In paithiov909/gibasa: An Alternative 'Rcpp' Wrapper of 'MeCab'
knitr::opts_chunk$set(
tidy = "styler",
collapse = TRUE,
comment = "#>"
)
set.seed(3179)
require("ggplot2", quietly = TRUE)
はじめに
このページでは、quantedaとgibasaを用いた簡単なテキストマイニングを例に、quantedaやその他のRパッケージとのあいだでテキストデータをやりとりする方法を紹介します。ここでおこなっているようなテキスト分析の例としては、次のサイトも参考にしてください。
ちなみに、quantedaはstringiをラップした関数によって日本語の文書でも分かち書きできるので、手元の辞書に収録されている表現どおりに分かち書きしたい場合や、品詞情報が欲しい場合でないかぎりは、形態素解析器を使うメリットはあまりないかもしれません。stringiが利用しているICUのBoundary Analysisの仕様については、UAX#29などを参照してください。
Text Interchange Formats(TIF)
gibasaによる形態素解析の結果をquantedaなどと組み合わせて使ううえでは、Text Interchange Formats(TIF)という仕様に沿ったかたちのオブジェクトとしてテキストデータをもつことを意識すると便利です。
TIFというのは、2017年にrOpenSci Text Workshopで整備された、テキスト分析用のRパッケージのデザインパターンのようなものです。TIFでは、コーパス(corpus)、トークン(token)、文書単語行列(dtm)という3種類のオブジェクトの形式が定義されており、異なるパッケージ間で同様の形式を扱うようにすることで、複数のパッケージを通じて便利にテキスト分析を進められるようになっています。
このうち「コーパス」は、文書の集合をデータフレームあるいは名前付きベクトルの形式で保持したものです。
ldccrでは、livedoorニュースコーパスをデータフレームの形式のコーパスとして読み込むことができます。より厳密に言うと、データフレーム形式のコーパスは、少なくともdoc_idとtextという列を含むデータフレームなので、doc_id列は自分でつくる必要があります。コーパスにおけるdoc_id列は、文書によって一意なID列(character型である必要がある)で、text列は文書本体になります。「少なくとも」なので、このほかの列にここでのcategory列のような文書のメタ情報などが含まれる場合があります。
tbl <- ldccr::read_ldnws() |>
dplyr::mutate(doc_id = as.character(dplyr::row_number())) |>
dplyr::rename(text = body)
tbl
livedoorニュースコーパスは文書分類をおこなうことを主な目的につくられたデータセットで、以下の9カテゴリのブログ記事からなっています。
- トピックニュース
- Sports Watch
- ITライフハック
- 家電チャンネル
- MOVIE ENTER
- 独女通信
- エスマックス
- livedoor HOMME
- Peachy
このうち一部だけをgibasaで形態素解析して、データフレームの形式の「トークン」としてもっておきます。トークンは、コーパスを文書ごとに適当な単位にまとめあげながら格納したものです。それぞれのトークンは単語だったり、単語のN-gramだったりします。
ここではKH Coderで採用されている品詞体系を参考に、形態素解析された語の品詞情報を適当な値に置き換えています。なお、こうしたデータフレームの形式のトークンは、しばしばtidy textとも呼ばれます。
toks <- tbl |>
dplyr::select(doc_id, category, text) |>
dplyr::slice_sample(prop = .8) |>
dplyr::mutate(
text = stringi::stri_trans_nfkc(text) |>
stringi::stri_replace_all_regex("(https?\\://[[:alnum:]\\.\\-_/]+)", "\nURL\tタグ\n") |>
stringi::stri_replace_all_regex("[\\s]{2,}", "\n") |>
stringi::stri_trim_both()
) |>
gibasa::tokenize(text, partial = TRUE) |>
gibasa::prettify(
col_select = c("POS1", "POS2", "POS3", "Original")
) |>
dplyr::mutate(
pos = dplyr::case_when(
(POS1 == "タグ") ~ "タグ",
(is.na(Original) & stringr::str_detect(token, "^[[:alpha:]]+$")) ~ "未知語",
(POS1 == "感動詞") ~ "感動詞",
(POS1 == "名詞" & POS2 == "一般" & stringr::str_detect(token, "^[\\p{Han}]{1}$")) ~ "名詞C",
(POS1 == "名詞" & POS2 == "一般" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "名詞B",
(POS1 == "名詞" & POS2 == "一般") ~ "名詞",
(POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "地域") ~ "地名",
(POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "人名") ~ "人名",
(POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "組織") ~ "組織名",
(POS1 == "名詞" & POS2 == "形容動詞語幹") ~ "形容動詞",
(POS1 == "名詞" & POS2 == "ナイ形容詞語幹") ~ "ナイ形容詞",
(POS1 == "名詞" & POS2 == "固有名詞") ~ "固有名詞",
(POS1 == "名詞" & POS2 == "サ変接続") ~ "サ変名詞",
(POS1 == "名詞" & POS2 == "副詞可能") ~ "副詞可能",
(POS1 == "動詞" & POS2 == "自立" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "動詞B",
(POS1 == "動詞" & POS2 == "自立") ~ "動詞",
(POS1 == "形容詞" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "形容詞B",
(POS1 == "形容詞" & POS2 == "非自立") ~ "形容詞(非自立)",
(POS1 == "形容詞") ~ "形容詞",
(POS1 == "副詞" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "副詞B",
(POS1 == "副詞") ~ "副詞",
(POS1 == "助動詞" & Original %in% c("ない", "まい", "ぬ", "ん")) ~ "否定助動詞",
.default = "その他"
)
) |>
dplyr::select(doc_id, category, token_id, token, pos, Original) |>
dplyr::rename(original = Original)
toks
Tidy textからdfmへの変換
さて、実際にこういったトークンからさまざまな分析をするには、トークンを品詞などによって取捨選択しながら、分析したい単位ごとにグルーピングして集計する必要があります。
簡単に集計するだけであれば、次のようにdplyrの関数を使って集計することができます。こうした文書ID、単語と、単語の文書内頻度の3つ組のかたちをしたデータフレームは、summarized textという呼び方をすることがあるようです。
toks |>
dplyr::filter(!pos %in% c("その他", "タグ")) |>
dplyr::count(doc_id, token) |>
dplyr::arrange(dplyr::desc(n))
一方で、たとえば、特定のトークンの連なりは連語と見なして一つのトークンとして集計したいといった場合には、dplyrだけで集計するのはなかなか大変です。そういったより複雑なケースでは、quantedaの枠組みと組み合わせて使ったほうが便利なことがあります。
たとえば、IPA辞書では正しく解析されない「スマートフォン」といった語について、形態素解析した結果を確認した後に再度まとめあげて集計したい場合、quantedaを使うと次のように書くことができます。また、ここでは、うまく「記号」として解析されなかった記号類を除外するために、正規表現にマッチするトークンだけに絞り込んで集計しています。
dfm <- toks |>
dplyr::filter(!pos %in% c("その他", "タグ")) |>
gibasa::pack() |>
quanteda::corpus() |>
quanteda::tokens(what = "fastestword", remove_url = TRUE) |>
quanteda::tokens_compound(
quanteda::phrase(c("スマート フォン", "s - max"))
) |>
quanteda::tokens_keep(
"^[[:alnum:]]{2,}$",
valuetype = "regex"
) |>
quanteda::dfm()
dfm
quanteda::dfm()の戻り値は「文書単語行列(dtm)」を疎行列オブジェクト(dgCMatrix of 'Matrix' package)として保持したものです(厳密には、dgCMatrixをスロットにもっているS4オブジェクト)。dfmオブジェクトは、qunateda.textstats::textstat_frequency()などを使って、さらに集計することができます。
dat <- dfm |>
quanteda.textstats::textstat_frequency() |>
dplyr::as_tibble()
head(dat)
dat |>
ggplot(aes(x = frequency, y = docfreq)) +
geom_jitter() +
gghighlight::gghighlight(
frequency > 2500 & docfreq < 2000
) +
ggrepel::geom_text_repel(
aes(label = feature),
max.overlaps = 50
) +
scale_x_log10() +
scale_y_sqrt() +
theme_bw() +
labs(x = "出現回数", y = "文書数")
Summarized textからdfmへの変換
「文書単語行列(dtm)」は、トークンを集計した結果を縦長のデータフレームとしてもっているsummarized textを横に展開したものだと理解できます。両者は表現が異なるだけで、もっているデータとしては同じものであるため、quantedaにおけるdfmオブジェクトはtidytext::cast_dfm()を使ってsummarized textを変換することによって得ることもできます。
dfm <- toks |>
dplyr::filter(
pos %in% c(
"名詞",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語"
),
stringr::str_detect(token, "^[[:alnum:]]{2,}$")
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), tolower(token), original),
token = paste(token, pos, sep = "/")
) |>
dplyr::count(doc_id, token) |>
tidytext::cast_dfm(doc_id, token, n)
dfmオブジェクトはquanteda::dfm_*という名前の関数を使って語彙を減らしたり、単語頻度に重みづけをしたりすることができます。
ここではquanteda.textstats::textstat_simil()で単語間の類似度を得て、階層的クラスタリングをしてみます。
clusters <- dfm |>
quanteda::dfm_trim(min_termfreq = 40, termfreq_type = "rank") |>
quanteda::dfm_weight(scheme = "boolean") |>
quanteda.textstats::textstat_simil(margin = "features", method = "dice") |>
rlang::as_function(~ 1 - .)() |>
as.dist() |>
hclust(method = "ward.D2")
dfm |>
quanteda::dfm_trim(min_termfreq = 40, termfreq_type = "rank") |>
quanteda::colSums() |>
tibble::enframe() |>
dplyr::mutate(
clust = (clusters |> cutree(k = 5))[name]
) |>
ggplot(aes(x = value, y = name, fill = factor(clust))) +
geom_bar(stat = "identity", show.legend = FALSE) +
scale_x_sqrt() +
ggh4x::scale_y_dendrogram(hclust = clusters) +
labs(x = "出現回数", y = element_blank()) +
theme_bw()
dfmからSummarized textへの変換
dfmオブジェクトはtidytext::tidy()でsummarized textのかたちに変換することができます。tidytext::tidy()とtidytext::cast_dfm()をあわせて使うことで、dfmオブジェクトとsummarized textのあいだで自由に変換しあうことができます。
dfm <- dfm |>
quanteda::dfm_trim(
min_termfreq = 40,
termfreq_type = "rank"
) |>
tidytext::tidy() |>
dplyr::left_join(
tbl |>
dplyr::mutate(doc_id = factor(dplyr::row_number())) |>
dplyr::select(doc_id, category),
by = dplyr::join_by(document == doc_id)
) |>
tidytext::cast_dfm(category, term, count)
ここでは、quanteda.textmodels::textmodel_ca()を使ってdfmオブジェクトを対応分析にかけます。この関数の戻り値はcaパッケージのオブジェクトと互換性があるため、library(ca)としてからplot()に渡すことでバイプロットを描画することができます。
ca_fit <- dfm |>
quanteda.textmodels::textmodel_ca(nd = 2, sparse = TRUE)
library(ca)
dat <- plot(ca_fit)
より見やすい表現としては、次のようにしてggplot2でバイプロットを描画することもできます。
tf <- quanteda::colSums(dfm)
make_ca_plot_df <- function(ca.plot.obj, row.lab = "Rows", col.lab = "Columns") {
tibble::tibble(
Label = c(
rownames(ca.plot.obj$rows),
rownames(ca.plot.obj$cols)
),
Dim1 = c(
ca.plot.obj$rows[, 1],
ca.plot.obj$cols[, 1]
),
Dim2 = c(
ca.plot.obj$rows[, 2],
ca.plot.obj$cols[, 2]
),
Variable = c(
rep(row.lab, nrow(ca.plot.obj$rows)),
rep(col.lab, nrow(ca.plot.obj$cols))
)
)
}
dat <- dat |>
make_ca_plot_df(row.lab = "Construction", col.lab = "Medium") |>
dplyr::mutate(
Size = dplyr::if_else(Variable == "Construction", mean(tf), tf[Label])
)
# 非ASCII文字のラベルに対してwarningを出さないようにする
suppressWarnings({
ca_sum <- summary(ca_fit)
dim_var_percs <- ca_sum$scree[, "values2"]
})
dat |>
ggplot(aes(x = Dim1, y = Dim2, col = Variable, label = Label)) +
geom_vline(xintercept = 0, lty = "dashed", alpha = .5) +
geom_hline(yintercept = 0, lty = "dashed", alpha = .5) +
geom_jitter(aes(size = Size), alpha = .2, show.legend = FALSE) +
ggrepel::geom_label_repel(
data = \(x) dplyr::filter(x, Variable == "Construction"),
show.legend = FALSE
) +
ggrepel::geom_text_repel(
data = \(x) dplyr::filter(x, Variable == "Medium", sqrt(Dim1^2 + Dim2^2) > 0.25),
show.legend = FALSE
) +
scale_x_continuous(
limits = range(dat$Dim1) +
c(diff(range(dat$Dim1)) * -0.2, diff(range(dat$Dim1)) * 0.2)
) +
scale_y_continuous(
limits = range(dat$Dim2) +
c(diff(range(dat$Dim2)) * -0.2, diff(range(dat$Dim2)) * 0.2)
) +
scale_size_area(max_size = 12) +
labs(
x = paste0("Dimension 1 (", signif(dim_var_percs[1], 3), "%)"),
y = paste0("Dimension 2 (", signif(dim_var_percs[2], 3), "%)")
) +
theme_classic()
まとめ
ここで紹介したような、quantedaが実装しているオブジェクトとTIFにおけるコーパス(corpus)、トークン(token)、文書単語行列(dtm)とのあいだで変換する操作は、だいたい次の図のようにして実現することができます。
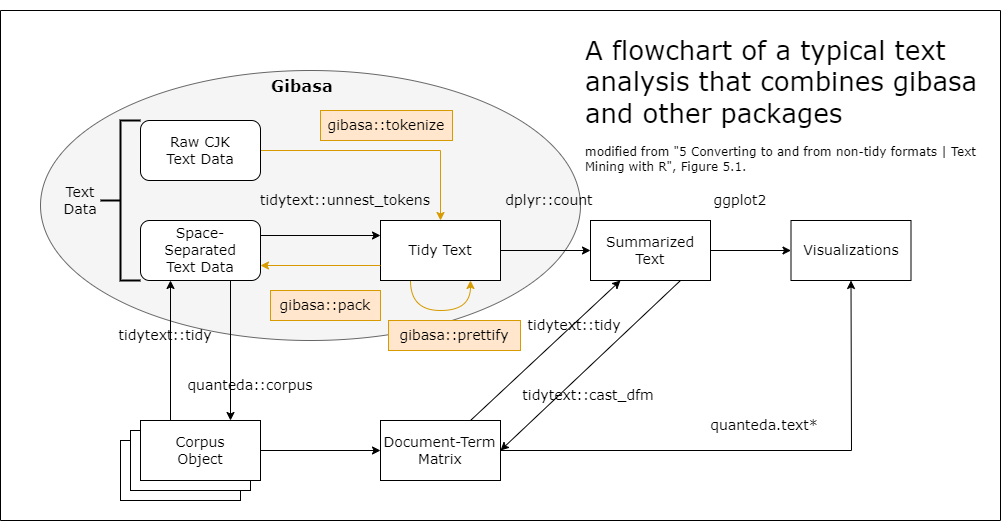
この図では「Text Data」として括られているのがTIFにおけるコーパスで、最下段の「Corpus Object」と「Document-Term Matrix」として図示されているのがquantedaにおけるオブジェクトになります。ちなみに、この図中にはありませんが、tidy textからコーパスのかたちを経ずにquantedaのtokensオブジェクトに変換するには、たとえば次のようにします。
toks |>
dplyr::filter(
pos %in% c(
"名詞",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語"
),
stringr::str_detect(token, "^[[:alnum:]]{2,}$")
) |>
dplyr::reframe(token = list(token), .by = doc_id) |>
tibble::deframe() |>
quanteda::as.tokens()
一度にぜんぶ覚えるのはむずかしいでしょうが、こうした変換の方法を一通り覚えておくと、Rでテキストデータを扱うためのさまざまなバッケージについて、臨機応変に使いこなせるようになるはずです。少しずつでも、ぜひマスターしてみてください。
セッション情報
sessioninfo::session_info()
paithiov909/gibasa documentation built on June 14, 2025, 4:31 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( tidy = "styler", collapse = TRUE, comment = "#>" ) set.seed(3179) require("ggplot2", quietly = TRUE)
はじめに
このページでは、quantedaとgibasaを用いた簡単なテキストマイニングを例に、quantedaやその他のRパッケージとのあいだでテキストデータをやりとりする方法を紹介します。ここでおこなっているようなテキスト分析の例としては、次のサイトも参考にしてください。
ちなみに、quantedaはstringiをラップした関数によって日本語の文書でも分かち書きできるので、手元の辞書に収録されている表現どおりに分かち書きしたい場合や、品詞情報が欲しい場合でないかぎりは、形態素解析器を使うメリットはあまりないかもしれません。stringiが利用しているICUのBoundary Analysisの仕様については、UAX#29などを参照してください。
Text Interchange Formats(TIF)
gibasaによる形態素解析の結果をquantedaなどと組み合わせて使ううえでは、Text Interchange Formats(TIF)という仕様に沿ったかたちのオブジェクトとしてテキストデータをもつことを意識すると便利です。
TIFというのは、2017年にrOpenSci Text Workshopで整備された、テキスト分析用のRパッケージのデザインパターンのようなものです。TIFでは、コーパス(corpus)、トークン(token)、文書単語行列(dtm)という3種類のオブジェクトの形式が定義されており、異なるパッケージ間で同様の形式を扱うようにすることで、複数のパッケージを通じて便利にテキスト分析を進められるようになっています。
このうち「コーパス」は、文書の集合をデータフレームあるいは名前付きベクトルの形式で保持したものです。
ldccrでは、livedoorニュースコーパスをデータフレームの形式のコーパスとして読み込むことができます。より厳密に言うと、データフレーム形式のコーパスは、少なくともdoc_idとtextという列を含むデータフレームなので、doc_id列は自分でつくる必要があります。コーパスにおけるdoc_id列は、文書によって一意なID列(character型である必要がある)で、text列は文書本体になります。「少なくとも」なので、このほかの列にここでのcategory列のような文書のメタ情報などが含まれる場合があります。
tbl <- ldccr::read_ldnws() |> dplyr::mutate(doc_id = as.character(dplyr::row_number())) |> dplyr::rename(text = body) tbl
livedoorニュースコーパスは文書分類をおこなうことを主な目的につくられたデータセットで、以下の9カテゴリのブログ記事からなっています。
- トピックニュース
- Sports Watch
- ITライフハック
- 家電チャンネル
- MOVIE ENTER
- 独女通信
- エスマックス
- livedoor HOMME
- Peachy
このうち一部だけをgibasaで形態素解析して、データフレームの形式の「トークン」としてもっておきます。トークンは、コーパスを文書ごとに適当な単位にまとめあげながら格納したものです。それぞれのトークンは単語だったり、単語のN-gramだったりします。
ここではKH Coderで採用されている品詞体系を参考に、形態素解析された語の品詞情報を適当な値に置き換えています。なお、こうしたデータフレームの形式のトークンは、しばしばtidy textとも呼ばれます。
toks <- tbl |> dplyr::select(doc_id, category, text) |> dplyr::slice_sample(prop = .8) |> dplyr::mutate( text = stringi::stri_trans_nfkc(text) |> stringi::stri_replace_all_regex("(https?\\://[[:alnum:]\\.\\-_/]+)", "\nURL\tタグ\n") |> stringi::stri_replace_all_regex("[\\s]{2,}", "\n") |> stringi::stri_trim_both() ) |> gibasa::tokenize(text, partial = TRUE) |> gibasa::prettify( col_select = c("POS1", "POS2", "POS3", "Original") ) |> dplyr::mutate( pos = dplyr::case_when( (POS1 == "タグ") ~ "タグ", (is.na(Original) & stringr::str_detect(token, "^[[:alpha:]]+$")) ~ "未知語", (POS1 == "感動詞") ~ "感動詞", (POS1 == "名詞" & POS2 == "一般" & stringr::str_detect(token, "^[\\p{Han}]{1}$")) ~ "名詞C", (POS1 == "名詞" & POS2 == "一般" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "名詞B", (POS1 == "名詞" & POS2 == "一般") ~ "名詞", (POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "地域") ~ "地名", (POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "人名") ~ "人名", (POS1 == "名詞" & POS2 == "固有名詞" & POS3 == "組織") ~ "組織名", (POS1 == "名詞" & POS2 == "形容動詞語幹") ~ "形容動詞", (POS1 == "名詞" & POS2 == "ナイ形容詞語幹") ~ "ナイ形容詞", (POS1 == "名詞" & POS2 == "固有名詞") ~ "固有名詞", (POS1 == "名詞" & POS2 == "サ変接続") ~ "サ変名詞", (POS1 == "名詞" & POS2 == "副詞可能") ~ "副詞可能", (POS1 == "動詞" & POS2 == "自立" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "動詞B", (POS1 == "動詞" & POS2 == "自立") ~ "動詞", (POS1 == "形容詞" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "形容詞B", (POS1 == "形容詞" & POS2 == "非自立") ~ "形容詞(非自立)", (POS1 == "形容詞") ~ "形容詞", (POS1 == "副詞" & stringr::str_detect(token, "^[\\p{Hiragana}]+$")) ~ "副詞B", (POS1 == "副詞") ~ "副詞", (POS1 == "助動詞" & Original %in% c("ない", "まい", "ぬ", "ん")) ~ "否定助動詞", .default = "その他" ) ) |> dplyr::select(doc_id, category, token_id, token, pos, Original) |> dplyr::rename(original = Original) toks
Tidy textからdfmへの変換
さて、実際にこういったトークンからさまざまな分析をするには、トークンを品詞などによって取捨選択しながら、分析したい単位ごとにグルーピングして集計する必要があります。
簡単に集計するだけであれば、次のようにdplyrの関数を使って集計することができます。こうした文書ID、単語と、単語の文書内頻度の3つ組のかたちをしたデータフレームは、summarized textという呼び方をすることがあるようです。
toks |> dplyr::filter(!pos %in% c("その他", "タグ")) |> dplyr::count(doc_id, token) |> dplyr::arrange(dplyr::desc(n))
一方で、たとえば、特定のトークンの連なりは連語と見なして一つのトークンとして集計したいといった場合には、dplyrだけで集計するのはなかなか大変です。そういったより複雑なケースでは、quantedaの枠組みと組み合わせて使ったほうが便利なことがあります。
たとえば、IPA辞書では正しく解析されない「スマートフォン」といった語について、形態素解析した結果を確認した後に再度まとめあげて集計したい場合、quantedaを使うと次のように書くことができます。また、ここでは、うまく「記号」として解析されなかった記号類を除外するために、正規表現にマッチするトークンだけに絞り込んで集計しています。
dfm <- toks |> dplyr::filter(!pos %in% c("その他", "タグ")) |> gibasa::pack() |> quanteda::corpus() |> quanteda::tokens(what = "fastestword", remove_url = TRUE) |> quanteda::tokens_compound( quanteda::phrase(c("スマート フォン", "s - max")) ) |> quanteda::tokens_keep( "^[[:alnum:]]{2,}$", valuetype = "regex" ) |> quanteda::dfm() dfm
quanteda::dfm()の戻り値は「文書単語行列(dtm)」を疎行列オブジェクト(dgCMatrix of 'Matrix' package)として保持したものです(厳密には、dgCMatrixをスロットにもっているS4オブジェクト)。dfmオブジェクトは、qunateda.textstats::textstat_frequency()などを使って、さらに集計することができます。
dat <- dfm |> quanteda.textstats::textstat_frequency() |> dplyr::as_tibble() head(dat) dat |> ggplot(aes(x = frequency, y = docfreq)) + geom_jitter() + gghighlight::gghighlight( frequency > 2500 & docfreq < 2000 ) + ggrepel::geom_text_repel( aes(label = feature), max.overlaps = 50 ) + scale_x_log10() + scale_y_sqrt() + theme_bw() + labs(x = "出現回数", y = "文書数")
Summarized textからdfmへの変換
「文書単語行列(dtm)」は、トークンを集計した結果を縦長のデータフレームとしてもっているsummarized textを横に展開したものだと理解できます。両者は表現が異なるだけで、もっているデータとしては同じものであるため、quantedaにおけるdfmオブジェクトはtidytext::cast_dfm()を使ってsummarized textを変換することによって得ることもできます。
dfm <- toks |> dplyr::filter( pos %in% c( "名詞", "地名", "人名", "組織名", "固有名詞", "動詞", "未知語" ), stringr::str_detect(token, "^[[:alnum:]]{2,}$") ) |> dplyr::mutate( token = dplyr::if_else(is.na(original), tolower(token), original), token = paste(token, pos, sep = "/") ) |> dplyr::count(doc_id, token) |> tidytext::cast_dfm(doc_id, token, n)
dfmオブジェクトはquanteda::dfm_*という名前の関数を使って語彙を減らしたり、単語頻度に重みづけをしたりすることができます。
ここではquanteda.textstats::textstat_simil()で単語間の類似度を得て、階層的クラスタリングをしてみます。
clusters <- dfm |> quanteda::dfm_trim(min_termfreq = 40, termfreq_type = "rank") |> quanteda::dfm_weight(scheme = "boolean") |> quanteda.textstats::textstat_simil(margin = "features", method = "dice") |> rlang::as_function(~ 1 - .)() |> as.dist() |> hclust(method = "ward.D2") dfm |> quanteda::dfm_trim(min_termfreq = 40, termfreq_type = "rank") |> quanteda::colSums() |> tibble::enframe() |> dplyr::mutate( clust = (clusters |> cutree(k = 5))[name] ) |> ggplot(aes(x = value, y = name, fill = factor(clust))) + geom_bar(stat = "identity", show.legend = FALSE) + scale_x_sqrt() + ggh4x::scale_y_dendrogram(hclust = clusters) + labs(x = "出現回数", y = element_blank()) + theme_bw()
dfmからSummarized textへの変換
dfmオブジェクトはtidytext::tidy()でsummarized textのかたちに変換することができます。tidytext::tidy()とtidytext::cast_dfm()をあわせて使うことで、dfmオブジェクトとsummarized textのあいだで自由に変換しあうことができます。
dfm <- dfm |> quanteda::dfm_trim( min_termfreq = 40, termfreq_type = "rank" ) |> tidytext::tidy() |> dplyr::left_join( tbl |> dplyr::mutate(doc_id = factor(dplyr::row_number())) |> dplyr::select(doc_id, category), by = dplyr::join_by(document == doc_id) ) |> tidytext::cast_dfm(category, term, count)
ここでは、quanteda.textmodels::textmodel_ca()を使ってdfmオブジェクトを対応分析にかけます。この関数の戻り値はcaパッケージのオブジェクトと互換性があるため、library(ca)としてからplot()に渡すことでバイプロットを描画することができます。
ca_fit <- dfm |> quanteda.textmodels::textmodel_ca(nd = 2, sparse = TRUE) library(ca) dat <- plot(ca_fit)
より見やすい表現としては、次のようにしてggplot2でバイプロットを描画することもできます。
tf <- quanteda::colSums(dfm) make_ca_plot_df <- function(ca.plot.obj, row.lab = "Rows", col.lab = "Columns") { tibble::tibble( Label = c( rownames(ca.plot.obj$rows), rownames(ca.plot.obj$cols) ), Dim1 = c( ca.plot.obj$rows[, 1], ca.plot.obj$cols[, 1] ), Dim2 = c( ca.plot.obj$rows[, 2], ca.plot.obj$cols[, 2] ), Variable = c( rep(row.lab, nrow(ca.plot.obj$rows)), rep(col.lab, nrow(ca.plot.obj$cols)) ) ) } dat <- dat |> make_ca_plot_df(row.lab = "Construction", col.lab = "Medium") |> dplyr::mutate( Size = dplyr::if_else(Variable == "Construction", mean(tf), tf[Label]) ) # 非ASCII文字のラベルに対してwarningを出さないようにする suppressWarnings({ ca_sum <- summary(ca_fit) dim_var_percs <- ca_sum$scree[, "values2"] }) dat |> ggplot(aes(x = Dim1, y = Dim2, col = Variable, label = Label)) + geom_vline(xintercept = 0, lty = "dashed", alpha = .5) + geom_hline(yintercept = 0, lty = "dashed", alpha = .5) + geom_jitter(aes(size = Size), alpha = .2, show.legend = FALSE) + ggrepel::geom_label_repel( data = \(x) dplyr::filter(x, Variable == "Construction"), show.legend = FALSE ) + ggrepel::geom_text_repel( data = \(x) dplyr::filter(x, Variable == "Medium", sqrt(Dim1^2 + Dim2^2) > 0.25), show.legend = FALSE ) + scale_x_continuous( limits = range(dat$Dim1) + c(diff(range(dat$Dim1)) * -0.2, diff(range(dat$Dim1)) * 0.2) ) + scale_y_continuous( limits = range(dat$Dim2) + c(diff(range(dat$Dim2)) * -0.2, diff(range(dat$Dim2)) * 0.2) ) + scale_size_area(max_size = 12) + labs( x = paste0("Dimension 1 (", signif(dim_var_percs[1], 3), "%)"), y = paste0("Dimension 2 (", signif(dim_var_percs[2], 3), "%)") ) + theme_classic()
まとめ
ここで紹介したような、quantedaが実装しているオブジェクトとTIFにおけるコーパス(corpus)、トークン(token)、文書単語行列(dtm)とのあいだで変換する操作は、だいたい次の図のようにして実現することができます。
この図では「Text Data」として括られているのがTIFにおけるコーパスで、最下段の「Corpus Object」と「Document-Term Matrix」として図示されているのがquantedaにおけるオブジェクトになります。ちなみに、この図中にはありませんが、tidy textからコーパスのかたちを経ずにquantedaのtokensオブジェクトに変換するには、たとえば次のようにします。
toks |> dplyr::filter( pos %in% c( "名詞", "地名", "人名", "組織名", "固有名詞", "動詞", "未知語" ), stringr::str_detect(token, "^[[:alnum:]]{2,}$") ) |> dplyr::reframe(token = list(token), .by = doc_id) |> tibble::deframe() |> quanteda::as.tokens()
一度にぜんぶ覚えるのはむずかしいでしょうが、こうした変換の方法を一通り覚えておくと、Rでテキストデータを扱うためのさまざまなバッケージについて、臨機応変に使いこなせるようになるはずです。少しずつでも、ぜひマスターしてみてください。
セッション情報
sessioninfo::session_info()
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.