Rmd/2020-09-08-captura-de-dados-da-ssp-sp.md
In gabrielacaesar/segurancaSP: Estatísticsas sobre violência contra as mulheres em SP
title: Captura de dados da SSP-SP
author: Gabriela Caesar
date: '2020-09-08'
slug: captura-de-dados-ssp-sp
categories: [r]
tags: [r, rvest, tidyverse, webscraping]
output: html_document
Violência contra as mulheres / SSP-SP
Este código acessa a página com estatísticas sobre violência contra as mulheres no site da Secretaria da Segurança Pública do governo de São Paulo (SSP-SP), pega as tabelas disponíveis, acrescenta o mês e o ano dos dados e transforma em um arquivo reaproveitável. A ideia é diminuir o trabalho manual de pegar esses números à mão (com CTRL+C e CTRL+V), mais suscetível a erros.
Etapa 1
Antes de começar a raspagem, precisamos ler os pacotes, com library(). Caso necessário, você também pode precisar instalar os pacotes, com install.packages() (se for o caso, apague o jogo da velha, que transforma o código em comentário).
# install.packages(tidyverse)
# install.packages(rvest)
library(tidyverse)
library(rvest)
Etapa 2
Nesta etapa, vamos informar a URL onde ficam esses dados. Esse link foi informado pela própria SSP-SP pela Lei de Acesso à Informação, já que os dados não estão reunidos de forma consolidada em uma seção de dados abertos. Por isso, justifica-se este trabalho com a programação em R.
url <- "http://www.ssp.sp.gov.br/Estatistica/ViolenciaMulher.aspx"
Etapa 3
O mês e o ano são informados logo antes da tabela. Precisamos coletar esse texto. No HTML da página, é fácil achar as tabelas porque elas usam a tag table. Cada table está dentro de uma div com a classe table-responsive. A data está na div anterior, que tem um span. Para pegar essas informações, usamos algumas funções do pacote rvest, como read_html(), html_nodes() e html_text().
Depois, definimos o nome "mes" para a coluna, em vez de ".". Também apagamos o texto "Ocorrências Registradas no mês: " já que queremos manter apenas o mês e o ano. Queremos ainda que cada linha tenha um id para, depois, cruzarmos com os dados das tabelas (cada tabela terá um id, assim como cada data).
Substituímos ainda o nome dos meses pelo número. Por exemplo, "Agosto de " vira "08/". Por fim, pedimos para separar os dados da coluna considerando o separador "/" já que queremos ter uma coluna com mês e outra com ano.
mes <- url %>%
read_html() %>%
html_nodes(xpath = "//*[@class='table-responsive']/preceding-sibling::div") %>%
html_nodes("span") %>%
html_text() %>%
as.data.frame() %>%
rename("mes" = ".") %>%
mutate(mes = str_remove_all(mes, "Ocorrências Registradas no mês: "),
table_id = row_number()) %>%
mutate(mes = str_replace_all(mes, "Janeiro de ", "01/"),
mes = str_replace_all(mes, "Fevereiro de ", "02/"),
mes = str_replace_all(mes, "Março de ", "03/"),
mes = str_replace_all(mes, "Abril de ", "04/"),
mes = str_replace_all(mes, "Maio de ", "05/"),
mes = str_replace_all(mes, "Junho de ", "06/"),
mes = str_replace_all(mes, "Julho de ", "07/"),
mes = str_replace_all(mes, "Agosto de ", "08/"),
mes = str_replace_all(mes, "Setembro de ", "09/"),
mes = str_replace_all(mes, "Outubro de ", "10/"),
mes = str_replace_all(mes, "Novembro de ", "11/"),
mes = str_replace_all(mes, "Dezembro de ", "12/")) %>%
separate(mes, c("mes", "ano"), sep = "/")
Clique aqui para ver como ficou o resultado da etapa 3
Etapa 4
Agora queremos coletar os números de crimes contra mulher, ou seja, as tabelas do HTML. Usaremos novamente o pacote rvest, com as funções read_html() e html_table(). Como são mais de 100 tabelas, vamos criar uma estrutura de repetição. Para isso, usaremos o map_dfr() do pacote purrr, que faz parte do tidyverse.
Primeiro, contamos quantas tabelas há no HTML. Depois, criarmos um bloco de código que pega cada tabela e adiciona o id dela. Esse bloco de código criou a função get_tabela() (obs: eu escolhi esse nome). 'x' é o número que vai mudar a cada momento. Esse bloco de codigo é repetido para todas as tabelas do HTML.
Após rodar, temos um arquivo com mais de 1.500 linhas.
tabela_count <- url %>%
read_html() %>%
html_table() %>%
length()
get_tabela <- function(x){
url %>%
read_html() %>%
html_table() %>%
.[[x]] %>%
as.data.frame() %>%
rename("crime" = "") %>%
janitor::clean_names() %>%
mutate(table_id = x)
}
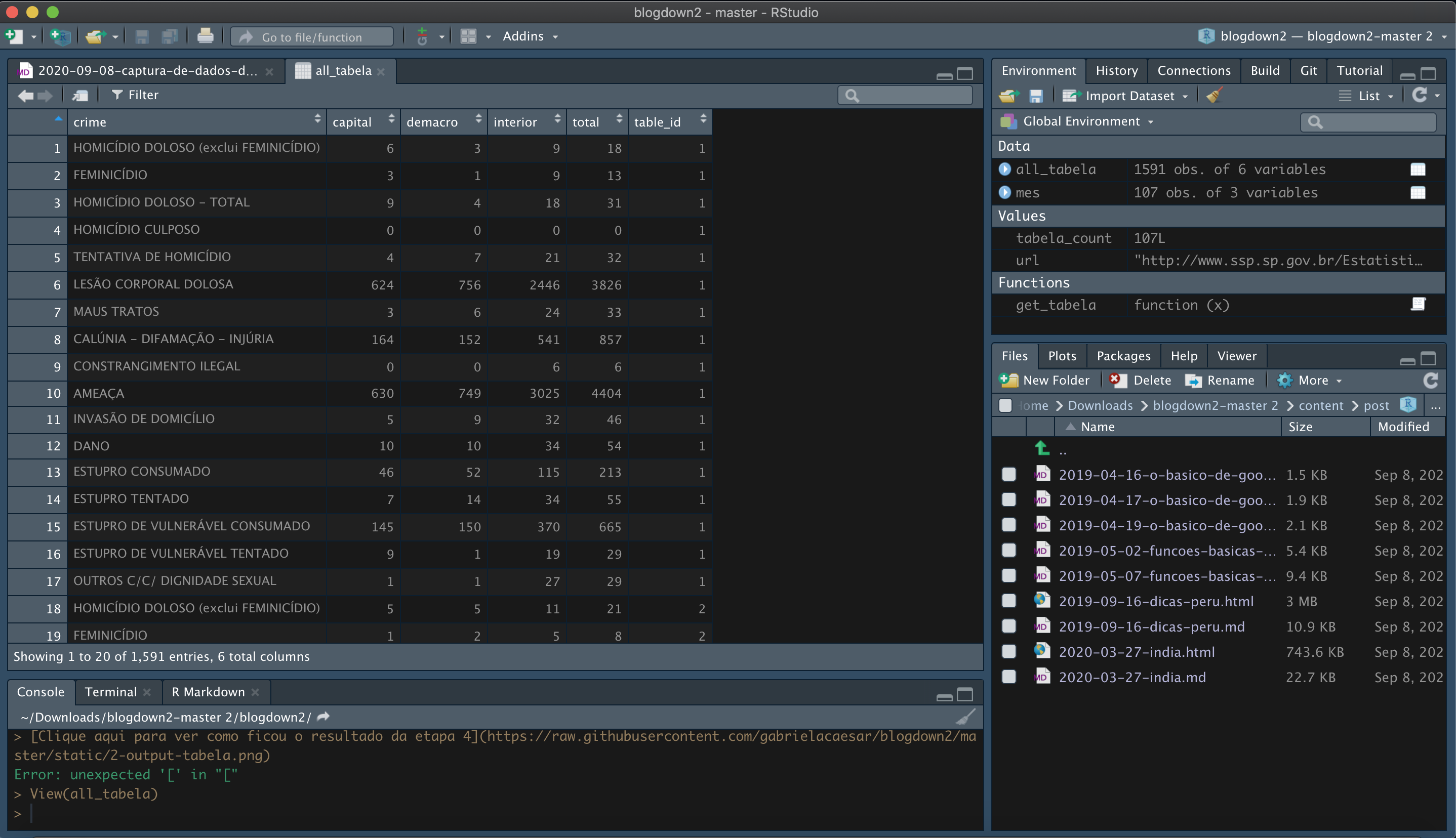
all_tabela <- map_dfr(1:tabela_count, get_tabela)
Clique aqui para ver como ficou o resultado da etapa 4
Etapa 5
Já temos um arquivo com os dados das tabelas e outro com as datas. Agora, queremos cruzá-los, considerando a coluna do id e usamos o left_join(). Depois disso, se preferir, você pode baixar o arquivo no seu computador.
Abaixo, eu crio uma nova pasta chamada "SSP_data" e o dia de hoje informado pelo computador (Sys.Date()). Defino essa pasta como local de trabalho e peço para fazer o download do CSV lá.
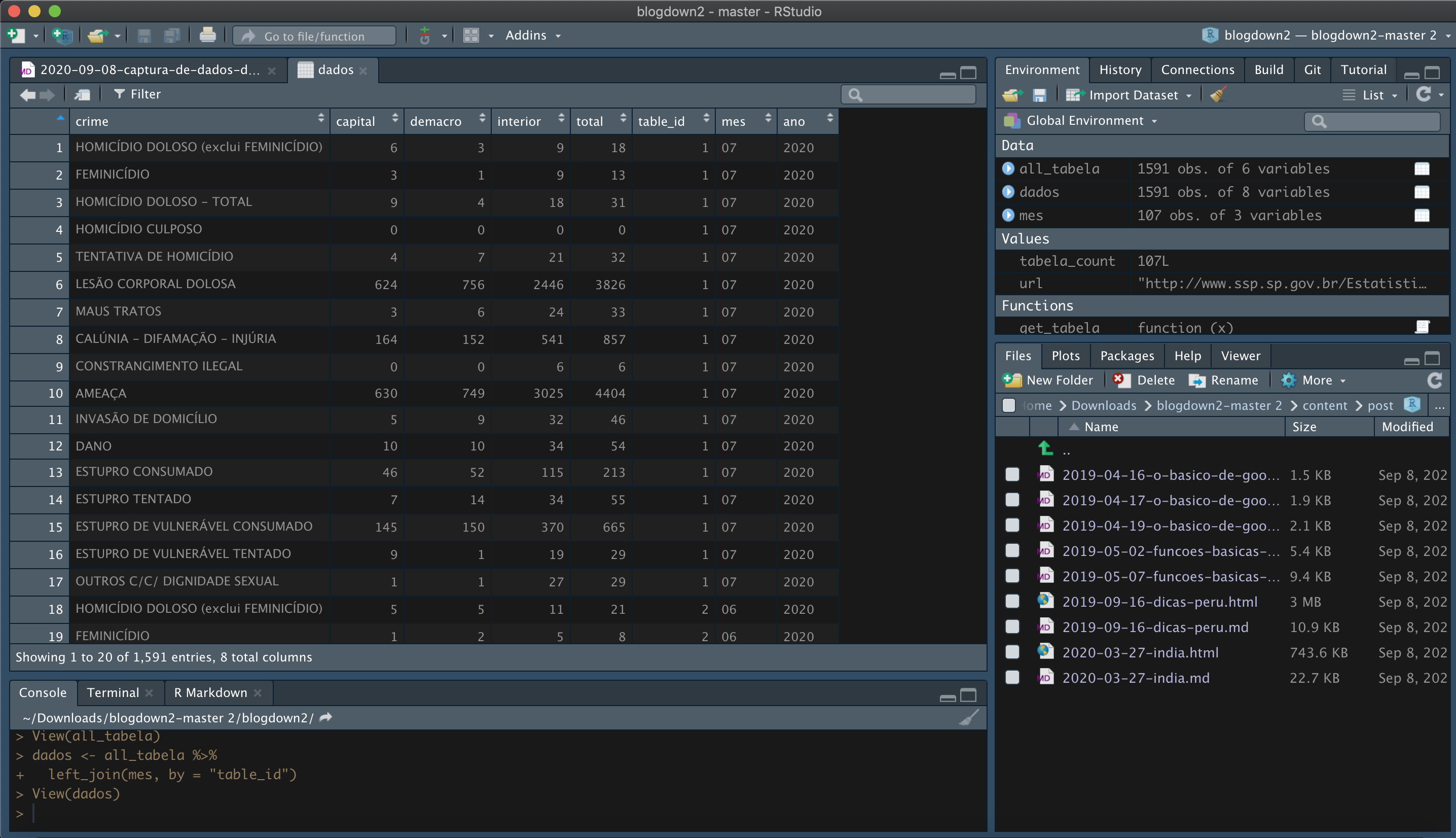
dados <- all_tabela %>%
left_join(mes, by = "table_id")
dir.create(paste0("~/Downloads/SSP_data", Sys.Date()))
setwd(paste0("~/Downloads/SSP_data", Sys.Date()))
write.csv(dados, paste0("dados", Sys.Date(), Sys.time(), ".csv"))
Clique aqui para ver como ficou o resultado da etapa 5
Etapa 6
Se preferir, assim como eu, você pode fazer o filtro / recorte direto no R. No caso, eu precisava de dados apenas do primeiro semestre de 2019 e 2020. Também defini os crimes que interessavam para a minha análise. Pedi para agrupar por crime e ano e somei os números de cada crime em cada ano. Para facilitar a visualização, pedi para os anos virarem colunas.
dados_por_crime <- dados %>%
filter(ano == "2019" | ano == "2020") %>%
filter(mes == "01" |
mes == "02" |
mes == "03" |
mes == "04" |
mes == "05" |
mes == "06") %>%
filter(crime == "ESTUPRO CONSUMADO" |
crime == "ESTUPRO DE VULNERÁVEL CONSUMADO" |
crime == "LESÃO CORPORAL DOLOSA" |
crime == "FEMINICÍDIO" |
crime == "HOMICÍDIO DOLOSO (exclui FEMINICÍDIO)") %>%
group_by(crime, ano) %>%
summarize(soma = sum(total)) %>%
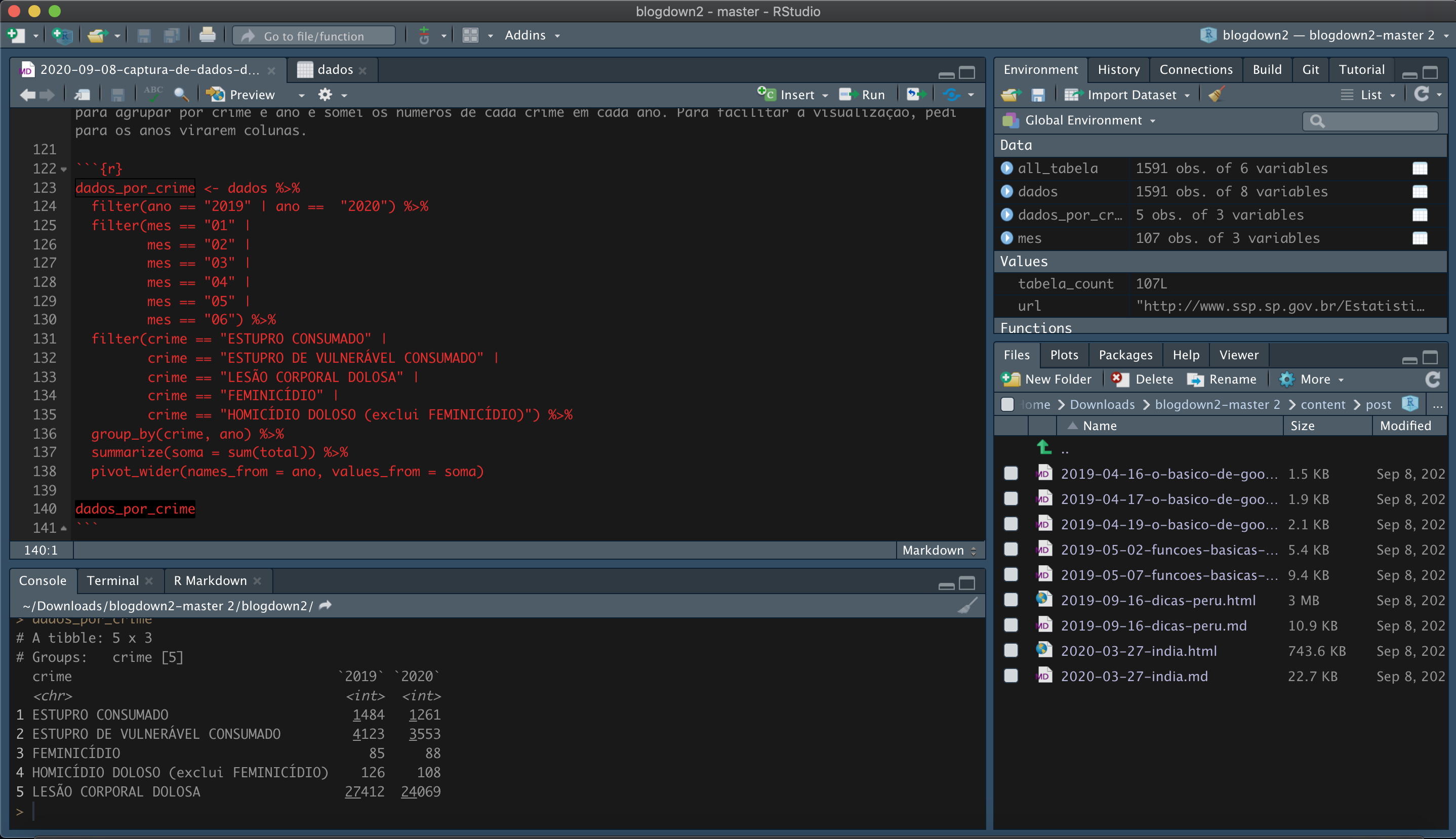
pivot_wider(names_from = ano, values_from = soma)
dados_por_crime
Clique aqui para ver como ficou o resultado da etapa 6
Etapa 7
Fim! Críticas ou sugestões são bem-vindas por e-mail (gabriela.caesar.2020@gmail.com).
gabrielacaesar/segurancaSP documentation built on Jan. 18, 2022, 11:43 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
title: Captura de dados da SSP-SP author: Gabriela Caesar date: '2020-09-08' slug: captura-de-dados-ssp-sp categories: [r] tags: [r, rvest, tidyverse, webscraping] output: html_document
Violência contra as mulheres / SSP-SP
Este código acessa a página com estatísticas sobre violência contra as mulheres no site da Secretaria da Segurança Pública do governo de São Paulo (SSP-SP), pega as tabelas disponíveis, acrescenta o mês e o ano dos dados e transforma em um arquivo reaproveitável. A ideia é diminuir o trabalho manual de pegar esses números à mão (com CTRL+C e CTRL+V), mais suscetível a erros.
Etapa 1
Antes de começar a raspagem, precisamos ler os pacotes, com library(). Caso necessário, você também pode precisar instalar os pacotes, com install.packages() (se for o caso, apague o jogo da velha, que transforma o código em comentário).
# install.packages(tidyverse)
# install.packages(rvest)
library(tidyverse)
library(rvest)
Etapa 2
Nesta etapa, vamos informar a URL onde ficam esses dados. Esse link foi informado pela própria SSP-SP pela Lei de Acesso à Informação, já que os dados não estão reunidos de forma consolidada em uma seção de dados abertos. Por isso, justifica-se este trabalho com a programação em R.
url <- "http://www.ssp.sp.gov.br/Estatistica/ViolenciaMulher.aspx"
Etapa 3
O mês e o ano são informados logo antes da tabela. Precisamos coletar esse texto. No HTML da página, é fácil achar as tabelas porque elas usam a tag table. Cada table está dentro de uma div com a classe table-responsive. A data está na div anterior, que tem um span. Para pegar essas informações, usamos algumas funções do pacote rvest, como read_html(), html_nodes() e html_text().
Depois, definimos o nome "mes" para a coluna, em vez de ".". Também apagamos o texto "Ocorrências Registradas no mês: " já que queremos manter apenas o mês e o ano. Queremos ainda que cada linha tenha um id para, depois, cruzarmos com os dados das tabelas (cada tabela terá um id, assim como cada data).
Substituímos ainda o nome dos meses pelo número. Por exemplo, "Agosto de " vira "08/". Por fim, pedimos para separar os dados da coluna considerando o separador "/" já que queremos ter uma coluna com mês e outra com ano.
mes <- url %>%
read_html() %>%
html_nodes(xpath = "//*[@class='table-responsive']/preceding-sibling::div") %>%
html_nodes("span") %>%
html_text() %>%
as.data.frame() %>%
rename("mes" = ".") %>%
mutate(mes = str_remove_all(mes, "Ocorrências Registradas no mês: "),
table_id = row_number()) %>%
mutate(mes = str_replace_all(mes, "Janeiro de ", "01/"),
mes = str_replace_all(mes, "Fevereiro de ", "02/"),
mes = str_replace_all(mes, "Março de ", "03/"),
mes = str_replace_all(mes, "Abril de ", "04/"),
mes = str_replace_all(mes, "Maio de ", "05/"),
mes = str_replace_all(mes, "Junho de ", "06/"),
mes = str_replace_all(mes, "Julho de ", "07/"),
mes = str_replace_all(mes, "Agosto de ", "08/"),
mes = str_replace_all(mes, "Setembro de ", "09/"),
mes = str_replace_all(mes, "Outubro de ", "10/"),
mes = str_replace_all(mes, "Novembro de ", "11/"),
mes = str_replace_all(mes, "Dezembro de ", "12/")) %>%
separate(mes, c("mes", "ano"), sep = "/")
Clique aqui para ver como ficou o resultado da etapa 3
Etapa 4
Agora queremos coletar os números de crimes contra mulher, ou seja, as tabelas do HTML. Usaremos novamente o pacote rvest, com as funções read_html() e html_table(). Como são mais de 100 tabelas, vamos criar uma estrutura de repetição. Para isso, usaremos o map_dfr() do pacote purrr, que faz parte do tidyverse.
Primeiro, contamos quantas tabelas há no HTML. Depois, criarmos um bloco de código que pega cada tabela e adiciona o id dela. Esse bloco de código criou a função get_tabela() (obs: eu escolhi esse nome). 'x' é o número que vai mudar a cada momento. Esse bloco de codigo é repetido para todas as tabelas do HTML.
Após rodar, temos um arquivo com mais de 1.500 linhas.
tabela_count <- url %>%
read_html() %>%
html_table() %>%
length()
get_tabela <- function(x){
url %>%
read_html() %>%
html_table() %>%
.[[x]] %>%
as.data.frame() %>%
rename("crime" = "") %>%
janitor::clean_names() %>%
mutate(table_id = x)
}
all_tabela <- map_dfr(1:tabela_count, get_tabela)
Clique aqui para ver como ficou o resultado da etapa 4
Etapa 5
Já temos um arquivo com os dados das tabelas e outro com as datas. Agora, queremos cruzá-los, considerando a coluna do id e usamos o left_join(). Depois disso, se preferir, você pode baixar o arquivo no seu computador.
Abaixo, eu crio uma nova pasta chamada "SSP_data" e o dia de hoje informado pelo computador (Sys.Date()). Defino essa pasta como local de trabalho e peço para fazer o download do CSV lá.
dados <- all_tabela %>%
left_join(mes, by = "table_id")
dir.create(paste0("~/Downloads/SSP_data", Sys.Date()))
setwd(paste0("~/Downloads/SSP_data", Sys.Date()))
write.csv(dados, paste0("dados", Sys.Date(), Sys.time(), ".csv"))
Clique aqui para ver como ficou o resultado da etapa 5
Etapa 6
Se preferir, assim como eu, você pode fazer o filtro / recorte direto no R. No caso, eu precisava de dados apenas do primeiro semestre de 2019 e 2020. Também defini os crimes que interessavam para a minha análise. Pedi para agrupar por crime e ano e somei os números de cada crime em cada ano. Para facilitar a visualização, pedi para os anos virarem colunas.
dados_por_crime <- dados %>%
filter(ano == "2019" | ano == "2020") %>%
filter(mes == "01" |
mes == "02" |
mes == "03" |
mes == "04" |
mes == "05" |
mes == "06") %>%
filter(crime == "ESTUPRO CONSUMADO" |
crime == "ESTUPRO DE VULNERÁVEL CONSUMADO" |
crime == "LESÃO CORPORAL DOLOSA" |
crime == "FEMINICÍDIO" |
crime == "HOMICÍDIO DOLOSO (exclui FEMINICÍDIO)") %>%
group_by(crime, ano) %>%
summarize(soma = sum(total)) %>%
pivot_wider(names_from = ano, values_from = soma)
dados_por_crime
Clique aqui para ver como ficou o resultado da etapa 6
Etapa 7
Fim! Críticas ou sugestões são bem-vindas por e-mail (gabriela.caesar.2020@gmail.com).
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.