Nothing
SwimmeR
In SwimmeR: Data Import, Cleaning, and Conversions for Swimming Results
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
library(SwimmeR)
library(dplyr)
SwimmeR was developed to work with results from swimming competitions. Results are often shared as web pages (.html) or PDF documents, which are nice to read, but make data difficult to access.
SwimmeR solves this problem by importing & cleaning .html and .pdf files containing swimming results, and returns a tidy data frame.
Importing is performed by read_results which takes as an argument a file path as file and a node (for .html only, defaults to '"pre").
In addition to this vignette I do a lot of demos on how to use SwimmeR at my blog Swimming + Data Science.
Reading PDF Results
ISL results are handled differently, see ISL section below
SwimmeR includes Texas-Florida-Indiana.pdf, results from a tri-meet between the three schools. It can be read in as such:
TX_FL_IN_path <- system.file("extdata", "Texas-Florida-Indiana.pdf", package = "SwimmeR")
TX_FL_IN_text <- read_results(file = TX_FL_IN_path)
TX_FL_IN_text[294:303]
Here we see a subsection of the meet - the top three finishers in the Women's 100 Yard Breaststroke featuring Olympic gold medalist, and the SwimmeR package's favorite swimmer, Lilly King.
The next step is to convert this data to a data frame using swim_parse. Because swim_parse works on text strings it is very sensitive to typos and/or nonstandard naming conventions. "Texas-Florida-Indiana.pdf" has two examples of these potential problems.
The first is that Indiana University is sometimes entered as Indiana University, with two spaces between Indiana and University. This is a problem in versions of Swimmer < 0.7.0 because swim_parse will interpret two spaces as a column separator, and will not properly capture Indiana University (two spaces) as a team name. In versions of Swimmer >= 0.7.0 the extra space won't cause a problem at all.
The second issue is that Texas and Florida are styled as Texas, University of and Florida, University of which I personally disapprove of. It won't cause any issues in SwimmeR versions >= 0.7.0, but will in earlier versions.
Both of these issues can be fixed with the typo and replacement arguments to swim_parse. Elements of typo will be replaced by the element of replacement with which they share an index, so all instances of the first element of typo will be replaced by the first element of replacement etc. etc. Not specifying typo or replacement will not produce an error, but might negatively impact the results. If your results look strange, or are missing values, look for typos related to those swims.
There is a another argument to swim_parse, called avoid, which will be addressed in the section on reading in html results below.
TX_FL_IN_df <-
swim_parse(
file = TX_FL_IN_text,
typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0
replacement = c("Indiana University", "") # not required in versions >= 0.7.0
)
Here are those same Women's 100 Breaststroke results, as a data frame in tidy format:
TX_FL_IN_df[102:104,]
\
Reading HTML Results
Reading .html results is very similar to reading pdf results, but a value must be specified to node, containing which CSS node the read_results should look in for results. Here results from the New York State 2003 Girls Championship meet will be read in, from the "pre" node.
NYS_link <- "http://www.nyhsswim.com/Results/Girls/2003/NYS/Single.htm"
NYS_text <- read_results(file = NYS_link, node = "pre")
NYS_text_path <- system.file("extdata", "NYS_text.RDS", package = "SwimmeR")
NYS_text <- readRDS(NYS_text_path)
NYS_text[587:598]
Looking at the raw results above one will see that line 2 is a header and contains NY State Rcd:, showing the New York State record. Lines of this type are a common feature in swimming results, but because they contain a recognizable swimming time, without being a result per say, they can cause problems for swim_parse. Like typos these will not cause an error, but might produce nonsense rows in the resulting data frame. swim_parse deals with strings that should not be included in results with the avoid argument. By default avoid contains a lot of common formulations of these header items under avoid_default. You can create your own list of strings as pass it to avoid, or add to avoid_default via avoid_new <- c(avoid_default, "your string here"). Avoid should also include "r\\:" if your results have reaction times (avoid_default already includes "r\\:").
NYS_df <- swim_parse(file = NYS_text, avoid = c("NY State Rcd:"))
NYS_df[358:360,]
\
Splits
By setting splits = TRUE inside swim_parse one can read in split times. Splits will then be read in as either 50 splits (the default), or 25 splits, depending on the value provided to split_length. Let's look at those same Texas/Florida/Indiana Results again.
TX_FL_IN_df_splits <-
swim_parse(
read_results(TX_FL_IN_path),
# typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0
# replacement = c("Indiana University", ""), # not required in versions >= 0.7.0
splits = TRUE,
split_length = 50
)
TX_FL_IN_df_splits[100:102,]
We can now see split times for the 50 and 100 walls, plus more split columns that are filled in for the longer races.
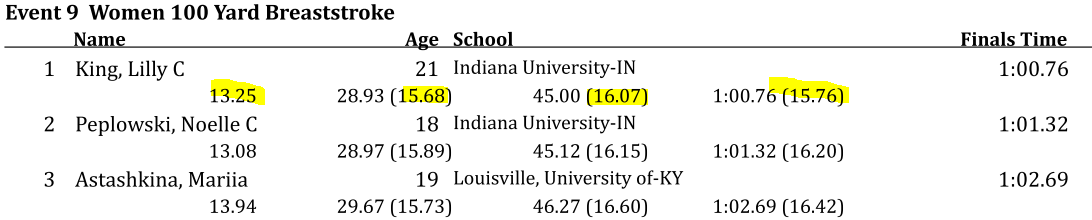
Care is needed however, because split times are handled inconsistently in source data. For example in these results, from a meet between Indiana and Louisville splits are sometimes by 25:
 {width=80%}
{width=80%}
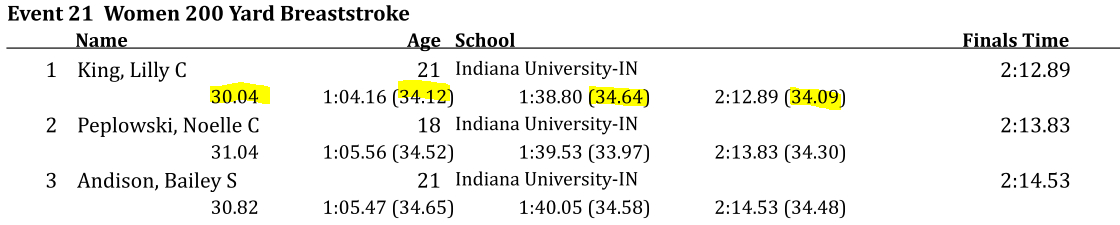
and sometimes by 50 - within the same meet.
 {width=80%}
{width=80%}
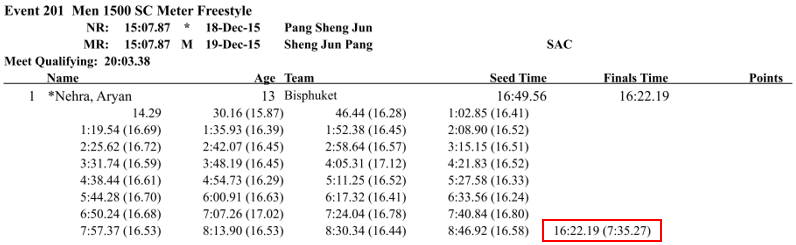
Another example, in these 2017 Junior National results from Singapore, the 1500m splits are by 25 for the first 800m, and then the last split is for the final 700m of the race.
 {width=80%}
{width=80%}
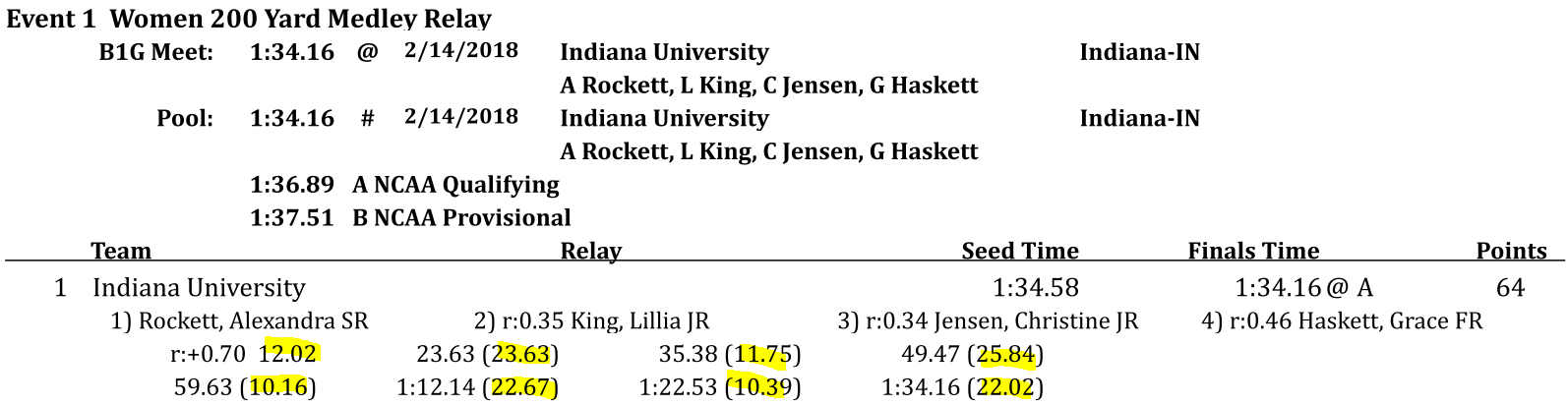
Relays are also traditionally handled differently, with splits summing for individual athletes. In the 2018 Big Ten championship results Lilly King does not split a 25.84 on the second 25 of the breaststroke leg of Indiana's 200 medley relay, rather 25.84 was her time for the entire 50 yard breaststroke leg.
 {width=80%}
{width=80%}
Just be forewarned - splits, even within the same meet, will often require some after-import attention and swimming-specific knowledge to clean.
Formatting Splits
The preferred format for splits is "lap" format, where each split is the duration of a single lap (or length) of the pool. Splits are sometimes also presented in cumulative format, where each split is the total time elapsed at a particular point in the race. For example consider this data frame, containing two swimmers swimming the exact same times and splits, but with one in lap format and the other in cumulative format.
df <- data.frame(
Place = 1,
Name = c("Lenore Lap", "Casey Cumulative"),
Team = rep("KVAC", 2),
Event = rep("Womens 200 Freestyle", 2),
Finals = rep("1:58.00", 2),
Split_50 = rep("28.00", 2),
Split_100 = c("31.00", "59.00"),
Split_150 = c("30.00", "1:29.00"),
Split_200 = c("29.00", "1:58.00")
)
df
Cumulative splits can be converted to lap splits with the split_to_lap function.
df %>%
filter(Name == "Casey Cumulative") %>%
splits_to_lap()
Splits that are already in lap format can be avoided using the threshold parameter in splits_to_lap. The value is threshold is effectively a maximum lap split value. If no swimmer in the data frame will swim a split slower (i.e. greater than) 35.00 then 35.00 makes a good threshold value. Failing to set threshold in data frames containing both lap and cumulative split times will result in nonsensical splits and warnings from SwimmeR.
df %>%
splits_to_lap(threshold = 35)
Converting to cumulative, although not the preferred format, is possible as well with splits_to_cumulative.
df %>%
filter(Name == "Lenore Lap") %>%
splits_to_cumulative()
Similarly, setting threshold allows the exclusion of splits that are already in cumulative format. Here threshold is a minimum split value.
df %>%
splits_to_cumulative(threshold = 20)
\
Relay Swimmers
The final argument to swim_parse is relay_swimmers, which defaults to FALSE. Setting relay_swimmers = TRUE will cause swim_parse to read in the names of relay swimmers for each relay, and add them to the normal swim_parse output as columns. I don't love this, because the result is having individual swimmers as rows, and relay swimmers as columns (because relay swimmers are associated with their particular relay). This is not very tidy, and SwimmeR strives to be tidy. Still, the functionality does exist.
TX_FL_IN_df_relay_swimmers <-
swim_parse(
read_results(TX_FL_IN_path),
# typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0
# replacement = c("Indiana University", ""), # not required in versions >= 0.7.0
relay_swimmers = TRUE
)
TX_FL_IN_df_relay_swimmers[1:3,]
It is of course also possible to read in both splits and relay swimmers, by setting both of the relevant arguments to TRUE.
\
Reading ISL Results
International Swimming League results are technically .pdf files, but they're formatted very differently, so they have their own special function, swim_parse_ISL. Handling of ISL results is otherwise the same, with the file first going to read_results and then to swim_parse_ISL, returning a data frame.
The SwimmeR package's favorite swimmer, Lilly King, is involved in the ISL. Let's see what she got up to at this particular meet.
file_url <-
"https://github.com/gpilgrim2670/Pilgrim_Data/raw/master/ISL/Season_1_2019/ISL_16112019_CollegePark_Day_1.pdf"
if (SwimmeR:::is_link_broken(file_url) == TRUE) {
warning("External data unavailable")
} else {
file_read <- read_results(file_url)
df_ISL <- swim_parse_ISL(file = file_read)
df_ISL[which(df_ISL$Name == "KING Lilly"), ]
}
Two first place finishes for Ms. King - very nice! Otherwise all the normal information is here, place, time, team, event etc. Beginning in the 2020 season ISL starts reporting points in their results, which swim_parse_ISL will also read. swim_parse_ISL also handles splits and relay swimmers via the arguments splits and relay_swimmers. All ISL meets thus far have splits at the 50 walls, so there is no split_length argument. Otherwise splits and relay swimmers are handled exactly the same way as swim_parse, detailed above.
\
Formatting Swimming Times
Once results are captured in R as tidy data frames the real fun can begin - but there's another problem. Times in swimming are recorded as minutes:seconds.hundredth. This is fine when a time is less than a minute, because 59.99 can be of class numeric in R, but times greater than or equal to a minute 1:00.00 are stuck as class character. SwimmeR provides two functions, sec_format and mmss_format to convert between times as seconds (for doing math), and times as minutes:seconds.hundredths, for swimming-specific display.
data(King200Breast)
King200Breast
Included in SwimmeR is King200Breast, containing all Lilly King's 200 Breaststroke times for her NCAA career. Times recorded as character values, in standard minutes:seconds.hundredth format. We can use sec_format to format them as seconds, and mmss_format to go back to minutes:seconds.hundredth. Both functions work well with the tidyverse packages.
King200Breast <- King200Breast %>%
dplyr::mutate(Time_sec = sec_format(Time),
Time_swim_2 = mmss_format(Time_sec))
King200Breast
This is useful for comparing times, or plotting
plot(King200Breast$Date, King200Breast$Time_sec, axes = FALSE, ann = FALSE)
axis(1, at = c(16800, 17200, 17600, 18000), labels = c(2016, 2017, 2018, 2019))
axis(2, at = c(125, 130, 135, 140), labels = mmss_format(c(125, 130, 135, 140)), las = 1)
par(mar = c(5,7,4,2) + 0.3)
The same thing can be done in ggplot.
King200Breast %>%
ggplot(aes(x = Date, y = Time_sec)) +
geom_point() +
scale_y_continuous(labels = scales::trans_format("identity", mmss_format)) +
theme_classic() +
labs(y= "Time",
title = "Lilly King NCAA 200 Breaststroke")
\
Using get_mode to clean swimming data
Swim teams often have abbreviations, for example Lilly King swam for Indiana University, and sometimes "Indiana University" was listed as her team name. Other times though the team might be listed as "IU" or "IUWSD". James (Sulley) Sullivan swam (probably) for Monsters University, or MU Regularizing these names is a useful part of cleaning data.
Name <- c(rep("Lilly King", 5), rep("James Sullivan", 3))
Team <- c(rep("IU", 2), "Indiana", "IUWSD", "Indiana University", rep("Monsters University", 2), "MU")
df <- data.frame(Name, Team, stringsAsFactors = FALSE)
df
Lilly has 4 different teams, but all of them are actually the same team. Similarly Sulley has two teams, but actually only one. Using get_mode to return the most frequently occurring team for each swimmer is easier than manually specifying every swimmer's team.
df <- df %>%
dplyr::group_by(Name) %>%
dplyr::mutate(Team = get_mode(Team))
df
\
Drawing brackets
To aid in making single elimination brackets for tournaments and shoot-outs SwimmeR has draw_bracket. Any number of teams between 5 and 64 can be used, with byes automatically assigned to higher seeds.
teams <- c("red", "orange", "yellow", "green", "blue", "indigo", "violet")
draw_bracket(teams = teams)
Now add the results of round two:
round_two <- c("red", "yellow", "blue", "indigo")
draw_bracket(teams = teams,
round_two = round_two)
And round three:
round_three <- c("red", "blue")
draw_bracket(teams = teams,
round_two = round_two,
round_three = round_three)
And crown the champion:
```r
champion <- "red"
draw_bracket(teams = teams,
round_two = round_two,
round_three = round_three,
champion = champion)
Try the SwimmeR package in your browser
Any scripts or data that you put into this service are public.
SwimmeR documentation built on March 31, 2023, 8:27 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, comment = "#>" )
library(SwimmeR) library(dplyr)
SwimmeR was developed to work with results from swimming competitions. Results are often shared as web pages (.html) or PDF documents, which are nice to read, but make data difficult to access.
SwimmeR solves this problem by importing & cleaning .html and .pdf files containing swimming results, and returns a tidy data frame.
Importing is performed by read_results which takes as an argument a file path as file and a node (for .html only, defaults to '"pre").
In addition to this vignette I do a lot of demos on how to use SwimmeR at my blog Swimming + Data Science.
Reading PDF Results
ISL results are handled differently, see ISL section below
SwimmeR includes Texas-Florida-Indiana.pdf, results from a tri-meet between the three schools. It can be read in as such:
TX_FL_IN_path <- system.file("extdata", "Texas-Florida-Indiana.pdf", package = "SwimmeR") TX_FL_IN_text <- read_results(file = TX_FL_IN_path)
TX_FL_IN_text[294:303]
Here we see a subsection of the meet - the top three finishers in the Women's 100 Yard Breaststroke featuring Olympic gold medalist, and the SwimmeR package's favorite swimmer, Lilly King.
The next step is to convert this data to a data frame using swim_parse. Because swim_parse works on text strings it is very sensitive to typos and/or nonstandard naming conventions. "Texas-Florida-Indiana.pdf" has two examples of these potential problems.
The first is that Indiana University is sometimes entered as Indiana University, with two spaces between Indiana and University. This is a problem in versions of Swimmer < 0.7.0 because swim_parse will interpret two spaces as a column separator, and will not properly capture Indiana University (two spaces) as a team name. In versions of Swimmer >= 0.7.0 the extra space won't cause a problem at all.
The second issue is that Texas and Florida are styled as Texas, University of and Florida, University of which I personally disapprove of. It won't cause any issues in SwimmeR versions >= 0.7.0, but will in earlier versions.
Both of these issues can be fixed with the typo and replacement arguments to swim_parse. Elements of typo will be replaced by the element of replacement with which they share an index, so all instances of the first element of typo will be replaced by the first element of replacement etc. etc. Not specifying typo or replacement will not produce an error, but might negatively impact the results. If your results look strange, or are missing values, look for typos related to those swims.
There is a another argument to swim_parse, called avoid, which will be addressed in the section on reading in html results below.
TX_FL_IN_df <- swim_parse( file = TX_FL_IN_text, typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0 replacement = c("Indiana University", "") # not required in versions >= 0.7.0 )
Here are those same Women's 100 Breaststroke results, as a data frame in tidy format:
TX_FL_IN_df[102:104,]
\
Reading HTML Results
Reading .html results is very similar to reading pdf results, but a value must be specified to node, containing which CSS node the read_results should look in for results. Here results from the New York State 2003 Girls Championship meet will be read in, from the "pre" node.
NYS_link <- "http://www.nyhsswim.com/Results/Girls/2003/NYS/Single.htm" NYS_text <- read_results(file = NYS_link, node = "pre")
NYS_text_path <- system.file("extdata", "NYS_text.RDS", package = "SwimmeR") NYS_text <- readRDS(NYS_text_path)
NYS_text[587:598]
Looking at the raw results above one will see that line 2 is a header and contains NY State Rcd:, showing the New York State record. Lines of this type are a common feature in swimming results, but because they contain a recognizable swimming time, without being a result per say, they can cause problems for swim_parse. Like typos these will not cause an error, but might produce nonsense rows in the resulting data frame. swim_parse deals with strings that should not be included in results with the avoid argument. By default avoid contains a lot of common formulations of these header items under avoid_default. You can create your own list of strings as pass it to avoid, or add to avoid_default via avoid_new <- c(avoid_default, "your string here"). Avoid should also include "r\\:" if your results have reaction times (avoid_default already includes "r\\:").
NYS_df <- swim_parse(file = NYS_text, avoid = c("NY State Rcd:"))
NYS_df[358:360,]
\
Splits
By setting splits = TRUE inside swim_parse one can read in split times. Splits will then be read in as either 50 splits (the default), or 25 splits, depending on the value provided to split_length. Let's look at those same Texas/Florida/Indiana Results again.
TX_FL_IN_df_splits <- swim_parse( read_results(TX_FL_IN_path), # typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0 # replacement = c("Indiana University", ""), # not required in versions >= 0.7.0 splits = TRUE, split_length = 50 ) TX_FL_IN_df_splits[100:102,]
We can now see split times for the 50 and 100 walls, plus more split columns that are filled in for the longer races.
Care is needed however, because split times are handled inconsistently in source data. For example in these results, from a meet between Indiana and Louisville splits are sometimes by 25:
{width=80%}
and sometimes by 50 - within the same meet.
{width=80%}
Another example, in these 2017 Junior National results from Singapore, the 1500m splits are by 25 for the first 800m, and then the last split is for the final 700m of the race.
{width=80%}
Relays are also traditionally handled differently, with splits summing for individual athletes. In the 2018 Big Ten championship results Lilly King does not split a 25.84 on the second 25 of the breaststroke leg of Indiana's 200 medley relay, rather 25.84 was her time for the entire 50 yard breaststroke leg.
{width=80%}
Just be forewarned - splits, even within the same meet, will often require some after-import attention and swimming-specific knowledge to clean.
Formatting Splits
The preferred format for splits is "lap" format, where each split is the duration of a single lap (or length) of the pool. Splits are sometimes also presented in cumulative format, where each split is the total time elapsed at a particular point in the race. For example consider this data frame, containing two swimmers swimming the exact same times and splits, but with one in lap format and the other in cumulative format.
df <- data.frame( Place = 1, Name = c("Lenore Lap", "Casey Cumulative"), Team = rep("KVAC", 2), Event = rep("Womens 200 Freestyle", 2), Finals = rep("1:58.00", 2), Split_50 = rep("28.00", 2), Split_100 = c("31.00", "59.00"), Split_150 = c("30.00", "1:29.00"), Split_200 = c("29.00", "1:58.00") ) df
Cumulative splits can be converted to lap splits with the split_to_lap function.
df %>% filter(Name == "Casey Cumulative") %>% splits_to_lap()
Splits that are already in lap format can be avoided using the threshold parameter in splits_to_lap. The value is threshold is effectively a maximum lap split value. If no swimmer in the data frame will swim a split slower (i.e. greater than) 35.00 then 35.00 makes a good threshold value. Failing to set threshold in data frames containing both lap and cumulative split times will result in nonsensical splits and warnings from SwimmeR.
df %>% splits_to_lap(threshold = 35)
Converting to cumulative, although not the preferred format, is possible as well with splits_to_cumulative.
df %>% filter(Name == "Lenore Lap") %>% splits_to_cumulative()
Similarly, setting threshold allows the exclusion of splits that are already in cumulative format. Here threshold is a minimum split value.
df %>% splits_to_cumulative(threshold = 20)
\
Relay Swimmers
The final argument to swim_parse is relay_swimmers, which defaults to FALSE. Setting relay_swimmers = TRUE will cause swim_parse to read in the names of relay swimmers for each relay, and add them to the normal swim_parse output as columns. I don't love this, because the result is having individual swimmers as rows, and relay swimmers as columns (because relay swimmers are associated with their particular relay). This is not very tidy, and SwimmeR strives to be tidy. Still, the functionality does exist.
TX_FL_IN_df_relay_swimmers <- swim_parse( read_results(TX_FL_IN_path), # typo = c("Indiana University", ", University of"), # not required in versions >= 0.7.0 # replacement = c("Indiana University", ""), # not required in versions >= 0.7.0 relay_swimmers = TRUE ) TX_FL_IN_df_relay_swimmers[1:3,]
It is of course also possible to read in both splits and relay swimmers, by setting both of the relevant arguments to TRUE.
\
Reading ISL Results
International Swimming League results are technically .pdf files, but they're formatted very differently, so they have their own special function, swim_parse_ISL. Handling of ISL results is otherwise the same, with the file first going to read_results and then to swim_parse_ISL, returning a data frame.
The SwimmeR package's favorite swimmer, Lilly King, is involved in the ISL. Let's see what she got up to at this particular meet.
file_url <- "https://github.com/gpilgrim2670/Pilgrim_Data/raw/master/ISL/Season_1_2019/ISL_16112019_CollegePark_Day_1.pdf" if (SwimmeR:::is_link_broken(file_url) == TRUE) { warning("External data unavailable") } else { file_read <- read_results(file_url) df_ISL <- swim_parse_ISL(file = file_read) df_ISL[which(df_ISL$Name == "KING Lilly"), ] }
Two first place finishes for Ms. King - very nice! Otherwise all the normal information is here, place, time, team, event etc. Beginning in the 2020 season ISL starts reporting points in their results, which swim_parse_ISL will also read. swim_parse_ISL also handles splits and relay swimmers via the arguments splits and relay_swimmers. All ISL meets thus far have splits at the 50 walls, so there is no split_length argument. Otherwise splits and relay swimmers are handled exactly the same way as swim_parse, detailed above.
\
Formatting Swimming Times
Once results are captured in R as tidy data frames the real fun can begin - but there's another problem. Times in swimming are recorded as minutes:seconds.hundredth. This is fine when a time is less than a minute, because 59.99 can be of class numeric in R, but times greater than or equal to a minute 1:00.00 are stuck as class character. SwimmeR provides two functions, sec_format and mmss_format to convert between times as seconds (for doing math), and times as minutes:seconds.hundredths, for swimming-specific display.
data(King200Breast)
King200Breast
Included in SwimmeR is King200Breast, containing all Lilly King's 200 Breaststroke times for her NCAA career. Times recorded as character values, in standard minutes:seconds.hundredth format. We can use sec_format to format them as seconds, and mmss_format to go back to minutes:seconds.hundredth. Both functions work well with the tidyverse packages.
King200Breast <- King200Breast %>% dplyr::mutate(Time_sec = sec_format(Time), Time_swim_2 = mmss_format(Time_sec)) King200Breast
This is useful for comparing times, or plotting
plot(King200Breast$Date, King200Breast$Time_sec, axes = FALSE, ann = FALSE) axis(1, at = c(16800, 17200, 17600, 18000), labels = c(2016, 2017, 2018, 2019)) axis(2, at = c(125, 130, 135, 140), labels = mmss_format(c(125, 130, 135, 140)), las = 1) par(mar = c(5,7,4,2) + 0.3)
The same thing can be done in ggplot.
King200Breast %>% ggplot(aes(x = Date, y = Time_sec)) + geom_point() + scale_y_continuous(labels = scales::trans_format("identity", mmss_format)) + theme_classic() + labs(y= "Time", title = "Lilly King NCAA 200 Breaststroke")
\
Using get_mode to clean swimming data
Swim teams often have abbreviations, for example Lilly King swam for Indiana University, and sometimes "Indiana University" was listed as her team name. Other times though the team might be listed as "IU" or "IUWSD". James (Sulley) Sullivan swam (probably) for Monsters University, or MU Regularizing these names is a useful part of cleaning data.
Name <- c(rep("Lilly King", 5), rep("James Sullivan", 3)) Team <- c(rep("IU", 2), "Indiana", "IUWSD", "Indiana University", rep("Monsters University", 2), "MU") df <- data.frame(Name, Team, stringsAsFactors = FALSE) df
Lilly has 4 different teams, but all of them are actually the same team. Similarly Sulley has two teams, but actually only one. Using get_mode to return the most frequently occurring team for each swimmer is easier than manually specifying every swimmer's team.
df <- df %>% dplyr::group_by(Name) %>% dplyr::mutate(Team = get_mode(Team)) df
\
Drawing brackets
To aid in making single elimination brackets for tournaments and shoot-outs SwimmeR has draw_bracket. Any number of teams between 5 and 64 can be used, with byes automatically assigned to higher seeds.
teams <- c("red", "orange", "yellow", "green", "blue", "indigo", "violet") draw_bracket(teams = teams)
Now add the results of round two:
round_two <- c("red", "yellow", "blue", "indigo") draw_bracket(teams = teams, round_two = round_two)
And round three:
round_three <- c("red", "blue") draw_bracket(teams = teams, round_two = round_two, round_three = round_three)
And crown the champion: ```r champion <- "red" draw_bracket(teams = teams, round_two = round_two, round_three = round_three, champion = champion)
Try the SwimmeR package in your browser
Any scripts or data that you put into this service are public.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.