In GlossyBoat/foqat: Field Observation Quick Analysis Toolkit
knitr::opts_chunk$set(
collapse = TRUE,
comment = "#>"
)
Haze is a common form of air pollution that we see. Particulate matter is the main cause of aggravating haze weather pollution. Studying the physicochemical characteristics of particulate matter has been a popular direction in the field of atmospheric science. Among them, the particle size distribution characteristics can provide important information on the source, formation and growth mechanism of particulate matter particles.
Unlike gas pollution, particle size spectral data involve three dimensions: time, particle size, and number concentration. This makes the processing and visualization of particle size spectral data a bit more problematic than conventional gas data.
The functions provided by the FOQAT package in R language bridge the process from reading to visualization, making the process much lighter and more natural.
The flow and functions are shown in the figure below:
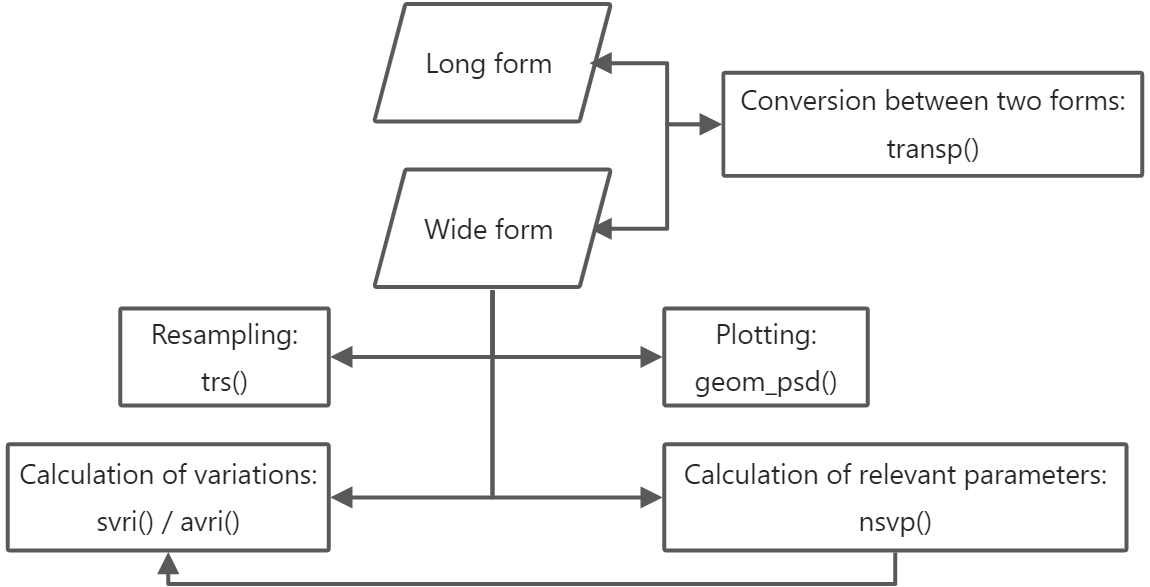 {width=500px}
{width=500px}
To begin, we’ll load foqat and pre-process the SMPS data in foqat.
library(foqat)
#Read built-in files
dn_table = read.delim(system.file("extdata", "smps.txt", package = "foqat"), check.names = FALSE)
dn1_table=dn_table[,c(1,5:148)]
#Set time format
dn1_table[,1]=as.POSIXct(dn1_table[,1], format="%m/%d/%Y %H:%M:%S", tz="GMT")
head(dn1_table[,1:5])
Plot the time series of particle size distribution
geom_psd() allows you to plot wide form data.
The input is the dataframe of particle size data. The first column of input is datetime; the other columns are number concentration (N, unit: #/cm3) or log number concentration (dN/dlogdp, unit: # cm~-3~) for each particle size channel. Column names of the other columns are the middle particle size for each particle size channel.
geom_psd(dn1_table,fsz=10)
Calculate relevant parameters and convert data type betwenn dn and dn/dlogdp
nsvp() can help you Calculate surface Area, Volume, Mass of particle by particle number concentrations.
The results are divided into two tables, one for the sub-grain size segments dN, dN_dlogdp, dS, dV, dM, dS_dlogdp, dV_dlogdp, dM_dlogdp; and one for the total grain size segments N, S, V, M.
dn2_table=nsvp(dn1_table,dlogdp=FALSE)
head(dn2_table[["df_channels"]])
head(dn2_table[["df_total"]])
nsvp can also help you convert data type betwenn dn and dn/dlogdp.
dndlogdp_list=dn2_table[["df_channels"]][,c(1,2,4)]
head(dndlogdp_list)
Convert between wide form and long form
transp()converts two forms of tables back and forth, inputting one, then outputting the other.
dndlogdp_table=transp(dndlogdp_list)
head(dndlogdp_table[,1:5])
Resample wide form particle size distribution
trs() can Resample and cut time series of wide form particle size distribution.
dndlogdp_table=transp(dndlogdp_list)
head(dndlogdp_table[,1:5])
Calculate the average variation
avri() can calculate the average variation of particle size time series.
x=avri(dndlogdp_table, st="2021-06-07 00:00:00", bkip="5 mins", mode="ncycle", value=288)
head(x[,1:5])
Calculate the average distribution of particle size spectral parameters
avri() can calculate the average variation of particle size time series.
#Extract the time series of the required parameters from the results of the nsvp calculation, here the surface area is used as an example
dsdlogdp_list=dn2_table[["df_channels"]][,c(2,5)]
#Calculate the average distribution of surface area particle size spectra
ds_avri=avri(dsdlogdp_list,mode="custom",value=1)
head(ds_avri)
We can plot it.
par(mar=c(5,5,2,2))
plot(x=ds_avri[,1],y=ds_avri[,2], pch=16, xlab="Midrange (nm)", ylab=expression("dS (cm"^2*"/cm"^3*")"), col="#597ef7")
GlossyBoat/foqat documentation built on Oct. 3, 2023, 1:27 p.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set( collapse = TRUE, comment = "#>" )
Haze is a common form of air pollution that we see. Particulate matter is the main cause of aggravating haze weather pollution. Studying the physicochemical characteristics of particulate matter has been a popular direction in the field of atmospheric science. Among them, the particle size distribution characteristics can provide important information on the source, formation and growth mechanism of particulate matter particles.
Unlike gas pollution, particle size spectral data involve three dimensions: time, particle size, and number concentration. This makes the processing and visualization of particle size spectral data a bit more problematic than conventional gas data.
The functions provided by the FOQAT package in R language bridge the process from reading to visualization, making the process much lighter and more natural.
The flow and functions are shown in the figure below:
{width=500px}
To begin, we’ll load foqat and pre-process the SMPS data in foqat.
library(foqat) #Read built-in files dn_table = read.delim(system.file("extdata", "smps.txt", package = "foqat"), check.names = FALSE) dn1_table=dn_table[,c(1,5:148)] #Set time format dn1_table[,1]=as.POSIXct(dn1_table[,1], format="%m/%d/%Y %H:%M:%S", tz="GMT") head(dn1_table[,1:5])
Plot the time series of particle size distribution
geom_psd() allows you to plot wide form data.
The input is the dataframe of particle size data. The first column of input is datetime; the other columns are number concentration (N, unit: #/cm3) or log number concentration (dN/dlogdp, unit: # cm~-3~) for each particle size channel. Column names of the other columns are the middle particle size for each particle size channel.
geom_psd(dn1_table,fsz=10)
Calculate relevant parameters and convert data type betwenn dn and dn/dlogdp
nsvp() can help you Calculate surface Area, Volume, Mass of particle by particle number concentrations.
The results are divided into two tables, one for the sub-grain size segments dN, dN_dlogdp, dS, dV, dM, dS_dlogdp, dV_dlogdp, dM_dlogdp; and one for the total grain size segments N, S, V, M.
dn2_table=nsvp(dn1_table,dlogdp=FALSE) head(dn2_table[["df_channels"]]) head(dn2_table[["df_total"]])
nsvp can also help you convert data type betwenn dn and dn/dlogdp.
dndlogdp_list=dn2_table[["df_channels"]][,c(1,2,4)] head(dndlogdp_list)
Convert between wide form and long form
transp()converts two forms of tables back and forth, inputting one, then outputting the other.
dndlogdp_table=transp(dndlogdp_list) head(dndlogdp_table[,1:5])
Resample wide form particle size distribution
trs() can Resample and cut time series of wide form particle size distribution.
dndlogdp_table=transp(dndlogdp_list) head(dndlogdp_table[,1:5])
Calculate the average variation
avri() can calculate the average variation of particle size time series.
x=avri(dndlogdp_table, st="2021-06-07 00:00:00", bkip="5 mins", mode="ncycle", value=288) head(x[,1:5])
Calculate the average distribution of particle size spectral parameters
avri() can calculate the average variation of particle size time series.
#Extract the time series of the required parameters from the results of the nsvp calculation, here the surface area is used as an example dsdlogdp_list=dn2_table[["df_channels"]][,c(2,5)] #Calculate the average distribution of surface area particle size spectra ds_avri=avri(dsdlogdp_list,mode="custom",value=1) head(ds_avri)
We can plot it.
par(mar=c(5,5,2,2)) plot(x=ds_avri[,1],y=ds_avri[,2], pch=16, xlab="Midrange (nm)", ylab=expression("dS (cm"^2*"/cm"^3*")"), col="#597ef7")
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.