In gaospecial/baidukongjian2md: Revive your Baidu Kongjian blogs
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>",
fig.path = "man/figures/README-",
out.width = "100%"
)
baidukongjian2md
baidukongjian2md 可以复活百度空间里面的博文,并将其转化为 Markdown 格式。
路人甲说:
我曾经在百度空间上面写了几十篇博文。随着年龄的增大,有一种想要整理当年思绪的需求。 幸好,虽然百度空间关闭了,但是博文被妥善安置到了百度云(http://wenzhang.baidu.com/)。
Installation
You can install the development version of baidukongjian2md from GitHub with:
# install.packages("devtools")
devtools::install_github("gaospecial/baidukongjian2md")
实现方式
-
百度空间博文保存在百度网盘 - 文章里面,在百度网盘的主页似乎并没有入口。因此,需要直接在浏览器中通过 http://wenzhang.baidu.com/ 访问博文清单。
-
博文清单处的文章列表默认只加载 100 篇。如果多于 100 篇,那么需要把页面中下拉到底才能显示完整。这一步操作在获取完整的文章清单时是必须的。
-
baidukongjian2md 使用 RSelenium 软件包实现对文章的自动化获取。获得博文后,对其格式进行处理后,再使用 Pandoc 将文档从 HTML 格式转换为 Markdown 格式。
-
RSelenium 使用时需要安装有 Chrome 浏览器,并且能够访问 Google API 的服务器以下载 Chrome Driver 程序;
-
Pandoc 需要正确安装并可以通过命令行访问到。
打开 Windows 命令提示符,输入 pandoc -h 如果会有下列信息则说明 Pandoc 可用。
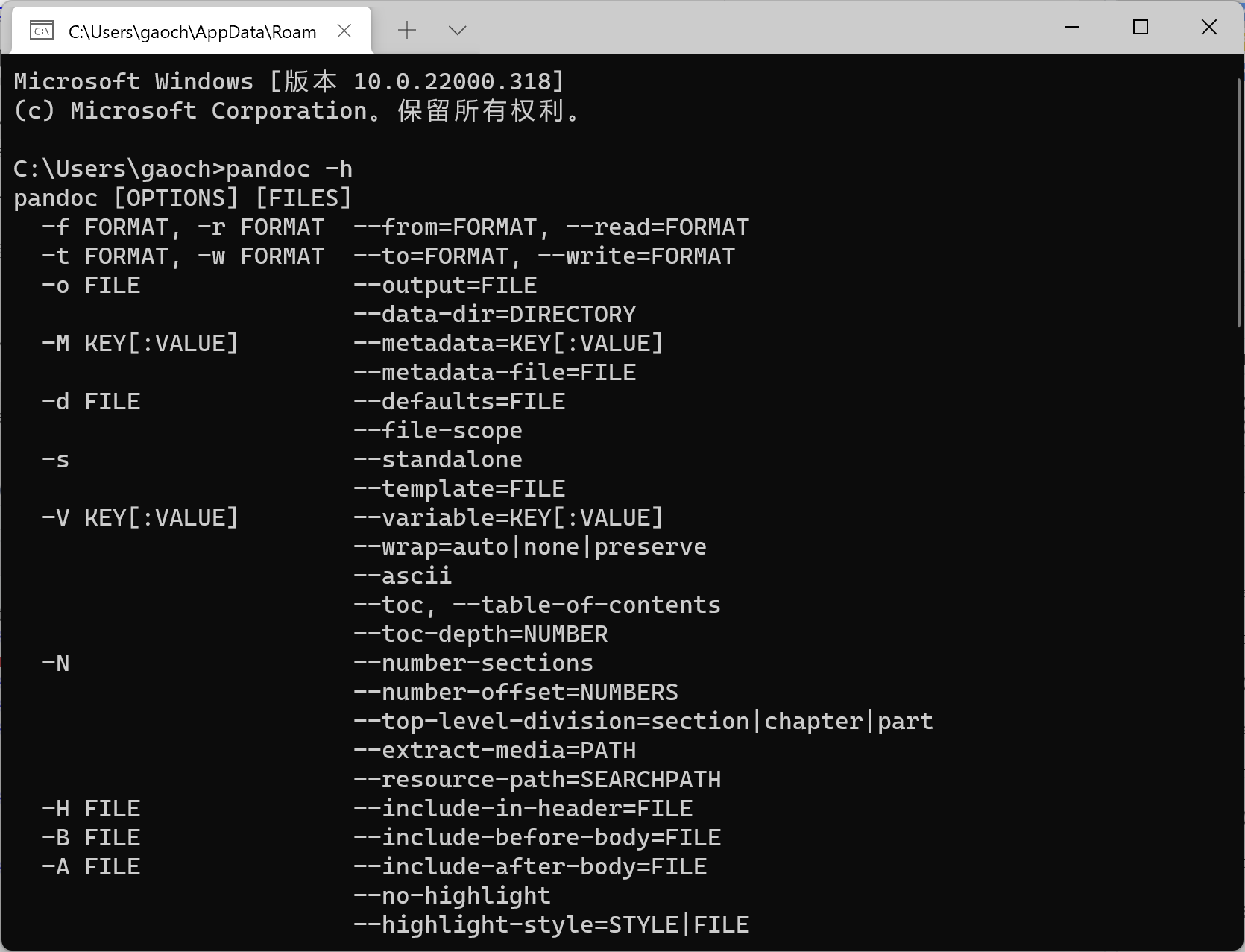
Example
由于涉及的操作步骤比较多,且涉及到系统配置、网络等多种配置,所以流程中经常出现意外中断的情况。为了能够方便的排查错误,我将整个转化过程分以下几个步骤进行:
启动浏览器
如果一切正常,那么这时可以在浏览器中登录你的百度账号。
library(baidukongjian2md)
## start a browser
remDr = start_browser()
经常出现的问题有以下两种:
- 无法下载 Chrome Driver 程序。这种情况下需要配置代理服务器。如果代理服务器的网站是“
"http://127.0.0.1:65036/"”的话,可以如下设置。
Sys.setenv(http_proxy = "http://127.0.0.1:65036/")
Sys.setenv(https_proxy = "http://127.0.0.1:65036/")
- Chrome 浏览器和 Chrome Driver 的版本不匹配。这种情况下,需要查看一下 Chrome 的版本和 Chrome Driver 的可用版本,然后指定
chromever 参数。
使用 binman::list_versions("chromedriver") 可以查看可用的 Chrome Driver 版本。
binman::list_versions("chromedriver")
获取博文的原始内容
这一步获取博文的原始内容。原始内容包含完整的博文,但是还需要进行处理以去掉无用的东西(如百度的 banner)后才能转换。
这一步操作运行的时候,程序会控制浏览器依次读取全部博文。读取成功后,~~建议将 contents 保存到本地,~~需要在当前 R Session 完成后续处理。
-
[x] 这样,爬取网页内容的任务就完成了。
-
注意:因为包含不可导出的对象 xml_document,所以 contents 无法保存。
## 打开目录页,滚动到最下面
index_url = "https://wenzhang.baidu.com/"
remDr$navigate(index_url)
## get raw contents
contents = baidukongjian(remDr)
contents
处理博文
main = lapply(contents$content, blog_content) %>% dplyr::bind_rows()
tmpdir = tempdir()
# save html fragments
main = main %>%
arrange(blog_time) %>%
group_by(blog_time) %>%
mutate(html_file = file.path(tmpdir, paste0(blog_time, "-", row_number(),".html")),
markdown_file = file.path(tmpdir, paste0(blog_time, "-", row_number(),".md")))
for (i in 1:nrow(main)){
xml2::write_xml(main$blog_content[[i]], file = main$html_file[[i]])
header = glue::glue('---',
'title: "{title}"',
'date: "{date}"',
'author: gaoch',
'tags:',
' - 百度空间',
'---\n\n',
title = main$blog_title[[i]],
date = main$blog_time[[i]],
.sep = "\n")
rmarkdown::pandoc_convert(main$html_file[[i]], to = "markdown_strict", output = main$markdown_file[[i]])
raw = xfun::read_utf8(main$markdown_file[[i]])
xfun::write_utf8(header, main$markdown_file[[i]])
xfun::append_utf8(raw, main$markdown_file[[i]], sort = FALSE)
}
现在,打开 tempdir 所指定的文件夹,把 Markdown 文件取出来就好了。
处理 WordPress 的博客
在 @yihui 所著的 blogdown: Creating Websites with R Markdown
介绍了将 WordPress 博客内容转变为 Markdown 的方法,不过这个方法目前看起来好像已经失效了。所以还是要自己动手丰衣足食。
好消息是 WordPress 提供了将全部文章导出为 RSS 的功能,因此我们可以从一个 .xml 文件开始。
library(xml2)
library(dplyr)
library(rvest)
library(lubridate)
library(yaml)
library(stringr)
# set locale is need to parse time correctly
if (.Platform$OS.type == "windows") {
Sys.setlocale("LC_TIME", "English")
} else {
Sys.setlocale("LC_TIME", "en_US.UTF-8")
}
xml = read_xml("blog.xml")
tmpdir = tempdir()
wordpress = xml %>% html_nodes("item") %>%
purrr::map(~ list(
title = html_node(.x, "title") %>% html_text(trim = TRUE),
slug = html_node(.x, "link") %>% html_text(trim = TRUE) %>%
str_remove_all( "https?://bio-spring.top/|/"),
date = html_node(.x, "pubDate") %>%
html_text(trim = TRUE) %>%
parse_date_time(orders = "%a, %d %b %Y %T %z",
tz = "Asia/Shanghai",
locale = "English" ,
exact = TRUE) %>%
format("%Y-%m-%d"),
author = html_node(.x, xpath = "dc:creator") %>% html_text(trim = TRUE),
tags = html_nodes(.x, "category") %>% html_text(trim = TRUE) %>% unlist(),
content = html_node(.x, xpath = "content:encoded") %>% html_text(trim = TRUE)
)
)
success = lapply(wordpress, wordpress_blog2md)
上面也就是干了下面几件事:
- 识别日期,生成带日期的 slug(太难了)
- 去掉 content 里面的 related post(把插件禁用就好了)
- 转换为 markdown(Pandoc 的转化结果并不完美)
gaospecial/baidukongjian2md documentation built on Jan. 2, 2022, 4:32 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, comment = "#>", fig.path = "man/figures/README-", out.width = "100%" )
baidukongjian2md
baidukongjian2md 可以复活百度空间里面的博文,并将其转化为 Markdown 格式。
路人甲说:
我曾经在百度空间上面写了几十篇博文。随着年龄的增大,有一种想要整理当年思绪的需求。 幸好,虽然百度空间关闭了,但是博文被妥善安置到了百度云(http://wenzhang.baidu.com/)。
Installation
You can install the development version of baidukongjian2md from GitHub with:
# install.packages("devtools") devtools::install_github("gaospecial/baidukongjian2md")
实现方式
-
百度空间博文保存在百度网盘 - 文章里面,在百度网盘的主页似乎并没有入口。因此,需要直接在浏览器中通过 http://wenzhang.baidu.com/ 访问博文清单。
-
博文清单处的文章列表默认只加载 100 篇。如果多于 100 篇,那么需要把页面中下拉到底才能显示完整。这一步操作在获取完整的文章清单时是必须的。
-
baidukongjian2md 使用 RSelenium 软件包实现对文章的自动化获取。获得博文后,对其格式进行处理后,再使用 Pandoc 将文档从 HTML 格式转换为 Markdown 格式。
-
RSelenium 使用时需要安装有 Chrome 浏览器,并且能够访问 Google API 的服务器以下载 Chrome Driver 程序;
-
Pandoc 需要正确安装并可以通过命令行访问到。
打开 Windows 命令提示符,输入 pandoc -h 如果会有下列信息则说明 Pandoc 可用。
Example
由于涉及的操作步骤比较多,且涉及到系统配置、网络等多种配置,所以流程中经常出现意外中断的情况。为了能够方便的排查错误,我将整个转化过程分以下几个步骤进行:
启动浏览器
如果一切正常,那么这时可以在浏览器中登录你的百度账号。
library(baidukongjian2md) ## start a browser remDr = start_browser()
经常出现的问题有以下两种:
- 无法下载 Chrome Driver 程序。这种情况下需要配置代理服务器。如果代理服务器的网站是“
"http://127.0.0.1:65036/"”的话,可以如下设置。
Sys.setenv(http_proxy = "http://127.0.0.1:65036/") Sys.setenv(https_proxy = "http://127.0.0.1:65036/")
- Chrome 浏览器和 Chrome Driver 的版本不匹配。这种情况下,需要查看一下 Chrome 的版本和 Chrome Driver 的可用版本,然后指定
chromever参数。
使用 binman::list_versions("chromedriver") 可以查看可用的 Chrome Driver 版本。
binman::list_versions("chromedriver")
获取博文的原始内容
这一步获取博文的原始内容。原始内容包含完整的博文,但是还需要进行处理以去掉无用的东西(如百度的 banner)后才能转换。
这一步操作运行的时候,程序会控制浏览器依次读取全部博文。读取成功后,~~建议将 contents 保存到本地,~~需要在当前 R Session 完成后续处理。
-
[x] 这样,爬取网页内容的任务就完成了。
-
注意:因为包含不可导出的对象
xml_document,所以contents无法保存。
## 打开目录页,滚动到最下面 index_url = "https://wenzhang.baidu.com/" remDr$navigate(index_url)
## get raw contents contents = baidukongjian(remDr) contents
处理博文
main = lapply(contents$content, blog_content) %>% dplyr::bind_rows() tmpdir = tempdir() # save html fragments main = main %>% arrange(blog_time) %>% group_by(blog_time) %>% mutate(html_file = file.path(tmpdir, paste0(blog_time, "-", row_number(),".html")), markdown_file = file.path(tmpdir, paste0(blog_time, "-", row_number(),".md"))) for (i in 1:nrow(main)){ xml2::write_xml(main$blog_content[[i]], file = main$html_file[[i]]) header = glue::glue('---', 'title: "{title}"', 'date: "{date}"', 'author: gaoch', 'tags:', ' - 百度空间', '---\n\n', title = main$blog_title[[i]], date = main$blog_time[[i]], .sep = "\n") rmarkdown::pandoc_convert(main$html_file[[i]], to = "markdown_strict", output = main$markdown_file[[i]]) raw = xfun::read_utf8(main$markdown_file[[i]]) xfun::write_utf8(header, main$markdown_file[[i]]) xfun::append_utf8(raw, main$markdown_file[[i]], sort = FALSE) }
现在,打开 tempdir 所指定的文件夹,把 Markdown 文件取出来就好了。
处理 WordPress 的博客
在 @yihui 所著的 blogdown: Creating Websites with R Markdown 介绍了将 WordPress 博客内容转变为 Markdown 的方法,不过这个方法目前看起来好像已经失效了。所以还是要自己动手丰衣足食。
好消息是 WordPress 提供了将全部文章导出为 RSS 的功能,因此我们可以从一个 .xml 文件开始。
library(xml2) library(dplyr) library(rvest) library(lubridate) library(yaml) library(stringr) # set locale is need to parse time correctly if (.Platform$OS.type == "windows") { Sys.setlocale("LC_TIME", "English") } else { Sys.setlocale("LC_TIME", "en_US.UTF-8") } xml = read_xml("blog.xml") tmpdir = tempdir() wordpress = xml %>% html_nodes("item") %>% purrr::map(~ list( title = html_node(.x, "title") %>% html_text(trim = TRUE), slug = html_node(.x, "link") %>% html_text(trim = TRUE) %>% str_remove_all( "https?://bio-spring.top/|/"), date = html_node(.x, "pubDate") %>% html_text(trim = TRUE) %>% parse_date_time(orders = "%a, %d %b %Y %T %z", tz = "Asia/Shanghai", locale = "English" , exact = TRUE) %>% format("%Y-%m-%d"), author = html_node(.x, xpath = "dc:creator") %>% html_text(trim = TRUE), tags = html_nodes(.x, "category") %>% html_text(trim = TRUE) %>% unlist(), content = html_node(.x, xpath = "content:encoded") %>% html_text(trim = TRUE) ) ) success = lapply(wordpress, wordpress_blog2md)
上面也就是干了下面几件事:
- 识别日期,生成带日期的 slug(太难了)
- 去掉 content 里面的 related post(把插件禁用就好了)
- 转换为 markdown(Pandoc 的转化结果并不完美)
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.