In favstats/demdebates2020: What the Package Does (One Line, Title Case)
knitr::opts_chunk$set(
collapse = TRUE,
warning = F,
message = F,
comment = "#>",
fig.path = "man/figures/README-",
out.width = "100%"
)
library(demdebates2020)
## basic example code
debates <- readRDS("../dem_debates2/data/debates.RDS")
# use_data(debates)
m_chr <- c("Anderson Cooper", "Andrew Yang", "Bernie Sanders", "Beto O'Rourke", "Bill de Blasio", "Chuck Todd", "Cory Booker", "David Muir", "Don Lemon", "Eric Swalwell", "George Stephanopoulos", "Jake Tapper", "Jay Inslee", "Joe Biden", "John Delaney", "John Hickenlooper", "Jorge Ramos", "Joe Diaz-Balart", "Julian Castro", "Lester Holt", "Mark Lacey", "Michael Bennet", "Pete Buttigieg", "Steve Bullock", "Tim Alberta", "Tim Ryan", "Tom Steyer", "Wolf Blizer", "Jose Diaz-Balart")
f_chr <- c("Amy Klobuchar", "Andrea Mitchell", "Ashley Parker", "Elizabeth Warren", "Judy Woodruff", "Kamala Harris", "Kirsten Gillibrand", "Kristen Welker", "Marianne Williamson", "Rachel Maddow", "Tulsi Gabbard", "Abby Phillip", "Amna Nawaz", "Brianne Pfannenstiel", "Dana Bash", "Erin Burnett", "Lindsey Davis", "Savannah Guthrie", "Yamiche Alcindor")
debates <- debates %>%
# mutate(speaker = lagged) %>%
fill(type, .direction = "down") %>%
fill(speaker, .direction = "down") %>%
select(-lagged) %>%
mutate_all(str_trim) %>%
# mutate_all(~str_remove(.x, "<U\\+2009>") %>% str_trim) %>%
mutate_all(~stringi::stri_trans_general(.x, "latin-ascii")) %>%
mutate(speech = ifelse(!is.na(background), background, speech)) %>%
filter(!str_count(speech)==0) %>%
mutate(speech = ifelse(!is.na(background), NA, speech)) %>%
mutate(day = case_when(
debate == "1A" ~ 1,
debate == "1B" ~ 2,
debate == "2A" ~ 1,
debate == "2B" ~ 2,
T ~ 1
)) %>%
mutate(debate = case_when(
debate == "1A" ~ 1,
debate == "1B" ~ 1,
debate == "2A" ~ 2,
debate == "2B" ~ 2,
T ~ parse_number(debate)
)) %>%
mutate(gender = case_when(
speaker %in% m_chr ~ "male",
speaker %in% f_chr ~ "female",
T ~ "unknown"
)) %>%
select(speaker ,background, speech, type, gender, debate, day ) %>%
mutate(speaker = ifelse(speaker == "Protestor", "Protester", speaker))
debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates9.RDS")
debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates10.RDS")
debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates11.RDS")
use_data(debates, overwrite = T)
debates %>%
dplyr::filter(debate == 11)
demdebates2020
The goal of demdebates2020 is to provide access to all transcripts of the Democratic debates of the 2020 Presidential Election.
Usage
The package includes a single dataset: debates. This dataset represents the spoken words of all Democratic candidates for US president at eleven Democratic debates. The following sources have been used to compile the data: Washington Post, Des Moines Register and rev.com. The dataset has the following eight columns:
speaker: Who is speakingbackground: Reactions from the audience, includes (APPLAUSE) or (LAUGHTER)
- only availabe for the first seven and ninth debates
speech: Transcribed speechtype: Candidate, Moderator or Protestergender: The gender of the person speakingdebate: Which debate day: Which day of the debate
- first and second debate were held on two separate days
order: The order in which the speech acts were delivered
There are two ways in which you can access the dataset.
- Read .csv file directly from GitHub
debates_url <- "https://raw.githubusercontent.com/favstats/demdebates2020/master/data/debates.csv"
debates <- readr::read_csv(debates_url)
- Install and load the R package like this:
devtools::install_github("favstats/demdebates2020")
library(demdebates2020)
Example
demdebates2020::debates %>%
dplyr::slice(1508:1510) %>%
knitr::kable()
Blog Post
Check out this blog post for some more data exploration.
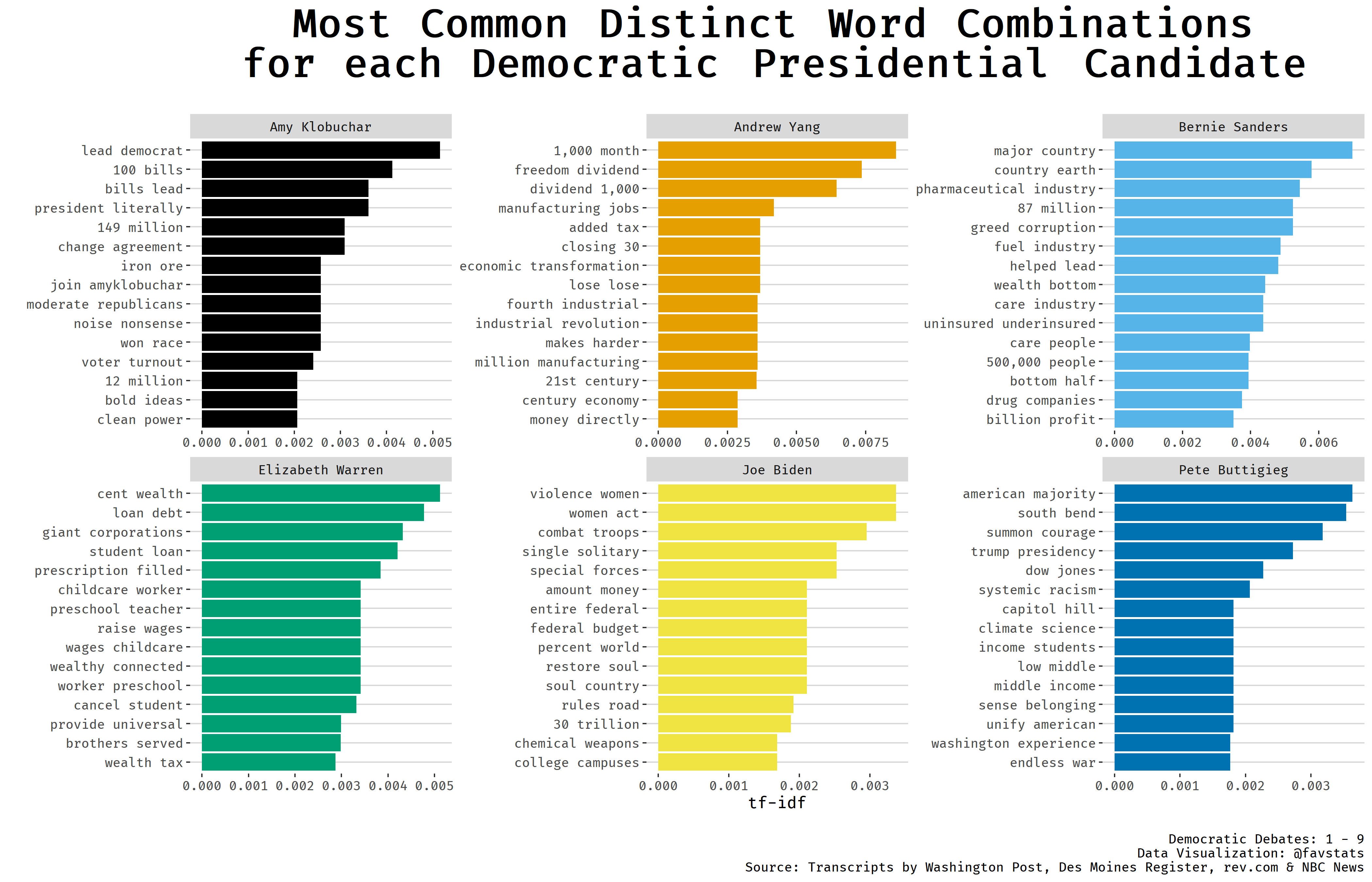
Sources
- Debate 1, Day 1: https://www.washingtonpost.com/politics/2019/06/27/transcript-night-one-first-democratic-debate-annotated/
- Debate 1, Day 2: https://www.washingtonpost.com/politics/2019/06/28/transcript-night-first-democratic-debate/
- Debate 2, Day 1: https://www.washingtonpost.com/politics/2019/07/31/transcript-first-night-second-democratic-debate/
- Debate 2, Day 2: https://www.washingtonpost.com/politics/2019/08/01/transcript-night-second-democratic-debate/
- Debate 3: https://www.washingtonpost.com/politics/2019/09/13/transcript-third-democratic-debate/
- Debate 4: https://www.washingtonpost.com/politics/2019/10/15/october-democratic-debate-transcript/
- Debate 5: https://www.washingtonpost.com/politics/2019/11/21/transcript-november-democratic-debate/
- Debate 6: https://www.washingtonpost.com/politics/2019/12/20/transcript-december-democratic-debate/
- Debate 7: https://www.desmoinesregister.com/story/news/elections/presidential/caucus/2020/01/14/democratic-debate-transcript-what-the-candidates-said-quotes/4460789002/
- Debate 8: https://www.rev.com/blog/transcripts/new-hampshire-democratic-debate-transcript
- Debate 9: https://www.nbcnews.com/politics/2020-election/full-transcript-ninth-democratic-debate-las-vegas-n1139546
- Debate 10: https://www.cbsnews.com/news/south-carolina-democratic-debate-full-transcript-text/
- Debate 11: https://www.rev.com/blog/transcripts/march-democratic-debate-transcript-joe-biden-bernie-sanders
favstats/demdebates2020 documentation built on June 23, 2020, 12:16 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, warning = F, message = F, comment = "#>", fig.path = "man/figures/README-", out.width = "100%" ) library(demdebates2020)
## basic example code debates <- readRDS("../dem_debates2/data/debates.RDS") # use_data(debates) m_chr <- c("Anderson Cooper", "Andrew Yang", "Bernie Sanders", "Beto O'Rourke", "Bill de Blasio", "Chuck Todd", "Cory Booker", "David Muir", "Don Lemon", "Eric Swalwell", "George Stephanopoulos", "Jake Tapper", "Jay Inslee", "Joe Biden", "John Delaney", "John Hickenlooper", "Jorge Ramos", "Joe Diaz-Balart", "Julian Castro", "Lester Holt", "Mark Lacey", "Michael Bennet", "Pete Buttigieg", "Steve Bullock", "Tim Alberta", "Tim Ryan", "Tom Steyer", "Wolf Blizer", "Jose Diaz-Balart") f_chr <- c("Amy Klobuchar", "Andrea Mitchell", "Ashley Parker", "Elizabeth Warren", "Judy Woodruff", "Kamala Harris", "Kirsten Gillibrand", "Kristen Welker", "Marianne Williamson", "Rachel Maddow", "Tulsi Gabbard", "Abby Phillip", "Amna Nawaz", "Brianne Pfannenstiel", "Dana Bash", "Erin Burnett", "Lindsey Davis", "Savannah Guthrie", "Yamiche Alcindor") debates <- debates %>% # mutate(speaker = lagged) %>% fill(type, .direction = "down") %>% fill(speaker, .direction = "down") %>% select(-lagged) %>% mutate_all(str_trim) %>% # mutate_all(~str_remove(.x, "<U\\+2009>") %>% str_trim) %>% mutate_all(~stringi::stri_trans_general(.x, "latin-ascii")) %>% mutate(speech = ifelse(!is.na(background), background, speech)) %>% filter(!str_count(speech)==0) %>% mutate(speech = ifelse(!is.na(background), NA, speech)) %>% mutate(day = case_when( debate == "1A" ~ 1, debate == "1B" ~ 2, debate == "2A" ~ 1, debate == "2B" ~ 2, T ~ 1 )) %>% mutate(debate = case_when( debate == "1A" ~ 1, debate == "1B" ~ 1, debate == "2A" ~ 2, debate == "2B" ~ 2, T ~ parse_number(debate) )) %>% mutate(gender = case_when( speaker %in% m_chr ~ "male", speaker %in% f_chr ~ "female", T ~ "unknown" )) %>% select(speaker ,background, speech, type, gender, debate, day ) %>% mutate(speaker = ifelse(speaker == "Protestor", "Protester", speaker)) debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates9.RDS") debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates10.RDS") debates <- readRDS("D:/Projects/git_proj/dem_debates2/data/debates11.RDS") use_data(debates, overwrite = T) debates %>% dplyr::filter(debate == 11)
demdebates2020
The goal of demdebates2020 is to provide access to all transcripts of the Democratic debates of the 2020 Presidential Election.
Usage
The package includes a single dataset: debates. This dataset represents the spoken words of all Democratic candidates for US president at eleven Democratic debates. The following sources have been used to compile the data: Washington Post, Des Moines Register and rev.com. The dataset has the following eight columns:
speaker: Who is speakingbackground: Reactions from the audience, includes(APPLAUSE)or(LAUGHTER)- only availabe for the first seven and ninth debates
speech: Transcribed speechtype: Candidate, Moderator or Protestergender: The gender of the person speakingdebate: Which debateday: Which day of the debate- first and second debate were held on two separate days
order: The order in which the speech acts were delivered
There are two ways in which you can access the dataset.
- Read .csv file directly from GitHub
debates_url <- "https://raw.githubusercontent.com/favstats/demdebates2020/master/data/debates.csv" debates <- readr::read_csv(debates_url)
- Install and load the R package like this:
devtools::install_github("favstats/demdebates2020") library(demdebates2020)
Example
demdebates2020::debates %>% dplyr::slice(1508:1510) %>% knitr::kable()
Blog Post
Check out this blog post for some more data exploration.
Sources
- Debate 1, Day 1: https://www.washingtonpost.com/politics/2019/06/27/transcript-night-one-first-democratic-debate-annotated/
- Debate 1, Day 2: https://www.washingtonpost.com/politics/2019/06/28/transcript-night-first-democratic-debate/
- Debate 2, Day 1: https://www.washingtonpost.com/politics/2019/07/31/transcript-first-night-second-democratic-debate/
- Debate 2, Day 2: https://www.washingtonpost.com/politics/2019/08/01/transcript-night-second-democratic-debate/
- Debate 3: https://www.washingtonpost.com/politics/2019/09/13/transcript-third-democratic-debate/
- Debate 4: https://www.washingtonpost.com/politics/2019/10/15/october-democratic-debate-transcript/
- Debate 5: https://www.washingtonpost.com/politics/2019/11/21/transcript-november-democratic-debate/
- Debate 6: https://www.washingtonpost.com/politics/2019/12/20/transcript-december-democratic-debate/
- Debate 7: https://www.desmoinesregister.com/story/news/elections/presidential/caucus/2020/01/14/democratic-debate-transcript-what-the-candidates-said-quotes/4460789002/
- Debate 8: https://www.rev.com/blog/transcripts/new-hampshire-democratic-debate-transcript
- Debate 9: https://www.nbcnews.com/politics/2020-election/full-transcript-ninth-democratic-debate-las-vegas-n1139546
- Debate 10: https://www.cbsnews.com/news/south-carolina-democratic-debate-full-transcript-text/
- Debate 11: https://www.rev.com/blog/transcripts/march-democratic-debate-transcript-joe-biden-bernie-sanders
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.