README.md
In lindeloev/job: Run Code as an RStudio Job - Free Your Console


job: free your RStudio console
Use job::job() to run chunks of R code in an RStudio job instead of the console. This frees your console while the job(s) go brrrrr in the background. By default, the result is returned to the global environment when the job completes.
Install from CRAN (stable) or GitHub (development):
install.packages("job")
remotes::install_github("lindeloev/job")
Addins
Two RStudio Addins are installed with job. Simply select some code code in your editor and click one of the Addins to run it as a job. The results are returned to the global environment once the job completes.
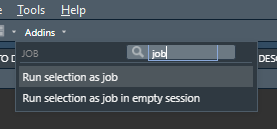
- "Run selection as job" calls
job::job(). It imports everything from your environment, so it feels like home. It returns all new or changed variables job.
- "Run selection as job in empty session" calls
job::empty(). It imports nothing from your environment, so the code can run in clean isolation. All variables are returned.
Minimal example
Write your script as usual. Then wrap parts of it using job::job({<your code>}) to run that chunk as a job:
job::job({
foo = 10
bar = rnorm(5)
})
When the job completes, it silently saves foo and bar to your global environment.
Typical usage
brms is great, but you often restrict yourself to fit as few models as possible fewer models because compilation and sampling takes time. Let's run it as a job!
# Do light processing in the main session
library(brms)
data = mtcars[mtcars$hp > 100, ]
model1 = mpg ~ hp * wt
model2 = mpg ~ hp + wt
# Send long-running code to job(s).
job::job({
fit1 = brm(model1, data)
})
job::job({
fit2 = brm(model2, data)
})
# Continue working in your console
cat("I'm free now! Thank you.
Yours truly, Console.")
Now you can follow the progress in the jobs pane and your console is free in the meantime.
Tweak your job(s)
Extending the brms-example above, let's fine-control the first job a bit more:
# Name the code block to return as environment
job::job(brm_result = {
# Job-specific settings
options(mc.cores = 3)
# Compute stuff
fit = brm(model1, data)
fit = add_criterion(fit, "loo")
the_test = hypothesis(fit, "hp > 0")
# Print stuff inside the job
print(summary(fit))
# Control what is returned to the main session
job::export(c(fit, the_test))
}, import = c(data, model1)) # Control what is imported into the job
Because we named the code block brm_result, it will return the contents as an environment() called brm_result (or whatever you called it).brm_result behaves much like a list():
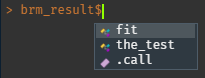
Turn RStudio's Jobs into high-level history
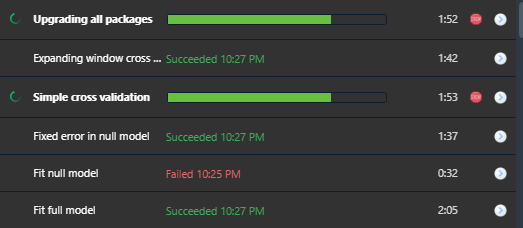
Often, the results of the long-running chunks are the most interesting. But they easily get buried among the other outputs in the console and are eventually lost due to the line limit. RStudio's jobs history can be used as a nice overview. Make sure to print informative results within the job and give your jobs an appropriate title, e.g., (job::job({<code here>}, title = "Unit test: first attempt at feature X").
Docs and recommendations
See the documentation how you can fine-control the job environment and what results are returned. The job::job() website has worked examples, where finer control is beneficial, including:
- Controlling import of variables, packages, and options.
- Controlling export using the
job::export() function.
- Using
job::job() to test code chunks in an isolated environment.
- Using
job::job() to render large plots.
Use cases: all flow-breakers
The primary use case for job::job() are heavy statistical and numerical functions, including MCMC sampling, cross-validation, etc.
But sometimes our flow is disturbed by semi-slow routine tasks too. Try running devtools::test(), knitr::knit(), pkgdown::build_site(), or upgrade.packages() as a job and see whether that's an improvement. Here's a list of semi-slow functions that I regularly run as jobs.
See also
job::job() is aimed at easing interactive development within RStudio. For tasks that don't benefit from running in the Jobs pane of RStudio, check out:
-
The future package's %<-% operator combined with plan(multisession).
-
The callr package is a general tool to run code in new R sessions.
lindeloev/job documentation built on Oct. 3, 2024, 4:45 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
![]()
job: free your RStudio console
Use job::job() to run chunks of R code in an RStudio job instead of the console. This frees your console while the job(s) go brrrrr in the background. By default, the result is returned to the global environment when the job completes.
Install from CRAN (stable) or GitHub (development):
install.packages("job")
remotes::install_github("lindeloev/job")
Addins
Two RStudio Addins are installed with job. Simply select some code code in your editor and click one of the Addins to run it as a job. The results are returned to the global environment once the job completes.
- "Run selection as job" calls
job::job(). It imports everything from your environment, so it feels like home. It returns all new or changed variables job. - "Run selection as job in empty session" calls
job::empty(). It imports nothing from your environment, so the code can run in clean isolation. All variables are returned.
Minimal example
Write your script as usual. Then wrap parts of it using job::job({<your code>}) to run that chunk as a job:
job::job({
foo = 10
bar = rnorm(5)
})
When the job completes, it silently saves foo and bar to your global environment.
Typical usage
brms is great, but you often restrict yourself to fit as few models as possible fewer models because compilation and sampling takes time. Let's run it as a job!
# Do light processing in the main session
library(brms)
data = mtcars[mtcars$hp > 100, ]
model1 = mpg ~ hp * wt
model2 = mpg ~ hp + wt
# Send long-running code to job(s).
job::job({
fit1 = brm(model1, data)
})
job::job({
fit2 = brm(model2, data)
})
# Continue working in your console
cat("I'm free now! Thank you.
Yours truly, Console.")
Now you can follow the progress in the jobs pane and your console is free in the meantime.
Tweak your job(s)
Extending the brms-example above, let's fine-control the first job a bit more:
# Name the code block to return as environment
job::job(brm_result = {
# Job-specific settings
options(mc.cores = 3)
# Compute stuff
fit = brm(model1, data)
fit = add_criterion(fit, "loo")
the_test = hypothesis(fit, "hp > 0")
# Print stuff inside the job
print(summary(fit))
# Control what is returned to the main session
job::export(c(fit, the_test))
}, import = c(data, model1)) # Control what is imported into the job
Because we named the code block brm_result, it will return the contents as an environment() called brm_result (or whatever you called it).brm_result behaves much like a list():
Turn RStudio's Jobs into high-level history
Often, the results of the long-running chunks are the most interesting. But they easily get buried among the other outputs in the console and are eventually lost due to the line limit. RStudio's jobs history can be used as a nice overview. Make sure to print informative results within the job and give your jobs an appropriate title, e.g., (job::job({<code here>}, title = "Unit test: first attempt at feature X").
Docs and recommendations
See the documentation how you can fine-control the job environment and what results are returned. The job::job() website has worked examples, where finer control is beneficial, including:
- Controlling import of variables, packages, and options.
- Controlling export using the
job::export()function. - Using
job::job()to test code chunks in an isolated environment. - Using
job::job()to render large plots.
Use cases: all flow-breakers
The primary use case for job::job() are heavy statistical and numerical functions, including MCMC sampling, cross-validation, etc.
But sometimes our flow is disturbed by semi-slow routine tasks too. Try running devtools::test(), knitr::knit(), pkgdown::build_site(), or upgrade.packages() as a job and see whether that's an improvement. Here's a list of semi-slow functions that I regularly run as jobs.
See also
job::job() is aimed at easing interactive development within RStudio. For tasks that don't benefit from running in the Jobs pane of RStudio, check out:
-
The
futurepackage's%<-%operator combined withplan(multisession). -
The
callrpackage is a general tool to run code in new R sessions.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.