D%20(x)%3D%201,%20if%20j%20%3D%20x) and
%7D%20(x)%3D%201,%20if%20j%20%3D%20x) and 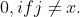
where 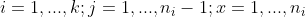 . We model the association between AUC
. We model the association between AUC 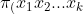 ) and covariates using a logistic model. Such a model specifies that the logit of ) is a linear combination of terms that are products of the dummy variables defined above. Specifically,
) and covariates using a logistic model. Such a model specifies that the logit of ) is a linear combination of terms that are products of the dummy variables defined above. Specifically,
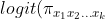 %3DZ_%7B(x_1%20x_2...x_k%20)%7D%20%5Cboldsymbol%7B%5Cbeta%7D,)
%3DZ_%7B(x_1%20x_2...x_k%20)%7D%20%5Cboldsymbol%7B%5Cbeta%7D,)
where 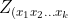 %7D) is a row vector whose elements are zeroes or ones and are products of
%7D) is a row vector whose elements are zeroes or ones and are products of 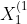 %7D%20(x_1%20),...,X_1%5E%7B(n_i-1)%20%7D%20(x_1),...,X_k%5E%7B(1)%7D%20(x_k),...,X_k%5E%7B(n_k-1)%7D%20(x_k)), and
%7D%20(x_1%20),...,X_1%5E%7B(n_i-1)%20%7D%20(x_1),...,X_k%5E%7B(1)%7D%20(x_k),...,X_k%5E%7B(n_k-1)%7D%20(x_k)), and 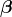 is a column vector of nonrandom unknown parameters. Now, define a column vector
is a column vector of nonrandom unknown parameters. Now, define a column vector 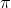 by stacking up
by stacking up 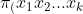 ) and define a matrix Z by stacking up
) and define a matrix Z by stacking up 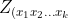 %7D), as
%7D), as 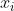 ranges from 1 to
ranges from 1 to 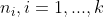 , our final model is
, our final model is
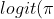 %3DZ%5Cboldsymbol%7B%5Cbeta%7D%20...(1))
%3DZ%5Cboldsymbol%7B%5Cbeta%7D%20...(1))
The reason for us to use a logit transformation of the AUC instead of using the original AUC is for variance stabilization. We will illustrate the above general model using examples.
Estimation
First, we denote the number of observations with covariates 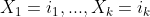 in groups A and B by
in groups A and B by 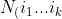 %5EA) and %5EB), respectively. We assume both %5EA) and %5EB) are greater than zero in the following development. An unbiased estimator of
%5EA) and %5EB), respectively. We assume both %5EA) and %5EB) are greater than zero in the following development. An unbiased estimator of 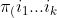 ) proposed by Mann and Whitney (1947) is
) proposed by Mann and Whitney (1947) is
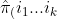 %3D%5Cfrac%7B%5Csum_%7Bl%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EA%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EB%7D%20I_%7Blj%7D%7D%7BN_%7Bi_1...i_k%7D%5EA%20N_%7Bi_1...i_k%7D%5EB%7D,)
%3D%5Cfrac%7B%5Csum_%7Bl%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EA%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EB%7D%20I_%7Blj%7D%7D%7BN_%7Bi_1...i_k%7D%5EA%20N_%7Bi_1...i_k%7D%5EB%7D,)
where
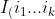 ;%20lj%20%3D%201) if
;%20lj%20%3D%201) if 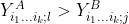
and
;%20lj%20%3D%20%5Cfrac%7B1%7D%7B2%7D) if 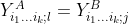
and
;%20lj%20%3D%200) if 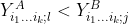
and 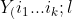 %5EA) and
%5EA) and 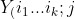 %5EB) are observations with in groups A and B, respectively. Delong, Delong and Clarke-Pearson (1988) have shown that
%5EB) are observations with in groups A and B, respectively. Delong, Delong and Clarke-Pearson (1988) have shown that
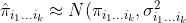 ).
).
In order to obtain an estimator for  , they first computed
, they first computed
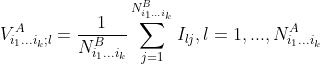
and
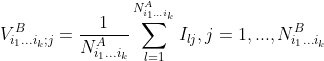 .
.
Then, an estimate of the variance of the nonparametric AUC was
 %5E2%7D%7BN_%7Bi_1...i_k%7D%5EA%7D%20+%20%5Cfrac%7B(s_%7Bi_1...i_k%7D%5EB%20)%5E2%7D%7BN_%7Bi_1...i_k%7D%5EB%7D),
%5E2%7D%7BN_%7Bi_1...i_k%7D%5EA%7D%20+%20%5Cfrac%7B(s_%7Bi_1...i_k%7D%5EB%20)%5E2%7D%7BN_%7Bi_1...i_k%7D%5EB%7D),
where
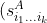 %5E2) and
%5E2) and 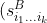 %5E2) were the sample variances of
%5E2) were the sample variances of
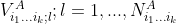 and
and 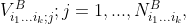 respectively. Clearly, we need both
respectively. Clearly, we need both 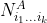 and
and 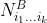 are greater than two in order to compute
are greater than two in order to compute 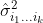 .
.
Now, in order to estimate parameters in Model (1), we first derive the asymptotic variance of 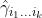 using the delta method, which results in
using the delta method, which results in
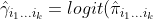 %20%5Capprox%20N(logit(%5Cpi_%7Bi_1...i_k%7D),%5Ctau_%7Bi_1...i_k%7D%5E2),)
%20%5Capprox%20N(logit(%5Cpi_%7Bi_1...i_k%7D),%5Ctau_%7Bi_1...i_k%7D%5E2),)
where  %5E2%7D)
%5E2%7D)
Rewriting the above model, we obtain
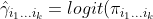 %20%3DZ_%7Bi_1...i_k%7D%20%5Cboldsymbol%7B%5Cbeta%7D%20+%20%5Cepsilon_%7Bi_1...i_k%7D)
%20%3DZ_%7Bi_1...i_k%7D%20%5Cboldsymbol%7B%5Cbeta%7D%20+%20%5Cepsilon_%7Bi_1...i_k%7D)
where,
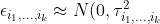 ). Then, by stacking up the
). Then, by stacking up the 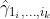 to be
to be
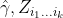 to be
to be 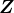 , and
, and 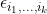 to be
to be
 , we have
, we have
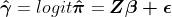 ,
,
where,  %3D0) and
%3D0) and 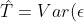 %3Ddiag(%5Chat%7B%5Ctau%7D_%7Bi_1...%20i_k%7D%5E2)) which is a diagonal matrix. Finally, by using the generalized least squares method, we estimate the parameters β and its variance-covariance matrix as follows;
%3Ddiag(%5Chat%7B%5Ctau%7D_%7Bi_1...%20i_k%7D%5E2)) which is a diagonal matrix. Finally, by using the generalized least squares method, we estimate the parameters β and its variance-covariance matrix as follows;
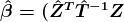 %7D%5E%7B-1%7D%20Z%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%5Chat%7B%5Cgamma%7D%7D)
%7D%5E%7B-1%7D%20Z%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%5Chat%7B%5Cgamma%7D%7D)
and
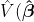 %20%3D%20%5Cboldsymbol%7B%7B(%5Chat%7BZ%7D%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%20Z)%7D%5E%7B-1%7D%7D)
%20%3D%20%5Cboldsymbol%7B%7B(%5Chat%7BZ%7D%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%20Z)%7D%5E%7B-1%7D%7D)
The above equations can be used to construct a 100(1-α)% Wald confidence intervals for 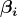 using formula
using formula
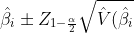 %7D),
%7D),
where 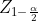 is the
is the 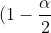 %5E%7Bth%7D) quantile of the standard normal distribution. Equivalently, we reject
%5E%7Bth%7D) quantile of the standard normal distribution. Equivalently, we reject
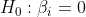 if
if 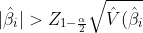 %7D.),
%7D.),
The p-value for testing 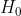 is
is 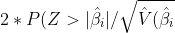 %7D),)
%7D),)
, where Z is a random variable with the standard normal distribution.
Now, the total number of cells (combinations of covariates 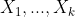 ) is
) is 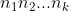 . As mentioned earlier, for a cell to be usable in the estimation, the cell needs to have at least two observations from Group A and two observations from Group B. As long as the total number of usable cells is larger than the dimension of , then the matrix
. As mentioned earlier, for a cell to be usable in the estimation, the cell needs to have at least two observations from Group A and two observations from Group B. As long as the total number of usable cells is larger than the dimension of , then the matrix 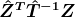 is invertible and consequently,
is invertible and consequently,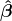 is computable and model (1) is identifiable.
is computable and model (1) is identifiable.
sbohora/sAUC documentation built on May 29, 2019, 3:23 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Semi-parametric Area Under the Curve (sAUC) Regression
Perform AUC analyses with discrete covariates and a semi-parametric estimation
Installation
# This package has not been submitted to CRAN yet. You can install its development version from GitHub:
# install.packages("devtools")
devtools::install_github("sbohora/sAUC")
If any bug is encountered, please raise an issue with a minimal reproducible example on github.
What is sAUC model and why?
In many applications, comparing two groups while adjusting for multiple covariates is desired for the statistical analysis. For instance, in clinical trials, adjusting for covariates is a necessary aspect of the statistical analysis in order to improve the precision of the treatment comparison and to assess effect modification. sAUC is a semi-parametric AUC regression model to compare the effect of two treatment groups in the intended non-normal outcome while adjusting for discrete covariates. More detailed reasons on what it is and why it is proposed are outlined in this paper. A major reason behind the development of this method is that this method is computationally simple and is based on closed-form parameter and standard error estimation.
Model
We consider applications that compare a response variable y between two groups (A and B) while adjusting for k categorical covariates . The response variable y is a continuous or ordinal variable that is not normally distributed. Without loss of generality, we assume each covariate is coded such that
,for
. For each combination of the levels of the covariates, we define the Area Under the ROC curve (AUC) in the following way:
+%5Cfrac%7B1%7D%7B2%7D%20P(Y%5EA%3DY%5EB%7CX_1%3Dx_1,X_2%3Dx_2,...,X_k%3Dx_k%20),)
where , and
and
are two randomly chosen observations from Group A and B, respectively. The second term in the above equation is for the purpose of accounting ties.
For each covariate , without loss of generality, we use the last category as the reference category and define (
) dummy variables
%7D,X_i%5E%7B(2)%7D,...,X_i%5E%7B(n_i-1)%7D) such that
%7D%20(x)%3D%201,%20if%20j%20%3D%20x) and
where . We model the association between AUC
) and covariates using a logistic model. Such a model specifies that the logit of
) is a linear combination of terms that are products of the dummy variables defined above. Specifically,
%3DZ_%7B(x_1%20x_2...x_k%20)%7D%20%5Cboldsymbol%7B%5Cbeta%7D,)
where %7D) is a row vector whose elements are zeroes or ones and are products of
%7D%20(x_1%20),...,X_1%5E%7B(n_i-1)%20%7D%20(x_1),...,X_k%5E%7B(1)%7D%20(x_k),...,X_k%5E%7B(n_k-1)%7D%20(x_k)), and
is a column vector of nonrandom unknown parameters. Now, define a column vector
by stacking up
) and define a matrix Z by stacking up
%7D), as
ranges from 1 to
, our final model is
%3DZ%5Cboldsymbol%7B%5Cbeta%7D%20...(1))
The reason for us to use a logit transformation of the AUC instead of using the original AUC is for variance stabilization. We will illustrate the above general model using examples.
Estimation
First, we denote the number of observations with covariates in groups A and B by
%5EA) and
%5EB), respectively. We assume both
%5EA) and
%5EB) are greater than zero in the following development. An unbiased estimator of
) proposed by Mann and Whitney (1947) is
%3D%5Cfrac%7B%5Csum_%7Bl%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EA%7D%20%5Csum_%7Bj%3D1%7D%5E%7BN_%7Bi_1...i_k%7D%5EB%7D%20I_%7Blj%7D%7D%7BN_%7Bi_1...i_k%7D%5EA%20N_%7Bi_1...i_k%7D%5EB%7D,)
where
;%20lj%20%3D%201) if
and
;%20lj%20%3D%20%5Cfrac%7B1%7D%7B2%7D) if
and
;%20lj%20%3D%200) if
and %5EA) and
%5EB) are observations with
in groups A and B, respectively. Delong, Delong and Clarke-Pearson (1988) have shown that
).
In order to obtain an estimator for , they first computed
and
.
Then, an estimate of the variance of the nonparametric AUC was
%5E2%7D%7BN_%7Bi_1...i_k%7D%5EA%7D%20+%20%5Cfrac%7B(s_%7Bi_1...i_k%7D%5EB%20)%5E2%7D%7BN_%7Bi_1...i_k%7D%5EB%7D),
where
%5E2) and
%5E2) were the sample variances of
and
respectively. Clearly, we need both
and
are greater than two in order to compute
.
Now, in order to estimate parameters in Model (1), we first derive the asymptotic variance of using the delta method, which results in
%20%5Capprox%20N(logit(%5Cpi_%7Bi_1...i_k%7D),%5Ctau_%7Bi_1...i_k%7D%5E2),)
where %5E2%7D)
Rewriting the above model, we obtain
%20%3DZ_%7Bi_1...i_k%7D%20%5Cboldsymbol%7B%5Cbeta%7D%20+%20%5Cepsilon_%7Bi_1...i_k%7D)
where,
). Then, by stacking up the
to be
to be
, and
to be
, we have
,
where, %3D0) and
%3Ddiag(%5Chat%7B%5Ctau%7D_%7Bi_1...%20i_k%7D%5E2)) which is a diagonal matrix. Finally, by using the generalized least squares method, we estimate the parameters β and its variance-covariance matrix as follows;
%7D%5E%7B-1%7D%20Z%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%5Chat%7B%5Cgamma%7D%7D)
and
%20%3D%20%5Cboldsymbol%7B%7B(%5Chat%7BZ%7D%5ET%20%20%5Chat%7BT%7D%5E%7B-1%7D%20%20Z)%7D%5E%7B-1%7D%7D)
The above equations can be used to construct a 100(1-α)% Wald confidence intervals for using formula
%7D),
where is the
%5E%7Bth%7D) quantile of the standard normal distribution. Equivalently, we reject
if
%7D.),
The p-value for testing is
%7D),)
, where Z is a random variable with the standard normal distribution.
Now, the total number of cells (combinations of covariates ) is
. As mentioned earlier, for a cell to be usable in the estimation, the cell needs to have at least two observations from Group A and two observations from Group B. As long as the total number of usable cells is larger than the dimension of
, then the matrix
is invertible and consequently,
is computable and model (1) is identifiable.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.