Nothing
Anomalize Quick Start Guide
In anomalize: Tidy Anomaly Detection
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>",
warning = F,
fig.align = "center"
)
The anomalize package is a feature rich package for performing anomaly detection. It's geared towards time series analysis, which is one of the biggest needs for understanding when anomalies occur. We have a quick start section called "5-Minutes to Anomalize" for those looking to jump right in. We also have a detailed section on parameter adjustment for those looking to understand what nobs they can turn. Finally, for those really looking to get under the hood, we have another vignette called "Anomalize Methods" that gets into a deep discussion on STL, Twitter, IQR and GESD methods that are used to power anomalize.
Anomalize Intro on YouTube
As a first step, you may wish to watch our anomalize introduction video on YouTube.
Check out our entire Software Intro Series on YouTube!
5-Minutes To Anomalize
Load libraries.
library(tidyverse)
library(tibbletime)
library(anomalize)
# NOTE: timetk now has anomaly detection built in, which
# will get the new functionality going forward.
anomalize <- anomalize::anomalize
plot_anomalies <- anomalize::plot_anomalies
Get some data. We'll use the tidyverse_cran_downloads data set that comes with anomalize. A few points:
-
It's a tibbletime object (class tbl_time), which is the object structure that anomalize works with because it's time aware! Tibbles (class tbl_df) will automatically be converted.
-
It contains daily download counts on 15 "tidy" packages spanning 2017-01-01 to 2018-03-01. The 15 packages are already grouped for your convenience.
-
It's all setup and ready to analyze with anomalize!
tidyverse_cran_downloads
We can use the general workflow for anomaly detection, which involves three main functions:
time_decompose(): Separates the time series into seasonal, trend, and remainder componentsanomalize(): Applies anomaly detection methods to the remainder component.time_recompose(): Calculates limits that separate the "normal" data from the anomalies!
tidyverse_cran_downloads_anomalized <- tidyverse_cran_downloads %>%
time_decompose(count, merge = TRUE) %>%
anomalize(remainder) %>%
time_recompose()
tidyverse_cran_downloads_anomalized %>% glimpse()
Let's explain what happened:
-
time_decompose(count, merge = TRUE): This performs a time series decomposition on the "count" column using seasonal decomposition. It created four columns:
- "observed": The observed values (actuals)
- "season": The seasonal or cyclic trend. The default for daily data is a weekly seasonality.
- "trend": This is the long term trend. The default is a Loess smoother using spans of 3-months for daily data.
- "remainder": This is what we want to analyze for outliers. It is simply the observed minus both the season and trend.
- Setting
merge = TRUE keeps the original data with the newly created columns.
-
anomalize(remainder): This performs anomaly detection on the remainder column. It creates three new columns:
- "remainder_l1": The lower limit of the remainder
- "remainder_l2": The upper limit of the remainder
- "anomaly": Yes/No telling us whether or not the observation is an anomaly
-
time_recompose(): This recomposes the season, trend and remainder_l1 and remainder_l2 columns into new limits that bound the observed values. The two new columns created are:
- "recomposed_l1": The lower bound of outliers around the observed value
- "recomposed_l2": The upper bound of outliers around the observed value
We can then visualize the anomalies using the plot_anomalies() function.
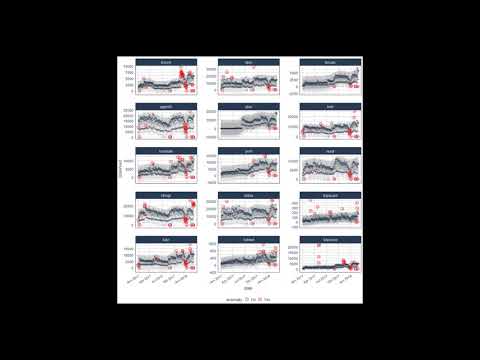
tidyverse_cran_downloads_anomalized %>%
plot_anomalies(ncol = 3, alpha_dots = 0.25)
Parameter Adjustment
Now that you have an overview of the package, you can begin to adjust the parameter settings. The first settings you may wish to explore are related to time series decomposition: trend and seasonality. The second are related to anomaly detection: alpha and max anoms.
Adjusting Decomposition Trend and Seasonality
Adjusting the trend and seasonality are fundamental to time series analysis and specifically time series decomposition. With anomalize, it's simple to make adjustments because everything is done with date or datetime information so you can intuitively select increments by time spans that make sense (e.g. "5 minutes" or "1 month").
To get started, let's isolate one of the time series packages: lubridate.
lubridate_daily_downloads <- tidyverse_cran_downloads %>%
filter(package == "lubridate") %>%
ungroup()
lubridate_daily_downloads
Next, let's perform anomaly detection.
lubridate_daily_downloads_anomalized <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder) %>%
time_recompose()
lubridate_daily_downloads_anomalized %>% glimpse()
First, notice that a frequency and a trend were automatically selected for us. This is by design. The arguments frequency = "auto" and trend = "auto" are the defaults. We can visualize this decomposition using plot_anomaly_decomposition().
p1 <- lubridate_daily_downloads_anomalized %>%
plot_anomaly_decomposition() +
ggtitle("Freq/Trend = 'auto'")
p1
When "auto" is used, a get_time_scale_template() is used to determine logical frequency and trend spans based on the scale of the data. You can uncover the logic:
get_time_scale_template()
What this means is that if the scale is 1 day (meaning the difference between each data point is 1 day), then the frequency will be 7 days (or 1 week) and the trend will be around 90 days (or 3 months). This logic tends to work quite well for anomaly detection, but you may wish to adjust it. There are two ways:
- Local parameter adjustment
- Global parameter adjustment
Local Parameter Adjustment
Local parameter adjustment can be performed by tweaking the in-function parameters. Below we adjust trend = "14 days" which makes for a quite overfit trend.
# Local adjustment via time_decompose
p2 <- lubridate_daily_downloads %>%
time_decompose(count,
frequency = "auto",
trend = "14 days") %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
ggtitle("Trend = 14 Days (Local)")
# Show plots
p1
p2
Global Parameter Adjustement
We can also adjust globally by using set_time_scale_template() to update the default template to one that we prefer. We'll change the "3 month" trend to "2 weeks" for time scale = "day". Use time_scale_template() to retrieve the time scale template that anomalize begins with, them mutate() the trend field in the desired location, and use set_time_scale_template() to update the template in the global options. We can retrieve the updated template using get_time_scale_template() to verify the change has been executed properly.
# Globally change time scale template options
time_scale_template() %>%
mutate(trend = ifelse(time_scale == "day", "14 days", trend)) %>%
set_time_scale_template()
get_time_scale_template()
Finally we can re-run the time_decompose() with defaults, and we can see that the trend is "14 days".
p3 <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder) %>%
plot_anomaly_decomposition() +
ggtitle("Trend = 14 Days (Global)")
p3
Let's reset the time scale template defaults back to the original defaults.
# Set time scale template to the original defaults
time_scale_template() %>%
set_time_scale_template()
# Verify the change
get_time_scale_template()
Adjusting Anomaly Detection Alpha and Max Anoms
The alpha and max_anoms are the two parameters that control the anomalize() function. Here's how they work.
Alpha
We can adjust alpha, which is set to 0.05 by default. By default the bands just cover the outside of the range.
p4 <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder, alpha = 0.05, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alpha = 0.05")
p4
We can decrease alpha, which increases the bands making it more difficult to be an outlier. See that the bands doubled in size.
p5 <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder, alpha = 0.025, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("alpha = 0.025")
p4
p5
Max Anoms
The max_anoms parameter is used to control the maximum percentage of data that can be an anomaly. This is useful in cases where alpha is too difficult to tune, and you really want to focus on the most aggregious anomalies.
Let's adjust alpha = 0.3 so pretty much anything is an outlier. Now let's try a comparison between max_anoms = 0.2 (20% anomalies allowed) and max_anoms = 0.05 (5% anomalies allowed).
p6 <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder, alpha = 0.3, max_anoms = 0.2) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("20% Anomalies")
p7 <- lubridate_daily_downloads %>%
time_decompose(count) %>%
anomalize(remainder, alpha = 0.3, max_anoms = 0.05) %>%
time_recompose() %>%
plot_anomalies(time_recomposed = TRUE) +
ggtitle("5% Anomalies")
p6
p7
In reality, you'll probably want to leave alpha in the range of 0.10 to 0.02, but it makes a nice illustration of how you can also use max_anoms to ensure only the most aggregious anomalies are identified.
Further Understanding: Methods
If you haven't had your fill and want to dive into the methods that power anomalize, check out the vignette, "Anomalize Methods".
Interested in Learning Anomaly Detection?
Business Science offers two 1-hour courses on Anomaly Detection:
-
Learning Lab 18 - Time Series Anomaly Detection with anomalize
-
Learning Lab 17 - Anomaly Detection with H2O Machine Learning
Try the anomalize package in your browser
Any scripts or data that you put into this service are public.
anomalize documentation built on Nov. 2, 2023, 5:13 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, comment = "#>", warning = F, fig.align = "center" )
The anomalize package is a feature rich package for performing anomaly detection. It's geared towards time series analysis, which is one of the biggest needs for understanding when anomalies occur. We have a quick start section called "5-Minutes to Anomalize" for those looking to jump right in. We also have a detailed section on parameter adjustment for those looking to understand what nobs they can turn. Finally, for those really looking to get under the hood, we have another vignette called "Anomalize Methods" that gets into a deep discussion on STL, Twitter, IQR and GESD methods that are used to power anomalize.
Anomalize Intro on YouTube
As a first step, you may wish to watch our anomalize introduction video on YouTube.
Check out our entire Software Intro Series on YouTube!
5-Minutes To Anomalize
Load libraries.
library(tidyverse) library(tibbletime) library(anomalize) # NOTE: timetk now has anomaly detection built in, which # will get the new functionality going forward. anomalize <- anomalize::anomalize plot_anomalies <- anomalize::plot_anomalies
Get some data. We'll use the tidyverse_cran_downloads data set that comes with anomalize. A few points:
-
It's a
tibbletimeobject (classtbl_time), which is the object structure thatanomalizeworks with because it's time aware! Tibbles (classtbl_df) will automatically be converted. -
It contains daily download counts on 15 "tidy" packages spanning 2017-01-01 to 2018-03-01. The 15 packages are already grouped for your convenience.
-
It's all setup and ready to analyze with
anomalize!
tidyverse_cran_downloads
We can use the general workflow for anomaly detection, which involves three main functions:
time_decompose(): Separates the time series into seasonal, trend, and remainder componentsanomalize(): Applies anomaly detection methods to the remainder component.time_recompose(): Calculates limits that separate the "normal" data from the anomalies!
tidyverse_cran_downloads_anomalized <- tidyverse_cran_downloads %>% time_decompose(count, merge = TRUE) %>% anomalize(remainder) %>% time_recompose() tidyverse_cran_downloads_anomalized %>% glimpse()
Let's explain what happened:
-
time_decompose(count, merge = TRUE): This performs a time series decomposition on the "count" column using seasonal decomposition. It created four columns:- "observed": The observed values (actuals)
- "season": The seasonal or cyclic trend. The default for daily data is a weekly seasonality.
- "trend": This is the long term trend. The default is a Loess smoother using spans of 3-months for daily data.
- "remainder": This is what we want to analyze for outliers. It is simply the observed minus both the season and trend.
- Setting
merge = TRUEkeeps the original data with the newly created columns.
-
anomalize(remainder): This performs anomaly detection on the remainder column. It creates three new columns:- "remainder_l1": The lower limit of the remainder
- "remainder_l2": The upper limit of the remainder
- "anomaly": Yes/No telling us whether or not the observation is an anomaly
-
time_recompose(): This recomposes the season, trend and remainder_l1 and remainder_l2 columns into new limits that bound the observed values. The two new columns created are:- "recomposed_l1": The lower bound of outliers around the observed value
- "recomposed_l2": The upper bound of outliers around the observed value
We can then visualize the anomalies using the plot_anomalies() function.
tidyverse_cran_downloads_anomalized %>% plot_anomalies(ncol = 3, alpha_dots = 0.25)
Parameter Adjustment
Now that you have an overview of the package, you can begin to adjust the parameter settings. The first settings you may wish to explore are related to time series decomposition: trend and seasonality. The second are related to anomaly detection: alpha and max anoms.
Adjusting Decomposition Trend and Seasonality
Adjusting the trend and seasonality are fundamental to time series analysis and specifically time series decomposition. With anomalize, it's simple to make adjustments because everything is done with date or datetime information so you can intuitively select increments by time spans that make sense (e.g. "5 minutes" or "1 month").
To get started, let's isolate one of the time series packages: lubridate.
lubridate_daily_downloads <- tidyverse_cran_downloads %>% filter(package == "lubridate") %>% ungroup() lubridate_daily_downloads
Next, let's perform anomaly detection.
lubridate_daily_downloads_anomalized <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder) %>% time_recompose() lubridate_daily_downloads_anomalized %>% glimpse()
First, notice that a frequency and a trend were automatically selected for us. This is by design. The arguments frequency = "auto" and trend = "auto" are the defaults. We can visualize this decomposition using plot_anomaly_decomposition().
p1 <- lubridate_daily_downloads_anomalized %>% plot_anomaly_decomposition() + ggtitle("Freq/Trend = 'auto'") p1
When "auto" is used, a get_time_scale_template() is used to determine logical frequency and trend spans based on the scale of the data. You can uncover the logic:
get_time_scale_template()
What this means is that if the scale is 1 day (meaning the difference between each data point is 1 day), then the frequency will be 7 days (or 1 week) and the trend will be around 90 days (or 3 months). This logic tends to work quite well for anomaly detection, but you may wish to adjust it. There are two ways:
- Local parameter adjustment
- Global parameter adjustment
Local Parameter Adjustment
Local parameter adjustment can be performed by tweaking the in-function parameters. Below we adjust trend = "14 days" which makes for a quite overfit trend.
# Local adjustment via time_decompose p2 <- lubridate_daily_downloads %>% time_decompose(count, frequency = "auto", trend = "14 days") %>% anomalize(remainder) %>% plot_anomaly_decomposition() + ggtitle("Trend = 14 Days (Local)") # Show plots p1 p2
Global Parameter Adjustement
We can also adjust globally by using set_time_scale_template() to update the default template to one that we prefer. We'll change the "3 month" trend to "2 weeks" for time scale = "day". Use time_scale_template() to retrieve the time scale template that anomalize begins with, them mutate() the trend field in the desired location, and use set_time_scale_template() to update the template in the global options. We can retrieve the updated template using get_time_scale_template() to verify the change has been executed properly.
# Globally change time scale template options time_scale_template() %>% mutate(trend = ifelse(time_scale == "day", "14 days", trend)) %>% set_time_scale_template() get_time_scale_template()
Finally we can re-run the time_decompose() with defaults, and we can see that the trend is "14 days".
p3 <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder) %>% plot_anomaly_decomposition() + ggtitle("Trend = 14 Days (Global)") p3
Let's reset the time scale template defaults back to the original defaults.
# Set time scale template to the original defaults time_scale_template() %>% set_time_scale_template() # Verify the change get_time_scale_template()
Adjusting Anomaly Detection Alpha and Max Anoms
The alpha and max_anoms are the two parameters that control the anomalize() function. Here's how they work.
Alpha
We can adjust alpha, which is set to 0.05 by default. By default the bands just cover the outside of the range.
p4 <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder, alpha = 0.05, max_anoms = 0.2) %>% time_recompose() %>% plot_anomalies(time_recomposed = TRUE) + ggtitle("alpha = 0.05") p4
We can decrease alpha, which increases the bands making it more difficult to be an outlier. See that the bands doubled in size.
p5 <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder, alpha = 0.025, max_anoms = 0.2) %>% time_recompose() %>% plot_anomalies(time_recomposed = TRUE) + ggtitle("alpha = 0.025") p4 p5
Max Anoms
The max_anoms parameter is used to control the maximum percentage of data that can be an anomaly. This is useful in cases where alpha is too difficult to tune, and you really want to focus on the most aggregious anomalies.
Let's adjust alpha = 0.3 so pretty much anything is an outlier. Now let's try a comparison between max_anoms = 0.2 (20% anomalies allowed) and max_anoms = 0.05 (5% anomalies allowed).
p6 <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder, alpha = 0.3, max_anoms = 0.2) %>% time_recompose() %>% plot_anomalies(time_recomposed = TRUE) + ggtitle("20% Anomalies") p7 <- lubridate_daily_downloads %>% time_decompose(count) %>% anomalize(remainder, alpha = 0.3, max_anoms = 0.05) %>% time_recompose() %>% plot_anomalies(time_recomposed = TRUE) + ggtitle("5% Anomalies") p6 p7
In reality, you'll probably want to leave alpha in the range of 0.10 to 0.02, but it makes a nice illustration of how you can also use max_anoms to ensure only the most aggregious anomalies are identified.
Further Understanding: Methods
If you haven't had your fill and want to dive into the methods that power anomalize, check out the vignette, "Anomalize Methods".
Interested in Learning Anomaly Detection?
Business Science offers two 1-hour courses on Anomaly Detection:
-
Learning Lab 18 - Time Series Anomaly Detection with
anomalize -
Learning Lab 17 - Anomaly Detection with
H2OMachine Learning
Try the anomalize package in your browser
Any scripts or data that you put into this service are public.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.