In martscht/PsyMSc1: Übungen für die Seminare im Sommersemester 2020
library(learnr)
library(gradethis)
library(shiny)
library(fontawesome)
library(lavaan)
data(fairplayer, package = 'PsyMSc1')
knitr::opts_chunk$set(exercise.checker = gradethis::grade_learnr)
abbrev <- function(X, begin = 'Latent Variables', end = NULL, ellipses = 'both', shift = 2, ...) {
tmp <- capture.output(lavaan::summary(X,...))
if (is.null(begin)) begin <- 1
else begin <- grep(begin, tmp, fixed = TRUE)[1]
if (is.null(end)) end <- length(tmp)-shift
else end <- grep(end, tmp, fixed = TRUE)[grep(end, tmp, fixed = TRUE) > begin][1]-shift
if (ellipses == 'both') {
cat('[...]\n', paste(tmp[begin:end], collapse = '\n'), '\n[...]\n')
}
if (ellipses == 'top') {
cat('[...]\n', paste(tmp[begin:end], collapse = '\n'))
}
if (ellipses == 'bottom') {
cat(paste(tmp[begin:end], collapse = '\n'), '\n[...]\n')
}
if (ellipses == 'none') {
cat(paste(tmp[begin:end], collapse = '\n'))
}
}
Einleitung
Im Verlauf dieses Seminars soll neben der Einführung in die Theorie und Hintergründe multivariater Verfahren auch eine Einführung in deren Umsetzung gegeben werden, sodass Sie in der Lage sind, diese Verfahren in Ihrem zukünftigen akademischen und beruflichen Werdegang zu benutzen. Diese Umsetzung möchten wir Ihnen mit lavaan zeigen - dem meistverbreiteten Paket für multivariate Verfahren wie z.B. konfirmatorische Faktorenanalyse (CFA), Pfadanalyse oder Strukturgleichungsmodellierung (SEM) in R. Allein im März 2020 wurde lavaan über 30 000 mal heruntergeladen; es wird in allen Bereichen der psychologischen Forschung genutzt und wurde in über 6 500 sozialwissenschaftflichen Veröffentlichungen zitiert.
Dieses Tutorial bietet eine Einführung in lavaan. Im Zentrum stehen dabei die Grundgedanken und die typische Weise, in der man in lavaan bei Analysen vorgeht. Um diese Ideen und Vorgehensweisen zu erkunden, betrachten wir ein Beispiel aus dem letzten Semester mal aus dieser neuen Perspektive.
Wir beginnen das Tutorial aber zunächst mit einer Auffrischung Ihrer R-Fähigkeiten. Auch wenn Sie im Umgang mit R sehr geübt sind, nehmen Sie sich bitte trotzdem ein paar Minuten, um sich noch einmal intensiv mit den Befehlen auseinanderzusetzen, die für dieses Semester von zentraler Bedeutung sind. Sollten Sie wenig Übung im Umgang mit R haben, oder wenn Sie einfach noch einmal eine etwas detaillierte Einführung in R lesen möchten, finden Sie auf Pandar die R-Einführung aus dem Bachelorstudiengang.
Für die Durchführung dieses Tutorials benötigen Sie nichts weiter als dieses Browserfenster. Bitte veärndern Sie während Sie die Übung in diesem Browserfenster machen nichts in der R-Sitzung, mit der Sie diese Übung gestartet haben.
Nach dem Ende der Übung finden Sie im OLAT Kurs ein kurzes Quiz mit Bezug zu den Inhalten dieser Sitzung.
Den gesamten R-Code, der in dieser Sitzung genutzt wird, können Sie r fontawesome::fa("download") hier herunterladen.
R Grundlagen Wiederbelebung {#Wiederbelebung}
In diesem Abschnitt gucken wir uns zur Wiederholung noch einmal ein paar Grundzüge des Datenmanagements in R an, bevor wir eine multiple Regression durchführen und deren Ergebnisse genauer inspizieren.
Beispieldatensatz
Der Datensatz, den wir in dieser Sitzung benutzen, stammt aus einer Studie von Bull, Schultze & Scheithauer (2009), in der die Effektivität eines Interventionsprogramms zur Bullyingprävention bei Jugendlichen untersucht wurde. Der Datensatz liegt bereits im R-eigenen .rda-Format vor, sodass uns ein Import der Daten erspart bleibt. Stattdessen können wir einfach mit load arbeiten, um die Daten zu laden:
load('fairplayer.rda')
Hinweis: Wenn Sie mit diesen Daten in einem eigenen R-Skript Dinge ausprobieren möchten, können Sie die Daten mit data(fairplayer, package = 'PsyMSc1') laden.
Verschaffen Sie sich im folgenden Fenster einen Überblick über die Daten. Wie viele und was für Variablen enthält der Datensatz? Von wie vielen Personen liegen Daten vor? Einige Befehle sind schon beispielhaft vorgegeben - Sie können aber auch andere Befehle ergänzen, um mehr Details zu erfahren!
# Namen der Variablen abfragen
names(fairplayer)
# Anzahl der Zeilen und Spalten
nrow(fairplayer)
ncol(fairplayer)
# Struktur des Datensatz - Informationen zur Variablentypen
str(fairplayer)
# Datensatz ansehen
fairplayer
Der Datensatz, den wir hier betrachten, enthält verhaltensbezogene Selbstberichte auf jeweils drei Items zur relationalen Aggression (ra), Empathie (em) und sozialen Intelligenz (si). Diese insgesamt 9 Indikatoren liegen zu drei Messzeitpunkten (t1, t2 und t3) vor. Die über str angeforderte Struktur verrät uns außerdem, dass diese Variablen allesamt integer (int), also ganzzahlig, sind. Über die Items hinaus sind vier weitere Variablen im Datensatz enthalten, die den Personenidentifikator (id), die Klasse (class), die Interventionsgruppe (grp) und das Geschlecht (sex) der Jugendlichen kodieren.
Datenmanagement
Eines der großen Themen in diesem Semester wird es sein, möglichst gute und zuverlässige Schätzungen für die Werte einzelner Personen auf verschiedenen psychologischen Konstrukten zu erhalten. Traditionellerweise werden dafür häufig sogenannte Skalenwerte genutzt. Diese werden meistens als Mittelwerte der Items, die ein gemeinsames Konstrukt erheben sollen, berechnet.
Für die weiteren Analysen in dieser Sitzung werden wir die Skalenwerte der relationalen Aggression, Empathie und sozialen Intelligenz zum ersten Zeitpunkt benötigen. Naheliegend wäre es, diese durch einfache Arithmetik zu bestimmen, z.B. für die relationale Aggression:
fairplayer$rat1 <- (fairplayer$ra1t1 + fairplayer$ra2t1 + fairplayer$ra3t1) / 3
Von diesem Vorgehen möchten wir an dieser Stelle explizit abraten. Grund dafür ist, dass es hier nicht möglich ist, den Umgang mit fehlenden Werte zu beeinflussen. Darüber hinaus wird diese Strategie mit zunehmender Anzahl von Items pro Skala sehr schreibaufwändig. Daher sollten wir dieses Vorgehen nicht nur aus Faulheit umgehen, sondern auch, weil mehr Syntax auch immer mehr mögliche Fehlerquellen bedeutet. Stattdessen empfehlen wir, mit dem rowMeans Befehel zu arbeiten. Z.B. für die relationale Aggression:
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
Das Argument na.rm = TRUE bewirkt, dass wir den Skalenwert auch dann berechnen, wenn fehlende Werte auf einzelnen Items vorliegen. Erstellen Sie die Skalenwerte für die Empathie emt1 und die soziale Intelligenz sit1 im folgenden Fenster! Mit dem "Hint" Button erhalten Sie Hinweise, durch die Sie durchblättern können. Der letzte "Hint" ist dann die vollständige Lösung. Keine Sorge falls Sie hier Fehler machen: die Skalenwerte stehen Ihnen in den folgenden Übungen trotzdem zur Verfügung.
# Weisen Sie die Variablen mit $ dem Datensatz zu!
# fairplayer$sit1 oder fairplayer$emt1
# Nutzen Sie die rowMeans-Funktion
?rowMeans
# Die Namen der Items:
names(fairplayer)
# Vollständige Lösung
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
Deskriptivstatistik
Die drei Skalenwerte aus dem letzten Abschnitt sollten wir uns - zusammen mit ein paar anderen Variablen - mal genauer angucken, um ein Gefühl dafür zu entwickeln, wie die Lage in dieser Erhebung ist. Der Klassiker, um sich einen Überblick zu verschaffen, ist die R-eigene summary Funktion. Bei dieser handelt es sich um eine generische Funktion, die man auf viele verschiedene Objekte in R anwenden kann. Die Aufbereitung des Ergebnisses hängt dabei immer davon ab, auf was für ein Objekt man sie angewendet hat.
Nehmen wir unsere drei Skalenwerte: bei allen handelt es sich um numerische Variablen (in R: num) - in R wird also davon ausgegangen, dass es Variablen mit mindestens Intervallskalenniveau sind (mehr Informationen zu Skalenniveaus in der psychologischen Methodenlehre finden Sie in Eid, Gollwitzer und Schmitt (2017) im Kapitel 5). Für solche Variablen wird in R mit summary eine sogenannte Fünf-Punkt-Zusammenfassung ausgegeben:
summary(fairplayer$rat1)
Den Spitzfindigen unter Ihnen fällt auf, dass hier mehr als fünf Informationen ausgegeben werden. Die klassische Fünf-Punkt-Zusammenfassung besteht aus Minimum, Maximum und den drei Quartilen. In R wird zusätzlich noch das arithmetische Mittel und die Anzahl der fehlenden Werte ausgegeben.
Für nominalskalierte Variablen, wie z.B. die Gruppenzugehörigkeit grp, sieht die Zusammenfassung ein wenig anders aus:
summary(fairplayer$grp)
Weil diese Variable in R als factor angelegt ist, wird sie als nominalskaliert behandelt und es werden keine Statistiken berechnet, die für solche Variablen nicht aussagekräftig sind. Stattdessen wird lediglich eine Häufigkeitstabelle erzeugt.
Deskriptivstatistiken können aber auch einzeln erzeugt werden - z.B. mit mean für Mittelwerte. Versuchen Sie im untenstehenden Feld für den Skalenwert der relationalen Aggression die Standardabweichung mit sd zu bestimmen!
Mit dem Button "Run Code" können Sie das R-Skript ausführen, um Dinge auszuprobieren. Wenn Sie auf "Submit Answer" klicken, wird geprüft, ob ihr Skript richtig war. Hier wird keine Bewertung vorgenommen und Sie können so viele Antworten abschicken, wie Sie wollen. Dieser Schritt ist ausschließlich dazu gedacht, dass Sie selbst überprüfen können, ob Ihr Vorgehen richtig ist.
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
res <- sd(fairplayer$rat1, na.rm = TRUE)
grade_result(
fail_if(~ is.na(.result), 'Wegen fehlender Werte kann die Standardabweichung nicht bestimmt werden. Finden Sie das geeignete Argument, dass die fehlenden Werte für die Berechnung ausschließt.'),
fail_if(~ (!is.na(.result) & !identical(.result, res)), 'Haben Sie die korrekte Variable angesprochen?'),
pass_if(~ identical(.result, res)),
correct = 'Sehr gut! Der Umgang mit fehlenden Werten muss in vielen R-Funktionen explizit angesprochen werden.',
incorrect = 'Leider falsch.',
glue_correct = '{.correct}',
glue_incorrect = '{.incorrect} {.message}')
Kovarianzen und Korrelationen
Neben univariaten Statistiken sind für eine Veranstaltung mit dem Titel "Multivariate Verfahren" natürlich Zusammenhangsmaße von zentraler Bedeutung. Die beiden gängigsten Formen um Zusammenhänge in der Psychologie zu untersuchen, sind Kovarianzen und Korrelationen. Bivariat können wir diese in R sehr einfach über cov bzw. cor anfordern:
cov(fairplayer$rat1, fairplayer$sit1, use = 'complete')
cor(fairplayer$rat1, fairplayer$sit1, use = 'complete')
Mit dem Argument use wird der Umgang mit fehlenden Werten gesteuert - in diesem Fall sollen alle listenweise vollständigen Beobachtungen genutzt werden, also alle Fälle, in denen keine der beteiligten Variablen fehlt. Das ist im Moment noch kein Unterschied zum paarweisen Fallausschluss, weil wir immer nur zwei Variablen betrachten. Unten werden wir aber Korrelationen und Kovarianzen für mehrere Variablen gleichzeitig bestimmen. Eine kurze Wiederholung aus Statistik I im Bachelorstudiengang: die Produkt-Moment-Korrelation ergibt sich aus $\frac{cov(x, y)}{sd(x)sd(y)}$.
Um Zusammenhänge nicht immer nur für zwei Variablen bestimmen zu können, ist es auch möglich, die Funktionen cov und cor auf ganze Matrizen und Datensätze anzuwenden. Nehmen wir unsere drei Skalen in einen gemeinsamen Datensatz auf:
scales <- fairplayer[, c('rat1', 'emt1', 'sit1')]
Jetzt können wir die Korrelationsmatrix für die drei Variablen gleichzeitig bestimmen:
cor(scales, use = 'complete')
Das Gleiche funktioniert natürlich auch mit der Kovarianzmatrix:
cov(scales, use = 'complete')
Letztere ist für viele Analysen, die wir in diesem Semester behandeln werden zentral, weil sie in einer Matrix (beinahe) alle relevanten Informationen über interindividuelle Unterschiede (Varianzen) und deren Zusammenhänge (Kovarianzen) enthält. Die Verwendung von use = 'complete' bewirkt hier, dass nur Personen in die Berechnung aufgenommen werden, die auf keiner der drei Variablen fehlende Werte haben. In unserem Fall bleiben also von den ursprünglich r nrow(fairplayer) Personen noch r nrow(na.omit(scales)) übrig.
Varianzen sind in der Diagonale der Matrix enthalten:
diag(cov(scales, use = 'complete'))
Einen Überblick über die Befehle für Matrix-Algebra in R finden Sie auf der Quick-R Website.
Wiederholung: Regression {#Regression}
Im letzten Semester haben Sie die lm Funktion kennengelernt, um lineare Modelle in R zu berechnen. Um diese Funktion zu verwenden, müssen meist zwei Argumente an lm weitergegeben werden:
formula: Das Modell in klassischer R-Formelschreibweisedata: Der Datensatz, auf den dieses Modell angewendet werden soll
Die Formelschreibweise folgt in R einer einfachen Grundstruktur: Y ~ X. Gelesen werden kann $Y$ "vorhergesagt durch" $X$. Mehrere unabhängige Variablen, z.B. $X_1$ und $X_2$ können im Wesentlichen durch drei Operatoren verbunden sein:
X1 + X2: Für additive Modelle (nur Haupteffekte von $X_1$ und $X_2$)X1 : X2: Für Interaktionen (nur der Interaktionseffekt $X_1 \cdot X_2$)X1 * X2: Als Kurzschreibweise für X1 + X2 + X1:X2
Darüber hinaus können noch einige andere Operatoren genutzt werden (mehr Informationen finden Sie mit ?formula) - z.B. kann mit - ein Effekt bewusst unterdrückt werden. Eine "Variable", die in Regressionen häufig als Prädiktor aufgenommen wird, ist die Konstante 1. Wenn man eine abhängige Variable auf eine Konstante regressiert, ist das entsprechende Regressionsgewicht der (bedingte) Mittelwert - in Regressionsanalysen häufig als Achsenabschnitt oder Intercept bezeichnet. Für eine Wiederholung der Grundgedanken der Regressionsanalyse können Sie einen Blick in Eid et al. (2017) Kapitel 17 und 19) werfen.
Modell erstellen
Im Beispiel geht es um die drei Konstrukte relationale Aggression, soziale Intelligenz und Empathie von Jugendlichen. Da durch Interventionen soziale Intelligenz als Kompetenz gut vermittelbar ist, ist von Interesse, wie sich höhere soziale Intelligenz auf relationale Aggression auswirkt. Wichtig ist dabei, dass auch Empathie in die Gleichung einbezogen wird, weil diese konsistent ein negativer Prädiktor relationaler Aggression ist; wenn ich negative Empfindungen anderer mitfühlen kann, ist es weniger wahrscheinlich, dass ich durch mein Verhalten solche negativen Empfindungen hervorrufen möchte. Die Beziehung zu sozialer Intelligenz war in der Literatur lange aber nicht so eindeutig - erst in den späten 2000er Jahren wurde die Befundlage hierzu eindeutig (aus dieser Zeit stammt der Datensatz).
Um diese Fragestellung zu bearbeiten, können wir mit dem Datensatz eine multiple Regression zur Vorhersage relationaler Aggression durch Empathie und soziale Intelligenz durchführen. Erstellen Sie im folgenden Kasten ein Modell mit dem einfallsreichen Namen mod, in dem die Ergebnisse der additiven Regression $RA_1 = \alpha + \beta_1EM_1 + \beta_2SI_1 + \epsilon$ abgelegt sind!
# Vollständige Lösung
mod <- lm(rat1 ~ 1 + sit1 + emt1, fairplayer)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
mod <- lm(rat1 ~ sit1 + emt1, fairplayer)
mod <- lm(rat1 ~ sit1 + emt1, fairplayer)
Regressionergebnisse {#Regressionergebnisse}
Es gibt jetzt eine Vielzahl von Möglichkeiten, um die Ergebnisse des Modells zu inspizieren. Mit dem einfachen Aufruf des Modells erhalten wir zunächst nur die Regressiongewichte:
mod
Wir können uns die Koeffizienten mit coef auch als Vektor ausgeben lassen, was den Vorteil hat, dass wir sie in anderen Funktionen weiterverwenden können. Zum Beispiel in einem Scatterplot:
plot(fairplayer$rat1 ~ fairplayer$sit1)
abline(coef(mod)[1], coef(mod)[2])
Üblicherweise wird aber auch bei lm-Objekten der summary-Befehl genutzt, um die Ergebnisse genauer zu inspizieren. Nutzen Sie diesen Befehl, um sich einen Überblick zu verschaffen. Welche Regressionsgewichte sind bedeutsam von 0 verschieden? Wie groß ist der Determinationskoeffizient $R^2$?
summary(mod)
Der Abschnitt Coefficients enthält die relevanten Aussagen zu den Regressionsgewichten. Um uns nur diesen anzusehen, können wir das $ benutzen, um, wie bei allen R-Objekten, nur einen spezifischen Abschnitt zu betrachten.
summary(mod)$coef
Die Zeilennamen dieser Tabelle (r paste(rownames(summary(mod)$coef))) geben an, zu welchem Prädiktor das Regressiongewicht gehört. In der Spalte Estimate wird das Regressionsgewicht angegeben. Hier wird also für zwei Jugendliche, die sich um eine Einheit in sozialer Intelligenz (sit1) unterscheiden, aber das gleiche Ausmaß an Empathie (emt1) haben, ein Unterschied in der relationalen Aggression von r formatC(coef(mod)[2], format = 'f', digits = 2) Einheiten vorhergesagt. Bei gleicher Empathie führt höhere soziale Intelligenz also zu mehr relationaler Aggression. Die nächste Spalte Std. Error gibt den Standardfehler an, welcher das Ausmaß an Unsicherheit quantifiziert, das wir in der Schätzung des Populationswertes dieses Regressionsgewichts aufgrund unserer Stichprobe haben. Das Verhältnis aus Regressionsgewicht und Standardfehler ($\frac{r formatC(coef(mod)[2], format = 'f', digits = 2)}{r formatC(summary(mod)$coef[2,2], format = 'f', digits = 2)} = r formatC(summary(mod)$coef[2,3], format = 'f', digits = 2)$) folgt - wenn die Voraussetzungen der Regressionsanalyse halten - einer $t$-Verteilung mit $n - k - 1$ Freiheitsgraden und wird deswegen in der Tabelle als t Value geführt. Bei der Bestimmung der Freiheitsgrade entspricht $n$ der Anzahl der Beobachtungen und $k$ der Anzahl der Prädiktoren. Bei ausreichend großer Anzahl von Freiheitsgraden ist die $t$-Verteilung nicht mehr von der Standardnormalverteilung unterscheidbar, sodass in anderer Software hier häufig der $z$-Test genutzt wird.
Weil wir wissen, wie wahrscheinlich es ist, unter der $t$-Verteilung mit r summary(mod)$df[2] Freiheitsgraden einen Wert von r formatC(summary(mod)$coef[2,3], format = 'f', digits = 2) zu beobachten, können wir (in der letzten Spalte) einen $p$-Wert bestimmen. In diesem Fall heißt es also, dass, wenn in der Population der wahre Wert dieses Regressionsgewichts 0 wäre, die Wahrscheinlichkeit in unserer Stichprobe ein Regressionsgewicht von r formatC(coef(mod)[2], format = 'f', digits = 2) oder extremer zu finden r formatC(summary(mod)$coef[2,4], format = 'f', digits = 5) ist. "Extremer" heißt hierbei, dass das Regressionsgewicht vom Betrag her größer sein müsste.
Versuchen Sie nach dem gleichen Prinzip, nach dem wir oben die Koeffiziententabelle aus der summary extrahiert haben, den Determinationskoeffizienten zu extrahieren, um eine Aussage über die inhaltliche Relevanz dieses Regressionsmodells zu gewinnen!
Mit dem Button "Run Code" können Sie das R-Skript ausführen um Dinge auszuprobieren. Wenn Sie auf "Submit Answer" klicken, wird geprüft, ob ihr Skript richtig war. Hier wird keine Bewertung vorgenommen und Sie können so viele Antworten abschicken, wie Sie wollen. Dieser Schritt ist ausschließlich dazu gedacht, dass Sie selbst überprüfen können, ob Ihr Vorgehen richtig ist.
# Im Englischen wird der Determinationskoeffizient häufig als "R Squared" bezeichnet
# Namen aller Elemente in der summary:
names(summary(mod))
# Vollständige Lösung
summary(mod)$r.squared
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
mod <- lm(rat1 ~ sit1 + emt1, fairplayer)
res1 <- summary(mod)$r.squared
res2 <- summary(mod)$adj.r.squared
grade_result(
pass_if(~ identical(.result, res1)),
pass_if(~ identical(.result, res2)),
correct = 'Sehr gut! Diese Form der Extraktion bestimmter Elemente werden wir im Verlauf des Semester öfter verwenden.',
incorrect = 'Leider falsch. Schauen Sie sich das Vorgehen bei der Koeffiziententabelle noch einmal genauer an.',
glue_correct = '{.correct}',
glue_incorrect = '{.incorrect}')
lavaan
Alle Dinge, die wir in den bisherigen Abschnitten besprochen haben, sind eine Wiederholung von Konzepten aus dem Bachelorstudium oder der vergangenen Semester gewesen. In diesem Semester werden wir hauptsächlich mit dem R Paket lavaan arbeiten. Der Name ist dabei ein Akronym für latent variable analysis. Im Rest dieser Sitzung werden wir uns die Kerngedanken des Pakets und das grundsätzliche Vorgehen zur Modellschätzung am Beispiel der multiplen Regression ansehen. Mehr Informationen zu lavaan finden Sie unter lavaan.org.
Drei-Schritt Verfahren {#Schritte}
Der Grundlegende Prozess der Modellierung folgt in lavaan drei Schritten. Folgende Abbildung soll das etwas verdeutlichen:
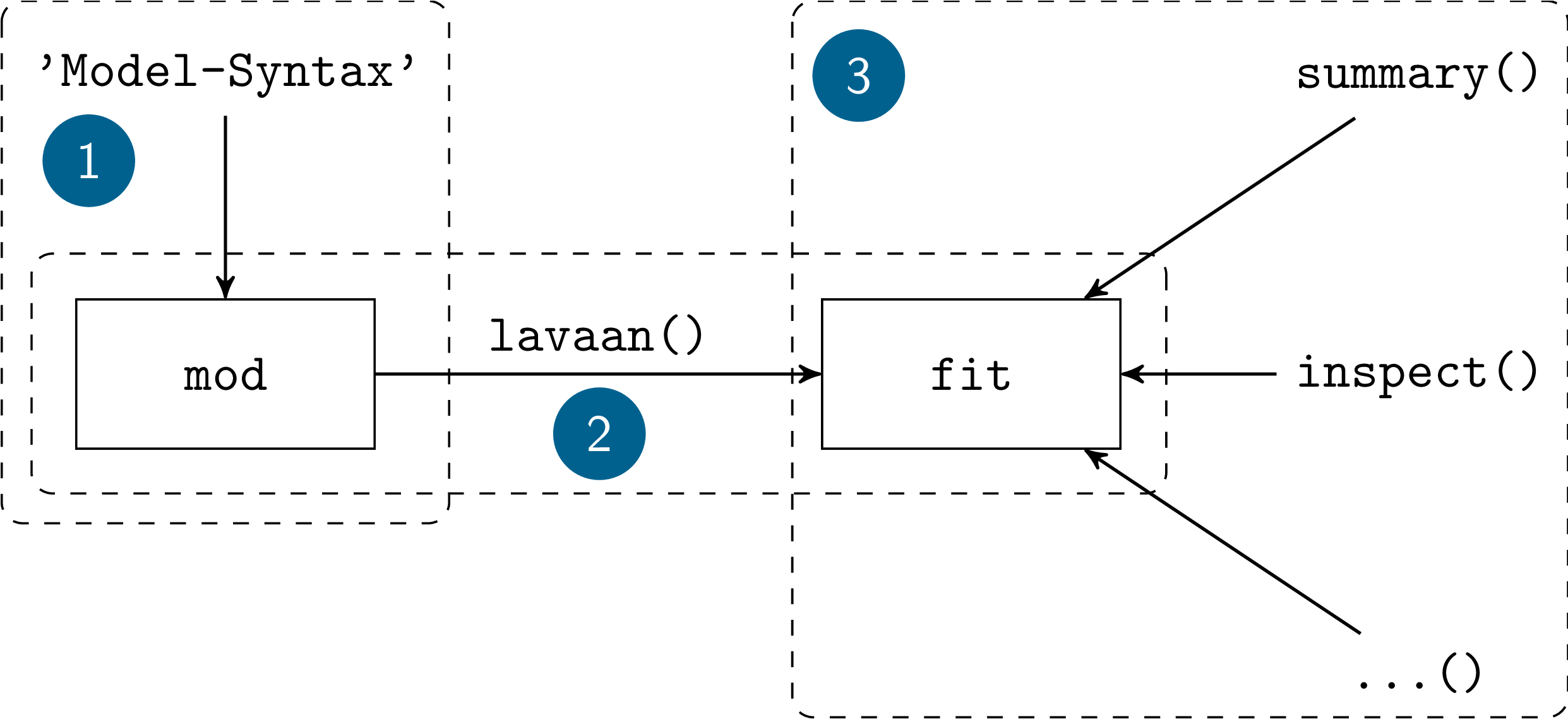
Im 1. Schritt schreiben wir ein Modell als Text und legen es in einem Objekt (z.B. mod) ab. Dieses Modell geben wir dann im 2. Schritt an die Kernfunktionen von lavaan weiter und halten die Ergebnisse wieder in einem Objekt (z.B. fit) fest. Der Name fit verdeutlicht dabei, dass das Model auf die Daten angepasst wurde, die Ergebnisse also eine durch Empirie aktualisierte Fassung unseres ursprünglich rein theoretischen Modells sind. Die Ergebnisse, die in diesem Objekt enthalten sind, können wir im 3. Schritt mit einer Vielzahl von "Helferfunktionen", wie dem allgemeinen summary, genauer untersuchen.
Pfaddiagramme
Die Model-Syntax von lavaan ist eine grafische Sprache. Das heißt, dass die Syntax so gedacht ist, dass man dabei das Pfaddiagramm in Worten beschreibt. Im Verlauf des Semesters werden wir noch diverse Modelle mit Pfaddiagrammen darstellen und dabei immer mal wieder neue Komponenten kennenlernen. Im Wesentlichen bilden Pfaddiagramme aber die beiden möglichen Beziehungen zwischen drei Typen von "Variablen" ab.

Mit diesen fünf sehr grundlegenden Elementen lassen sich erstaunlich viele Modelle darstellen, die in der psychologischen Forschung genutzt werden. Wir können z.B. eine einfache Regression zur Vorhersagen eines Kriteriums $Y$ durch einen Prädiktor $X$ aufstellen. Wir haben also zwei manifeste Variablen (in Rechtecken) und eine gerichtete Verbindung zwischen den beiden (die Regression). Wie üblich, benennen wir die Regression mit $\beta$:
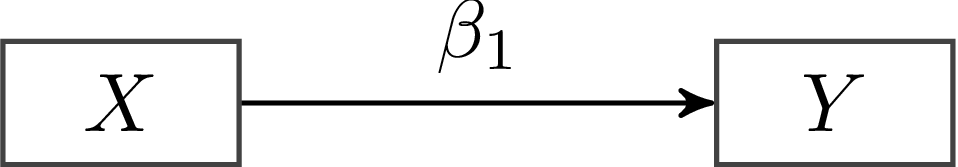
Was diese Abbildung also darstellt ist $Y = \beta \cdot X$. Für eine vollständige Regressionsgleichung fehlen allerdings noch ein paar Dinge. Als erstes nehmen wir das Intercept hinzu - also der Wert, der für $Y$ bei $X = 0$ vorhergesagt wird. Wie in der Übersicht oben dargestellt, fügen wir Konstanten hinzu, indem wir das Dreieick nutzen:
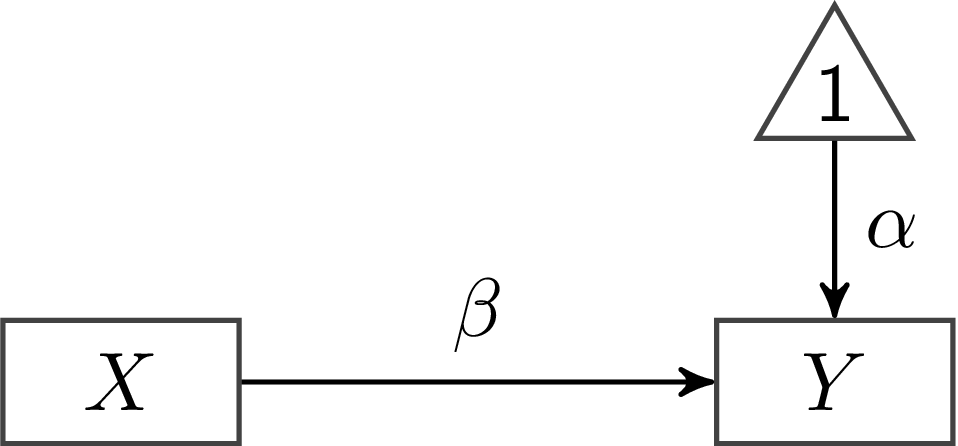
Wir fügen also eine zweite Regression hinzu (der Pfeil), in der $X$ auf 1 regressiert wird. In der Regressionsgleichung sieht das so aus: $Y = \alpha \cdot 1 + \beta \cdot X$. Wir nutzen hier $\alpha$ und nicht $\beta_0$ für das Intercept, weil das die von lavaan verwendete Notation ist. An der Bedeutung ändert sich dadurch aber nichts. Weil $\alpha \cdot 1 = \alpha$ können wir Regressionsgleichung auf $Y = \alpha + \beta \cdot X$ kürzen. Jetzt fehlt noch das Residuum, also die Komponenten in $Y$, die nicht durch $X$ vorhergesagt werden können. Bei diesem Residuum handelt es sich um eine nicht-beobachtbare bzw. latente Variable. Diese Variable entsteht durch unsere Berechnung, sie existiert ohne das Modell nicht im Datensatz. In der Abbildung fügen wir also eine Ellipse hinzu und nutzen diese zur Vorhersage von $Y$:
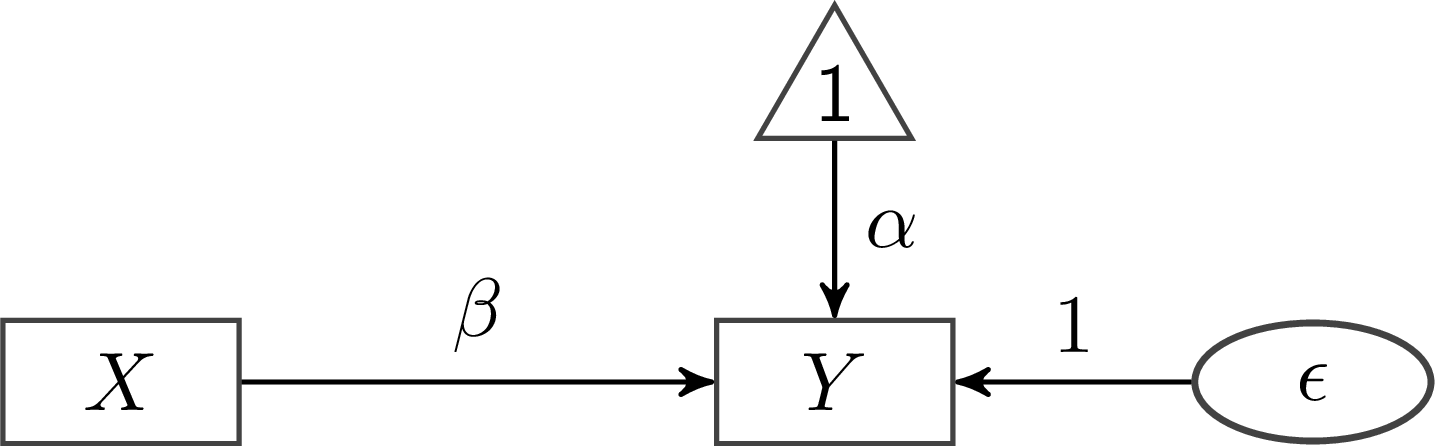
In der Regressionsgleichung ergibt sich dadurch $Y = \alpha + \beta \cdot X + 1 \cdot \epsilon$. Nach dem gleichen Prinzip wie eben kürzt sich das auf die traditionelle Regressionsgleichung: $Y = \alpha + \beta \cdot X + \epsilon$.
Nehmen wir das bisherige Beispiel der Regression, in der wir relationale Aggression zum 1. Zeitpunkt ($RA_1$) durch soziale Intelligenz ($SI_1$) und Empathie ($EM_1$) vorhersagen. In diesem Fall haben wir drei beobachtbare Variablen: die drei Skalenwerte, die wir erzeugt haben. Die Beziehung zwischen $RA_1$ und $SI_1$ ($\beta_1$) bzw. $EM_1$ ($\beta_2$) ist regressiv. Zusätzlich regressieren wir die relationale Aggression auf die Konstante 1, um so eine Schätzung für das Intercept $\alpha$ zu erhalten.
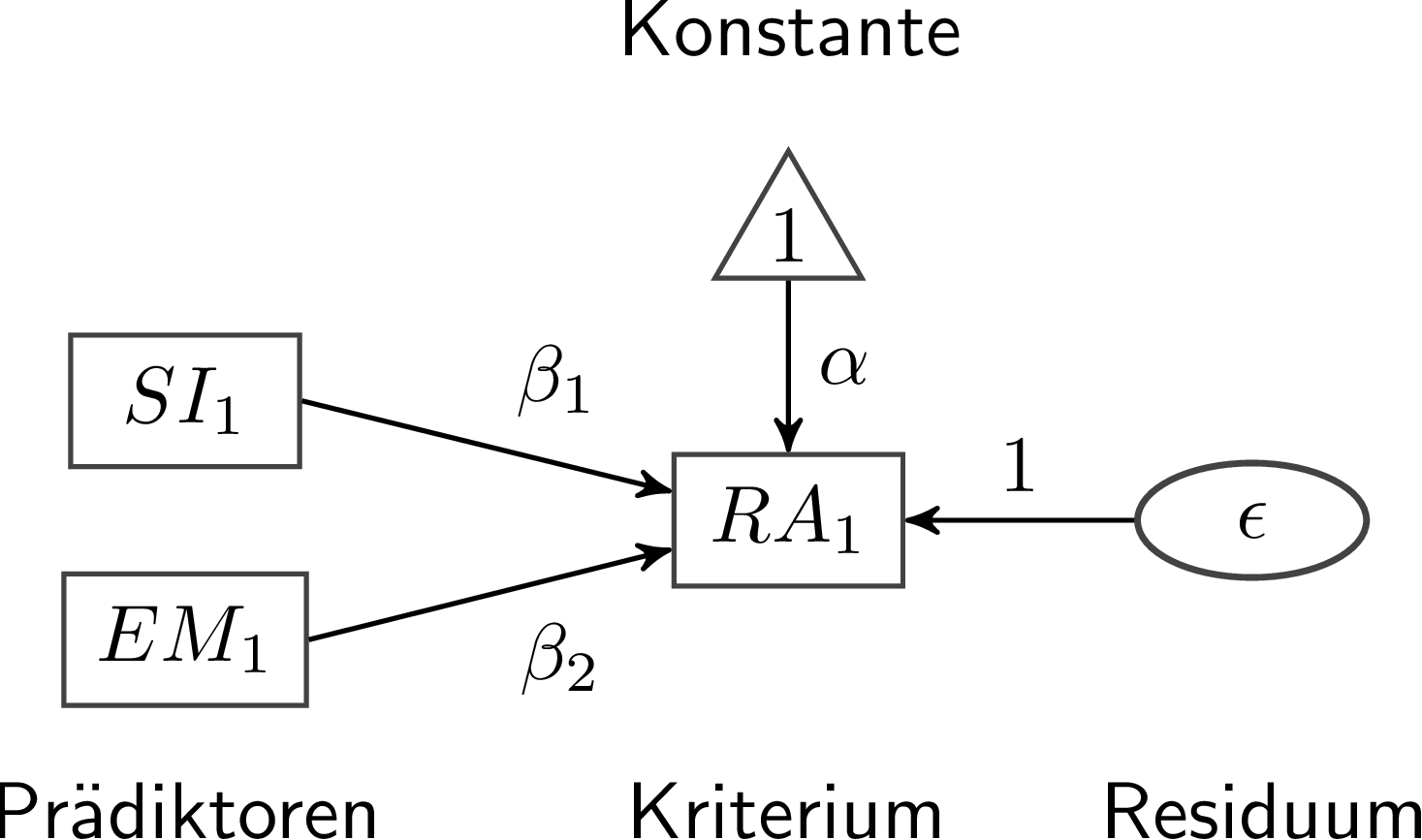
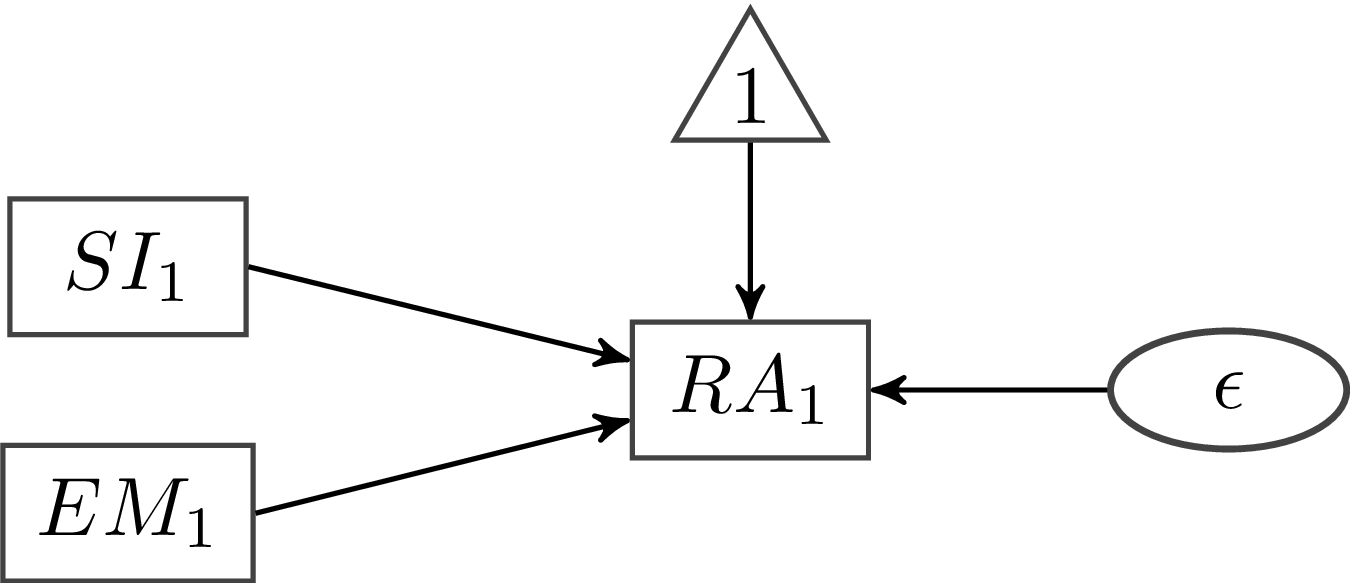
In dieser Abbildung wird die Regression $RA_1 = \alpha + \beta_1 SI_1 + \beta_2EM_1 + \epsilon$ dargestellt. Häufig wird natürlich auf die detaillierte Beschriftung in solchen Abbildungen verzichtet, sodass eine typische Abbildung dieser Regression so aussehen würde:
Modell-Syntax
Wie oben erwähnt, wird in der Modell-Syntax von lavaan das Pfaddiagramm eines Modells beschrieben. In folgender Tabelle sind alle Befehle in lavaan Modell-Syntax zusammengetragen.
| Bezeichnung | Befehl | Bedeutung |
|:-----------:|:------:|:---------:|
| Regression | ~ | wird vorhergesagt durch |
| Kovarianz | ~~ | kovariiert mit |
| Intercept | ~1 | wird auf 1 regressiert |
| Faktorladung | =~ | wird gemessen durch |
| Formative Faktoren | <~ | wird konstruiert durch |
| Schwellenparameter | |t... | Schwelle Nummer ... |
In lavaan, wie in beinahe jeder Statistik-Software, wird bei ~~ nicht die Korrelation, sondern stets die Kovarianz angesprochen. Von diesen sechs Befehlen sind für uns zunächst nur drei relevant: die Regression, die Kovarianz und das Intercept. Wie auch in der R-internen Formelnotation wird die Tilde genutzt, um Regressionen darzustellen.
Legen Sie im Feld unten das Modell für die Regression in einem Objekt mit dem Namen mod an! Vergessen Sie nicht, dass Modelle für lavaan als Text angelegt werden - sie müssen also mit Anführungszeichen beginnen und enden. Rufen Sie zum Abschluss das Objekt auf, um sich wiedergeben zu lassen, was in dem Objekt an Syntax gespeichert ist!
mod <- '...'
mod
# Die Reihenfolge der Variablen und Leerzeichen sind irrelevant
# Sehen Sie sich noch einmal an, wie die Regression für lm() geschrieben wurde
# Vollständige Lösung
mod <- 'rat1 ~ 1 + sit1 + emt1'
res1 <- 'rat1~1+sit1+emt1'
res2 <- 'rat1~1+emt1+sit1'
grade_result(
# fail_if(~ class(try(as.character(.result), silent = TRUE)) == 'try-error', 'Vergessen Sie nicht sich das Modell mit "mod" ausgeben zu lassen.'),
# fail_if(~ !(identical(.result, res1) | identical(.result, res2)), ''),
fail_if(~ (!grepl('~1', gsub(' ', '', .result))), 'Bedenken Sie, dass auch das Intercept Teil der Regression ist'),
pass_if(~ identical(gsub(' ', '', .result), res1)),
pass_if(~ identical(gsub(' ', '', .result), res2)),
correct = 'Sehr gut! Dieses Modell enthält die Regression, wie sie in lavaan definiert wird.',
incorrect = 'Leider falsch.',
glue_correct = '{.correct}',
glue_incorrect = '{.incorrect} {.message}')
Für den lm Befehl reicht es aus, die Regression zu definieren, um das Modell aufzustellen. In lavaan ist das nicht der Fall. Das liegt daran, dass lavaan im Gegensatz zu lm in der Lage ist, mehrere abhängige Variablen und komplexe Beziehungen zwischen diesen gleichzeitig darzustellen. Daher müssen alle Elemente des Pfaddiagramms angesprochen werden, wenn nicht angenommen werden soll, dass die Parameter 0 sind. Aus dem Pfaddiagramm zur multiplen Regression fehlt jetzt im Modell noch die latente Variable $\epsilon$. Da wir sie im Modell noch nicht angesprochen haben, existiert diese für lavaan auch noch nicht. Um dem Residuum eine Existenz zu verschaffen, können wir dessen Varianz anfordern. Weil das Residuum untrennbar mit der abhängigen Variable verbunden ist, erreichen wir das, indem wir die (Residual-)Varianz der relationalen Aggression anfordern:
mod <- 'rat1 ~ 1 + sit1 + emt1
rat1 ~~ rat1'
mod <- 'rat1 ~ 1 + sit1 + emt1
rat1 ~~ rat1'
Wie oben dargestellt, können wir in lavaan die ~~ nutzen, um eine Kovarianz anzufordern. Die Kovarianz einer Variable mit sich selbst ist deren Varianz.
In der Modellsyntax von lavaan können wir Zeilenumbrüche nutzen, um einzelne Modellabschnitte voneinander abzugrenzen. Wir haben z.B. eine Zeile mit der Regression und dann eine weitere mit der Varianz der Residualvarianz. Wir können nach diesem Schema auch die Regression in ihre Einzelteile zerlegen:
mod <- '
# Regression
rat1 ~ 1
rat1 ~ sit1
rat1 ~ emt1
# Residuum
rat1 ~~ rat1'
Wie Sie sehen, können wir in lavaan Modellen auch weiterhin mit # Kommentaren beginnen. Diese aufgeschlüsselte Variante ist mit der kürzeren Schreibweise oben identisch. Welche Sie bevorzugen, ist ganz allein Ihnen überlassen.
Modellschätzung
Den ersten der drei Schritte bei der Modellierung mit lavaan haben wir abgeschlossen. Jetzt wo wir ein Modell haben, müssen wir dieses Modell mit der empirischen Realität (also unseren Daten) konfrontieren. Dafür ist der Kernbefehl des Pakets der lavaan-Befehl. Dieser nimmt eine ganze Reihe an Argumenten entgehen, von denen allerdings nur zwei zwingend erforderlich sind:
model: Das zu schätzende Modelldata: Der Datensatz auf den das Modell angepasst werden soll
Alle anderen Argumente haben - für die meisten Analysen sinnvolle - Voreinstellungen. Weil die Modellschätzung mit lavaan sehr viele Ergebnisse und Details zum Schätzverfahren erzeugt, ist es ratsam das angepasste Modell in einem Objekt abzulegen.
fit <- lavaan(mod, fairplayer)
Sofern keine Warn- oder Fehlermeldungen erzeugt werden, war die Schätzung des Modells erfolgreich. Wie auch bei lm oder anderen Funktionen aus dem letzten Semester, kann der Datensatz, der an lavaan gegeben wird, auch Variablen enthalten, die für das Modell irrelevant sind. Alle manifesten Variablen, auf die im Modell bezug genommen wird, sucht sich lavaan aus dem Datensatz heraus.
Ergebnisinspektion
lavaan bietet eine ganze Reihe von Möglichkeiten, die Ergebnisse von Modellen genauer unter die Lupe zu nehmen. Die naheliegendste ist - wie schon bei lm - der allgemeine summary Befehl:
summary(fit)
lavaan::summary(fit)
Diese Ausgabe enthält neben Modellergebnissen auch einige Informationen zur Schätzprozedur, auf die wir hier erst einmal noch nicht eingehen werden. Die erste Zahl, mit der wir uns näher auseinandersetzen können, ist die Number of free parameters in der 3. Zeile der Ausgabe. Hier wird uns gesagt, dass wir vier Paramter schätzen mussten. Wenn wir uns das Pfaddiagramm für diese Regression noch einmal vor Augen führen, wird schnell deutlich, welche vier das sind:
- Regressionsgewicht $\beta_1$ von $SI_1$
- Regressionsgewicht $\beta_2$ von $EM_1$
- Achsenabschnitt / Intercept $\alpha$
- Varianz der Residuen $\epsilon$
Die nächste für uns relevante Information ist die Number of observations, welche in Used und Total unterteilt wird. Hier wird uns verraten, dass wir zwar r nrow(fairplayer) Personen im Datensatz haben, aber für unsere Analyse aufgrund fehlender Werte nur r inspect(fit, 'nobs') genutzt werden konnten.
Dann springen wir direkt runter zu den Modellergebnissen, die mit der Zeile Regressions: beginnen. Wie diese Überschrift verrät, erhalten wir zuerst Informationen über die Regressionsparameter. Hier der relevante Ausschnitt:
abbrev(fit, 'Regressions', 'Intercepts')
Dieser Abschnitt beginnt mit der Zeile rat1 ~, was uns verdeutlichen soll, dass die folgenden Regressionsergebnisse sich auf eine Regression mit relationaler Aggression als abhängige Variable beziehen. Die anschließende Tabelle enthält die gleichen vier Spalten, die wir schon bei der Wiederholung der Regression gesehen haben: das geschätzte Regressionsgewicht (Estimate), den Standardfehler (Std.Err.), den $z$-Wert (z-value) und den daraus resultierenden $p$-Wert (P(>|z|)). Wie Ihnen mit Sicherheit sofort aufgefallen ist, arbeitet lavaan nicht mit $t$- sondern mit $z$-Werten. Das heißt, dass hier von vornherein eine größere Stichprobe angenommen wird, um korrekte inferenzstatistische Schlüsse ziehen zu können. Wir können diese Ergebnisse direkt noch einmal mit den Ergebnissen aus lm vergleichen:
summary(lm(rat1 ~ sit1 + emt1, fairplayer))$coef
Wie Sie sehen, sind die Parameter zwar identisch, die Inferenzstatistik unterscheidet sich zwischen beiden Herangehensweisen aber. Woher das kommt, werden wir im Verlauf des Semesters noch genauer untersuchen.
Anders als bei lm werden in lavaan die Intercepts von den Regressionsgewichten getrennt ausgegeben:
abbrev(fit, 'Intercept', 'Variances')
Hier wird das Intercept von rat1 ausgegeben. Der . vor dem Variablennamen verrät uns, dass es sich um einen bedingten Mittelwert handelt, die Variable rat1 also irgendwo im Modell eine abhängige Variable ist. Diese Notation hilft besonders bei sehr komplexen Modellen, auch wenn es in unserem Beispiel noch leicht ist, den Überblick zu behalten.
Zu guter Letzt folgt ein Abschnitt mit Varianzen - in unserem Fall nur eine:
abbrev(fit, 'Variances', ellipses = 'top', shift = 1)
Auch hier verrät uns der ., dass rat1 irgendwo im Modell eine abhängige Variable ist, sodass es sich bei dieser Varianz um eine Residualvarianz handelt.
Weil der Output der summary Funktion sehr schnell sehr lang wird und es nicht erlaubt, einzelne Ergebnisse direkt als Objekte weiterzuverwenden, gibt es für lavaan die Funktion inspect. Diese nimmt zwei Argumente entgegen:
object: Das Ergebnisobjekt (bei uns also fit)what: Was inspiziert werden soll
Die Liste mögicher whats ist mehrere Seiten lang. Sie finden Sie bei ?inspect. Eine Sache, die uns schon bei der lm Regression interessiert hat, war das $R^2$. Hierfür können wir inspect nutzen:
inspect(fit, 'rsquare')
Dieser Befehl wird im Verlauf des Semesters noch sehr praktisch, weil wir uns so nicht immer durch den gesamten Output wühlen müssen, sondern uns stets auf das beschränken können, was gerade relevant ist. Sie können im folgenden Feld auch ein paar andere Aspekte der Ergebnisse inspizieren. Probieren Sie gerne aus der Liste möglicher Angaben aus, was Ihnen in den Sinn kommt!
# Anzahl der Beobachtungen
inspect(fit, 'nobs')
# Anzahl der Parameter
inspect(fit, 'npar')
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')],
na.rm = TRUE)
fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')],
na.rm = TRUE)
fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')],
na.rm = TRUE)
mod <- 'rat1 ~ 1 + sit1 + emt1
rat1 ~~ rat1'
fit <- lavaan(mod, fairplayer)
Übungsaufgaben
Die Übungsaufgaben finden Sie als Quiz im OLAT Kurs. Für die Bearbeitung der Aufgaben benötigen Sie den fairplayer Datensatz. Um diesen zu laden, nutzen Sie bitte
data(fairplayer, package = 'PsyMSc1')
Vergessen Sie außerdem nicht, mit
library(lavaan)
lavaan zu laden, bevor Sie loslegen!
Falls Sie die Quiz-Aufgaben lieber im Browser bearbeiten möchten oder diese Sitzung über Shinyapps.io beziehen, können Sie das untenstehende R-Fenster benutzen, um den Code für die Übungen zu schreiben und auszuführen.
Literatur
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden (5. Auflage, 1. Auflage: 2010). Weinheim: Beltz.
Rosseel, Y. (2012). lavaan: [An R Package for Structural Equation Modeling]. Journal of Statistical Software, 48(2), 1 - 36. doi:http://dx.doi.org/10.18637/jss.v048.i02
Schultze, M. (2019). R Crash-Kurs. Retrieved from https://pandar.netlify.com/post/r-crash-kurs/.
- Blau hinterlegte Autorenangaben führen Sie direkt zur universitätsinternen Ressource.
martscht/PsyMSc1 documentation built on July 11, 2020, 3:45 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
library(learnr) library(gradethis) library(shiny) library(fontawesome) library(lavaan) data(fairplayer, package = 'PsyMSc1') knitr::opts_chunk$set(exercise.checker = gradethis::grade_learnr)
abbrev <- function(X, begin = 'Latent Variables', end = NULL, ellipses = 'both', shift = 2, ...) { tmp <- capture.output(lavaan::summary(X,...)) if (is.null(begin)) begin <- 1 else begin <- grep(begin, tmp, fixed = TRUE)[1] if (is.null(end)) end <- length(tmp)-shift else end <- grep(end, tmp, fixed = TRUE)[grep(end, tmp, fixed = TRUE) > begin][1]-shift if (ellipses == 'both') { cat('[...]\n', paste(tmp[begin:end], collapse = '\n'), '\n[...]\n') } if (ellipses == 'top') { cat('[...]\n', paste(tmp[begin:end], collapse = '\n')) } if (ellipses == 'bottom') { cat(paste(tmp[begin:end], collapse = '\n'), '\n[...]\n') } if (ellipses == 'none') { cat(paste(tmp[begin:end], collapse = '\n')) } }
Einleitung
Im Verlauf dieses Seminars soll neben der Einführung in die Theorie und Hintergründe multivariater Verfahren auch eine Einführung in deren Umsetzung gegeben werden, sodass Sie in der Lage sind, diese Verfahren in Ihrem zukünftigen akademischen und beruflichen Werdegang zu benutzen. Diese Umsetzung möchten wir Ihnen mit lavaan zeigen - dem meistverbreiteten Paket für multivariate Verfahren wie z.B. konfirmatorische Faktorenanalyse (CFA), Pfadanalyse oder Strukturgleichungsmodellierung (SEM) in R. Allein im März 2020 wurde lavaan über 30 000 mal heruntergeladen; es wird in allen Bereichen der psychologischen Forschung genutzt und wurde in über 6 500 sozialwissenschaftflichen Veröffentlichungen zitiert.
Dieses Tutorial bietet eine Einführung in lavaan. Im Zentrum stehen dabei die Grundgedanken und die typische Weise, in der man in lavaan bei Analysen vorgeht. Um diese Ideen und Vorgehensweisen zu erkunden, betrachten wir ein Beispiel aus dem letzten Semester mal aus dieser neuen Perspektive.
Wir beginnen das Tutorial aber zunächst mit einer Auffrischung Ihrer R-Fähigkeiten. Auch wenn Sie im Umgang mit R sehr geübt sind, nehmen Sie sich bitte trotzdem ein paar Minuten, um sich noch einmal intensiv mit den Befehlen auseinanderzusetzen, die für dieses Semester von zentraler Bedeutung sind. Sollten Sie wenig Übung im Umgang mit R haben, oder wenn Sie einfach noch einmal eine etwas detaillierte Einführung in R lesen möchten, finden Sie auf Pandar die R-Einführung aus dem Bachelorstudiengang.
Für die Durchführung dieses Tutorials benötigen Sie nichts weiter als dieses Browserfenster. Bitte veärndern Sie während Sie die Übung in diesem Browserfenster machen nichts in der R-Sitzung, mit der Sie diese Übung gestartet haben.
Nach dem Ende der Übung finden Sie im OLAT Kurs ein kurzes Quiz mit Bezug zu den Inhalten dieser Sitzung.
Den gesamten R-Code, der in dieser Sitzung genutzt wird, können Sie r fontawesome::fa("download") hier herunterladen.
R Grundlagen Wiederbelebung {#Wiederbelebung}
In diesem Abschnitt gucken wir uns zur Wiederholung noch einmal ein paar Grundzüge des Datenmanagements in R an, bevor wir eine multiple Regression durchführen und deren Ergebnisse genauer inspizieren.
Beispieldatensatz
Der Datensatz, den wir in dieser Sitzung benutzen, stammt aus einer Studie von Bull, Schultze & Scheithauer (2009), in der die Effektivität eines Interventionsprogramms zur Bullyingprävention bei Jugendlichen untersucht wurde. Der Datensatz liegt bereits im R-eigenen .rda-Format vor, sodass uns ein Import der Daten erspart bleibt. Stattdessen können wir einfach mit load arbeiten, um die Daten zu laden:
load('fairplayer.rda')
Hinweis: Wenn Sie mit diesen Daten in einem eigenen R-Skript Dinge ausprobieren möchten, können Sie die Daten mit data(fairplayer, package = 'PsyMSc1') laden.
Verschaffen Sie sich im folgenden Fenster einen Überblick über die Daten. Wie viele und was für Variablen enthält der Datensatz? Von wie vielen Personen liegen Daten vor? Einige Befehle sind schon beispielhaft vorgegeben - Sie können aber auch andere Befehle ergänzen, um mehr Details zu erfahren!
# Namen der Variablen abfragen names(fairplayer) # Anzahl der Zeilen und Spalten nrow(fairplayer) ncol(fairplayer) # Struktur des Datensatz - Informationen zur Variablentypen str(fairplayer) # Datensatz ansehen fairplayer
Der Datensatz, den wir hier betrachten, enthält verhaltensbezogene Selbstberichte auf jeweils drei Items zur relationalen Aggression (ra), Empathie (em) und sozialen Intelligenz (si). Diese insgesamt 9 Indikatoren liegen zu drei Messzeitpunkten (t1, t2 und t3) vor. Die über str angeforderte Struktur verrät uns außerdem, dass diese Variablen allesamt integer (int), also ganzzahlig, sind. Über die Items hinaus sind vier weitere Variablen im Datensatz enthalten, die den Personenidentifikator (id), die Klasse (class), die Interventionsgruppe (grp) und das Geschlecht (sex) der Jugendlichen kodieren.
Datenmanagement
Eines der großen Themen in diesem Semester wird es sein, möglichst gute und zuverlässige Schätzungen für die Werte einzelner Personen auf verschiedenen psychologischen Konstrukten zu erhalten. Traditionellerweise werden dafür häufig sogenannte Skalenwerte genutzt. Diese werden meistens als Mittelwerte der Items, die ein gemeinsames Konstrukt erheben sollen, berechnet.
Für die weiteren Analysen in dieser Sitzung werden wir die Skalenwerte der relationalen Aggression, Empathie und sozialen Intelligenz zum ersten Zeitpunkt benötigen. Naheliegend wäre es, diese durch einfache Arithmetik zu bestimmen, z.B. für die relationale Aggression:
fairplayer$rat1 <- (fairplayer$ra1t1 + fairplayer$ra2t1 + fairplayer$ra3t1) / 3
Von diesem Vorgehen möchten wir an dieser Stelle explizit abraten. Grund dafür ist, dass es hier nicht möglich ist, den Umgang mit fehlenden Werte zu beeinflussen. Darüber hinaus wird diese Strategie mit zunehmender Anzahl von Items pro Skala sehr schreibaufwändig. Daher sollten wir dieses Vorgehen nicht nur aus Faulheit umgehen, sondern auch, weil mehr Syntax auch immer mehr mögliche Fehlerquellen bedeutet. Stattdessen empfehlen wir, mit dem rowMeans Befehel zu arbeiten. Z.B. für die relationale Aggression:
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE)
Das Argument na.rm = TRUE bewirkt, dass wir den Skalenwert auch dann berechnen, wenn fehlende Werte auf einzelnen Items vorliegen. Erstellen Sie die Skalenwerte für die Empathie emt1 und die soziale Intelligenz sit1 im folgenden Fenster! Mit dem "Hint" Button erhalten Sie Hinweise, durch die Sie durchblättern können. Der letzte "Hint" ist dann die vollständige Lösung. Keine Sorge falls Sie hier Fehler machen: die Skalenwerte stehen Ihnen in den folgenden Übungen trotzdem zur Verfügung.
# Weisen Sie die Variablen mit $ dem Datensatz zu! # fairplayer$sit1 oder fairplayer$emt1
# Nutzen Sie die rowMeans-Funktion ?rowMeans
# Die Namen der Items: names(fairplayer)
# Vollständige Lösung fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE)
Deskriptivstatistik
Die drei Skalenwerte aus dem letzten Abschnitt sollten wir uns - zusammen mit ein paar anderen Variablen - mal genauer angucken, um ein Gefühl dafür zu entwickeln, wie die Lage in dieser Erhebung ist. Der Klassiker, um sich einen Überblick zu verschaffen, ist die R-eigene summary Funktion. Bei dieser handelt es sich um eine generische Funktion, die man auf viele verschiedene Objekte in R anwenden kann. Die Aufbereitung des Ergebnisses hängt dabei immer davon ab, auf was für ein Objekt man sie angewendet hat.
Nehmen wir unsere drei Skalenwerte: bei allen handelt es sich um numerische Variablen (in R: num) - in R wird also davon ausgegangen, dass es Variablen mit mindestens Intervallskalenniveau sind (mehr Informationen zu Skalenniveaus in der psychologischen Methodenlehre finden Sie in Eid, Gollwitzer und Schmitt (2017) im Kapitel 5). Für solche Variablen wird in R mit summary eine sogenannte Fünf-Punkt-Zusammenfassung ausgegeben:
summary(fairplayer$rat1)
Den Spitzfindigen unter Ihnen fällt auf, dass hier mehr als fünf Informationen ausgegeben werden. Die klassische Fünf-Punkt-Zusammenfassung besteht aus Minimum, Maximum und den drei Quartilen. In R wird zusätzlich noch das arithmetische Mittel und die Anzahl der fehlenden Werte ausgegeben.
Für nominalskalierte Variablen, wie z.B. die Gruppenzugehörigkeit grp, sieht die Zusammenfassung ein wenig anders aus:
summary(fairplayer$grp)
Weil diese Variable in R als factor angelegt ist, wird sie als nominalskaliert behandelt und es werden keine Statistiken berechnet, die für solche Variablen nicht aussagekräftig sind. Stattdessen wird lediglich eine Häufigkeitstabelle erzeugt.
Deskriptivstatistiken können aber auch einzeln erzeugt werden - z.B. mit mean für Mittelwerte. Versuchen Sie im untenstehenden Feld für den Skalenwert der relationalen Aggression die Standardabweichung mit sd zu bestimmen!
Mit dem Button "Run Code" können Sie das R-Skript ausführen, um Dinge auszuprobieren. Wenn Sie auf "Submit Answer" klicken, wird geprüft, ob ihr Skript richtig war. Hier wird keine Bewertung vorgenommen und Sie können so viele Antworten abschicken, wie Sie wollen. Dieser Schritt ist ausschließlich dazu gedacht, dass Sie selbst überprüfen können, ob Ihr Vorgehen richtig ist.
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) res <- sd(fairplayer$rat1, na.rm = TRUE) grade_result( fail_if(~ is.na(.result), 'Wegen fehlender Werte kann die Standardabweichung nicht bestimmt werden. Finden Sie das geeignete Argument, dass die fehlenden Werte für die Berechnung ausschließt.'), fail_if(~ (!is.na(.result) & !identical(.result, res)), 'Haben Sie die korrekte Variable angesprochen?'), pass_if(~ identical(.result, res)), correct = 'Sehr gut! Der Umgang mit fehlenden Werten muss in vielen R-Funktionen explizit angesprochen werden.', incorrect = 'Leider falsch.', glue_correct = '{.correct}', glue_incorrect = '{.incorrect} {.message}')
Kovarianzen und Korrelationen
Neben univariaten Statistiken sind für eine Veranstaltung mit dem Titel "Multivariate Verfahren" natürlich Zusammenhangsmaße von zentraler Bedeutung. Die beiden gängigsten Formen um Zusammenhänge in der Psychologie zu untersuchen, sind Kovarianzen und Korrelationen. Bivariat können wir diese in R sehr einfach über cov bzw. cor anfordern:
cov(fairplayer$rat1, fairplayer$sit1, use = 'complete') cor(fairplayer$rat1, fairplayer$sit1, use = 'complete')
Mit dem Argument use wird der Umgang mit fehlenden Werten gesteuert - in diesem Fall sollen alle listenweise vollständigen Beobachtungen genutzt werden, also alle Fälle, in denen keine der beteiligten Variablen fehlt. Das ist im Moment noch kein Unterschied zum paarweisen Fallausschluss, weil wir immer nur zwei Variablen betrachten. Unten werden wir aber Korrelationen und Kovarianzen für mehrere Variablen gleichzeitig bestimmen. Eine kurze Wiederholung aus Statistik I im Bachelorstudiengang: die Produkt-Moment-Korrelation ergibt sich aus $\frac{cov(x, y)}{sd(x)sd(y)}$.
Um Zusammenhänge nicht immer nur für zwei Variablen bestimmen zu können, ist es auch möglich, die Funktionen cov und cor auf ganze Matrizen und Datensätze anzuwenden. Nehmen wir unsere drei Skalen in einen gemeinsamen Datensatz auf:
scales <- fairplayer[, c('rat1', 'emt1', 'sit1')]
Jetzt können wir die Korrelationsmatrix für die drei Variablen gleichzeitig bestimmen:
cor(scales, use = 'complete')
Das Gleiche funktioniert natürlich auch mit der Kovarianzmatrix:
cov(scales, use = 'complete')
Letztere ist für viele Analysen, die wir in diesem Semester behandeln werden zentral, weil sie in einer Matrix (beinahe) alle relevanten Informationen über interindividuelle Unterschiede (Varianzen) und deren Zusammenhänge (Kovarianzen) enthält. Die Verwendung von use = 'complete' bewirkt hier, dass nur Personen in die Berechnung aufgenommen werden, die auf keiner der drei Variablen fehlende Werte haben. In unserem Fall bleiben also von den ursprünglich r nrow(fairplayer) Personen noch r nrow(na.omit(scales)) übrig.
Varianzen sind in der Diagonale der Matrix enthalten:
diag(cov(scales, use = 'complete'))
Einen Überblick über die Befehle für Matrix-Algebra in R finden Sie auf der Quick-R Website.
Wiederholung: Regression {#Regression}
Im letzten Semester haben Sie die lm Funktion kennengelernt, um lineare Modelle in R zu berechnen. Um diese Funktion zu verwenden, müssen meist zwei Argumente an lm weitergegeben werden:
formula: Das Modell in klassischer R-Formelschreibweisedata: Der Datensatz, auf den dieses Modell angewendet werden soll
Die Formelschreibweise folgt in R einer einfachen Grundstruktur: Y ~ X. Gelesen werden kann $Y$ "vorhergesagt durch" $X$. Mehrere unabhängige Variablen, z.B. $X_1$ und $X_2$ können im Wesentlichen durch drei Operatoren verbunden sein:
X1 + X2: Für additive Modelle (nur Haupteffekte von $X_1$ und $X_2$)X1 : X2: Für Interaktionen (nur der Interaktionseffekt $X_1 \cdot X_2$)X1 * X2: Als Kurzschreibweise fürX1 + X2 + X1:X2
Darüber hinaus können noch einige andere Operatoren genutzt werden (mehr Informationen finden Sie mit ?formula) - z.B. kann mit - ein Effekt bewusst unterdrückt werden. Eine "Variable", die in Regressionen häufig als Prädiktor aufgenommen wird, ist die Konstante 1. Wenn man eine abhängige Variable auf eine Konstante regressiert, ist das entsprechende Regressionsgewicht der (bedingte) Mittelwert - in Regressionsanalysen häufig als Achsenabschnitt oder Intercept bezeichnet. Für eine Wiederholung der Grundgedanken der Regressionsanalyse können Sie einen Blick in Eid et al. (2017) Kapitel 17 und 19) werfen.
Modell erstellen
Im Beispiel geht es um die drei Konstrukte relationale Aggression, soziale Intelligenz und Empathie von Jugendlichen. Da durch Interventionen soziale Intelligenz als Kompetenz gut vermittelbar ist, ist von Interesse, wie sich höhere soziale Intelligenz auf relationale Aggression auswirkt. Wichtig ist dabei, dass auch Empathie in die Gleichung einbezogen wird, weil diese konsistent ein negativer Prädiktor relationaler Aggression ist; wenn ich negative Empfindungen anderer mitfühlen kann, ist es weniger wahrscheinlich, dass ich durch mein Verhalten solche negativen Empfindungen hervorrufen möchte. Die Beziehung zu sozialer Intelligenz war in der Literatur lange aber nicht so eindeutig - erst in den späten 2000er Jahren wurde die Befundlage hierzu eindeutig (aus dieser Zeit stammt der Datensatz).
Um diese Fragestellung zu bearbeiten, können wir mit dem Datensatz eine multiple Regression zur Vorhersage relationaler Aggression durch Empathie und soziale Intelligenz durchführen. Erstellen Sie im folgenden Kasten ein Modell mit dem einfallsreichen Namen mod, in dem die Ergebnisse der additiven Regression $RA_1 = \alpha + \beta_1EM_1 + \beta_2SI_1 + \epsilon$ abgelegt sind!
# Vollständige Lösung mod <- lm(rat1 ~ 1 + sit1 + emt1, fairplayer)
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE) mod <- lm(rat1 ~ sit1 + emt1, fairplayer)
mod <- lm(rat1 ~ sit1 + emt1, fairplayer)
Regressionergebnisse {#Regressionergebnisse}
Es gibt jetzt eine Vielzahl von Möglichkeiten, um die Ergebnisse des Modells zu inspizieren. Mit dem einfachen Aufruf des Modells erhalten wir zunächst nur die Regressiongewichte:
mod
Wir können uns die Koeffizienten mit coef auch als Vektor ausgeben lassen, was den Vorteil hat, dass wir sie in anderen Funktionen weiterverwenden können. Zum Beispiel in einem Scatterplot:
plot(fairplayer$rat1 ~ fairplayer$sit1) abline(coef(mod)[1], coef(mod)[2])
Üblicherweise wird aber auch bei lm-Objekten der summary-Befehl genutzt, um die Ergebnisse genauer zu inspizieren. Nutzen Sie diesen Befehl, um sich einen Überblick zu verschaffen. Welche Regressionsgewichte sind bedeutsam von 0 verschieden? Wie groß ist der Determinationskoeffizient $R^2$?
summary(mod)
Der Abschnitt Coefficients enthält die relevanten Aussagen zu den Regressionsgewichten. Um uns nur diesen anzusehen, können wir das $ benutzen, um, wie bei allen R-Objekten, nur einen spezifischen Abschnitt zu betrachten.
summary(mod)$coef
Die Zeilennamen dieser Tabelle (r paste(rownames(summary(mod)$coef))) geben an, zu welchem Prädiktor das Regressiongewicht gehört. In der Spalte Estimate wird das Regressionsgewicht angegeben. Hier wird also für zwei Jugendliche, die sich um eine Einheit in sozialer Intelligenz (sit1) unterscheiden, aber das gleiche Ausmaß an Empathie (emt1) haben, ein Unterschied in der relationalen Aggression von r formatC(coef(mod)[2], format = 'f', digits = 2) Einheiten vorhergesagt. Bei gleicher Empathie führt höhere soziale Intelligenz also zu mehr relationaler Aggression. Die nächste Spalte Std. Error gibt den Standardfehler an, welcher das Ausmaß an Unsicherheit quantifiziert, das wir in der Schätzung des Populationswertes dieses Regressionsgewichts aufgrund unserer Stichprobe haben. Das Verhältnis aus Regressionsgewicht und Standardfehler ($\frac{r formatC(coef(mod)[2], format = 'f', digits = 2)}{r formatC(summary(mod)$coef[2,2], format = 'f', digits = 2)} = r formatC(summary(mod)$coef[2,3], format = 'f', digits = 2)$) folgt - wenn die Voraussetzungen der Regressionsanalyse halten - einer $t$-Verteilung mit $n - k - 1$ Freiheitsgraden und wird deswegen in der Tabelle als t Value geführt. Bei der Bestimmung der Freiheitsgrade entspricht $n$ der Anzahl der Beobachtungen und $k$ der Anzahl der Prädiktoren. Bei ausreichend großer Anzahl von Freiheitsgraden ist die $t$-Verteilung nicht mehr von der Standardnormalverteilung unterscheidbar, sodass in anderer Software hier häufig der $z$-Test genutzt wird.
Weil wir wissen, wie wahrscheinlich es ist, unter der $t$-Verteilung mit r summary(mod)$df[2] Freiheitsgraden einen Wert von r formatC(summary(mod)$coef[2,3], format = 'f', digits = 2) zu beobachten, können wir (in der letzten Spalte) einen $p$-Wert bestimmen. In diesem Fall heißt es also, dass, wenn in der Population der wahre Wert dieses Regressionsgewichts 0 wäre, die Wahrscheinlichkeit in unserer Stichprobe ein Regressionsgewicht von r formatC(coef(mod)[2], format = 'f', digits = 2) oder extremer zu finden r formatC(summary(mod)$coef[2,4], format = 'f', digits = 5) ist. "Extremer" heißt hierbei, dass das Regressionsgewicht vom Betrag her größer sein müsste.
Versuchen Sie nach dem gleichen Prinzip, nach dem wir oben die Koeffiziententabelle aus der summary extrahiert haben, den Determinationskoeffizienten zu extrahieren, um eine Aussage über die inhaltliche Relevanz dieses Regressionsmodells zu gewinnen!
Mit dem Button "Run Code" können Sie das R-Skript ausführen um Dinge auszuprobieren. Wenn Sie auf "Submit Answer" klicken, wird geprüft, ob ihr Skript richtig war. Hier wird keine Bewertung vorgenommen und Sie können so viele Antworten abschicken, wie Sie wollen. Dieser Schritt ist ausschließlich dazu gedacht, dass Sie selbst überprüfen können, ob Ihr Vorgehen richtig ist.
# Im Englischen wird der Determinationskoeffizient häufig als "R Squared" bezeichnet
# Namen aller Elemente in der summary: names(summary(mod))
# Vollständige Lösung summary(mod)$r.squared
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE) mod <- lm(rat1 ~ sit1 + emt1, fairplayer) res1 <- summary(mod)$r.squared res2 <- summary(mod)$adj.r.squared grade_result( pass_if(~ identical(.result, res1)), pass_if(~ identical(.result, res2)), correct = 'Sehr gut! Diese Form der Extraktion bestimmter Elemente werden wir im Verlauf des Semester öfter verwenden.', incorrect = 'Leider falsch. Schauen Sie sich das Vorgehen bei der Koeffiziententabelle noch einmal genauer an.', glue_correct = '{.correct}', glue_incorrect = '{.incorrect}')
lavaan
Alle Dinge, die wir in den bisherigen Abschnitten besprochen haben, sind eine Wiederholung von Konzepten aus dem Bachelorstudium oder der vergangenen Semester gewesen. In diesem Semester werden wir hauptsächlich mit dem R Paket lavaan arbeiten. Der Name ist dabei ein Akronym für latent variable analysis. Im Rest dieser Sitzung werden wir uns die Kerngedanken des Pakets und das grundsätzliche Vorgehen zur Modellschätzung am Beispiel der multiplen Regression ansehen. Mehr Informationen zu lavaan finden Sie unter lavaan.org.
Drei-Schritt Verfahren {#Schritte}
Der Grundlegende Prozess der Modellierung folgt in lavaan drei Schritten. Folgende Abbildung soll das etwas verdeutlichen:
Im 1. Schritt schreiben wir ein Modell als Text und legen es in einem Objekt (z.B. mod) ab. Dieses Modell geben wir dann im 2. Schritt an die Kernfunktionen von lavaan weiter und halten die Ergebnisse wieder in einem Objekt (z.B. fit) fest. Der Name fit verdeutlicht dabei, dass das Model auf die Daten angepasst wurde, die Ergebnisse also eine durch Empirie aktualisierte Fassung unseres ursprünglich rein theoretischen Modells sind. Die Ergebnisse, die in diesem Objekt enthalten sind, können wir im 3. Schritt mit einer Vielzahl von "Helferfunktionen", wie dem allgemeinen summary, genauer untersuchen.
Pfaddiagramme
Die Model-Syntax von lavaan ist eine grafische Sprache. Das heißt, dass die Syntax so gedacht ist, dass man dabei das Pfaddiagramm in Worten beschreibt. Im Verlauf des Semesters werden wir noch diverse Modelle mit Pfaddiagrammen darstellen und dabei immer mal wieder neue Komponenten kennenlernen. Im Wesentlichen bilden Pfaddiagramme aber die beiden möglichen Beziehungen zwischen drei Typen von "Variablen" ab.
Mit diesen fünf sehr grundlegenden Elementen lassen sich erstaunlich viele Modelle darstellen, die in der psychologischen Forschung genutzt werden. Wir können z.B. eine einfache Regression zur Vorhersagen eines Kriteriums $Y$ durch einen Prädiktor $X$ aufstellen. Wir haben also zwei manifeste Variablen (in Rechtecken) und eine gerichtete Verbindung zwischen den beiden (die Regression). Wie üblich, benennen wir die Regression mit $\beta$:
Was diese Abbildung also darstellt ist $Y = \beta \cdot X$. Für eine vollständige Regressionsgleichung fehlen allerdings noch ein paar Dinge. Als erstes nehmen wir das Intercept hinzu - also der Wert, der für $Y$ bei $X = 0$ vorhergesagt wird. Wie in der Übersicht oben dargestellt, fügen wir Konstanten hinzu, indem wir das Dreieick nutzen:
Wir fügen also eine zweite Regression hinzu (der Pfeil), in der $X$ auf 1 regressiert wird. In der Regressionsgleichung sieht das so aus: $Y = \alpha \cdot 1 + \beta \cdot X$. Wir nutzen hier $\alpha$ und nicht $\beta_0$ für das Intercept, weil das die von lavaan verwendete Notation ist. An der Bedeutung ändert sich dadurch aber nichts. Weil $\alpha \cdot 1 = \alpha$ können wir Regressionsgleichung auf $Y = \alpha + \beta \cdot X$ kürzen. Jetzt fehlt noch das Residuum, also die Komponenten in $Y$, die nicht durch $X$ vorhergesagt werden können. Bei diesem Residuum handelt es sich um eine nicht-beobachtbare bzw. latente Variable. Diese Variable entsteht durch unsere Berechnung, sie existiert ohne das Modell nicht im Datensatz. In der Abbildung fügen wir also eine Ellipse hinzu und nutzen diese zur Vorhersage von $Y$:
In der Regressionsgleichung ergibt sich dadurch $Y = \alpha + \beta \cdot X + 1 \cdot \epsilon$. Nach dem gleichen Prinzip wie eben kürzt sich das auf die traditionelle Regressionsgleichung: $Y = \alpha + \beta \cdot X + \epsilon$.
Nehmen wir das bisherige Beispiel der Regression, in der wir relationale Aggression zum 1. Zeitpunkt ($RA_1$) durch soziale Intelligenz ($SI_1$) und Empathie ($EM_1$) vorhersagen. In diesem Fall haben wir drei beobachtbare Variablen: die drei Skalenwerte, die wir erzeugt haben. Die Beziehung zwischen $RA_1$ und $SI_1$ ($\beta_1$) bzw. $EM_1$ ($\beta_2$) ist regressiv. Zusätzlich regressieren wir die relationale Aggression auf die Konstante 1, um so eine Schätzung für das Intercept $\alpha$ zu erhalten.
In dieser Abbildung wird die Regression $RA_1 = \alpha + \beta_1 SI_1 + \beta_2EM_1 + \epsilon$ dargestellt. Häufig wird natürlich auf die detaillierte Beschriftung in solchen Abbildungen verzichtet, sodass eine typische Abbildung dieser Regression so aussehen würde:
Modell-Syntax
Wie oben erwähnt, wird in der Modell-Syntax von lavaan das Pfaddiagramm eines Modells beschrieben. In folgender Tabelle sind alle Befehle in lavaan Modell-Syntax zusammengetragen.
| Bezeichnung | Befehl | Bedeutung |
|:-----------:|:------:|:---------:|
| Regression | ~ | wird vorhergesagt durch |
| Kovarianz | ~~ | kovariiert mit |
| Intercept | ~1 | wird auf 1 regressiert |
| Faktorladung | =~ | wird gemessen durch |
| Formative Faktoren | <~ | wird konstruiert durch |
| Schwellenparameter | |t... | Schwelle Nummer ... |
In lavaan, wie in beinahe jeder Statistik-Software, wird bei ~~ nicht die Korrelation, sondern stets die Kovarianz angesprochen. Von diesen sechs Befehlen sind für uns zunächst nur drei relevant: die Regression, die Kovarianz und das Intercept. Wie auch in der R-internen Formelnotation wird die Tilde genutzt, um Regressionen darzustellen.
Legen Sie im Feld unten das Modell für die Regression in einem Objekt mit dem Namen mod an! Vergessen Sie nicht, dass Modelle für lavaan als Text angelegt werden - sie müssen also mit Anführungszeichen beginnen und enden. Rufen Sie zum Abschluss das Objekt auf, um sich wiedergeben zu lassen, was in dem Objekt an Syntax gespeichert ist!
mod <- '...' mod
# Die Reihenfolge der Variablen und Leerzeichen sind irrelevant
# Sehen Sie sich noch einmal an, wie die Regression für lm() geschrieben wurde
# Vollständige Lösung mod <- 'rat1 ~ 1 + sit1 + emt1'
res1 <- 'rat1~1+sit1+emt1' res2 <- 'rat1~1+emt1+sit1' grade_result( # fail_if(~ class(try(as.character(.result), silent = TRUE)) == 'try-error', 'Vergessen Sie nicht sich das Modell mit "mod" ausgeben zu lassen.'), # fail_if(~ !(identical(.result, res1) | identical(.result, res2)), ''), fail_if(~ (!grepl('~1', gsub(' ', '', .result))), 'Bedenken Sie, dass auch das Intercept Teil der Regression ist'), pass_if(~ identical(gsub(' ', '', .result), res1)), pass_if(~ identical(gsub(' ', '', .result), res2)), correct = 'Sehr gut! Dieses Modell enthält die Regression, wie sie in lavaan definiert wird.', incorrect = 'Leider falsch.', glue_correct = '{.correct}', glue_incorrect = '{.incorrect} {.message}')
Für den lm Befehl reicht es aus, die Regression zu definieren, um das Modell aufzustellen. In lavaan ist das nicht der Fall. Das liegt daran, dass lavaan im Gegensatz zu lm in der Lage ist, mehrere abhängige Variablen und komplexe Beziehungen zwischen diesen gleichzeitig darzustellen. Daher müssen alle Elemente des Pfaddiagramms angesprochen werden, wenn nicht angenommen werden soll, dass die Parameter 0 sind. Aus dem Pfaddiagramm zur multiplen Regression fehlt jetzt im Modell noch die latente Variable $\epsilon$. Da wir sie im Modell noch nicht angesprochen haben, existiert diese für lavaan auch noch nicht. Um dem Residuum eine Existenz zu verschaffen, können wir dessen Varianz anfordern. Weil das Residuum untrennbar mit der abhängigen Variable verbunden ist, erreichen wir das, indem wir die (Residual-)Varianz der relationalen Aggression anfordern:
mod <- 'rat1 ~ 1 + sit1 + emt1 rat1 ~~ rat1'
mod <- 'rat1 ~ 1 + sit1 + emt1 rat1 ~~ rat1'
Wie oben dargestellt, können wir in lavaan die ~~ nutzen, um eine Kovarianz anzufordern. Die Kovarianz einer Variable mit sich selbst ist deren Varianz.
In der Modellsyntax von lavaan können wir Zeilenumbrüche nutzen, um einzelne Modellabschnitte voneinander abzugrenzen. Wir haben z.B. eine Zeile mit der Regression und dann eine weitere mit der Varianz der Residualvarianz. Wir können nach diesem Schema auch die Regression in ihre Einzelteile zerlegen:
mod <- ' # Regression rat1 ~ 1 rat1 ~ sit1 rat1 ~ emt1 # Residuum rat1 ~~ rat1'
Wie Sie sehen, können wir in lavaan Modellen auch weiterhin mit # Kommentaren beginnen. Diese aufgeschlüsselte Variante ist mit der kürzeren Schreibweise oben identisch. Welche Sie bevorzugen, ist ganz allein Ihnen überlassen.
Modellschätzung
Den ersten der drei Schritte bei der Modellierung mit lavaan haben wir abgeschlossen. Jetzt wo wir ein Modell haben, müssen wir dieses Modell mit der empirischen Realität (also unseren Daten) konfrontieren. Dafür ist der Kernbefehl des Pakets der lavaan-Befehl. Dieser nimmt eine ganze Reihe an Argumenten entgehen, von denen allerdings nur zwei zwingend erforderlich sind:
model: Das zu schätzende Modelldata: Der Datensatz auf den das Modell angepasst werden soll
Alle anderen Argumente haben - für die meisten Analysen sinnvolle - Voreinstellungen. Weil die Modellschätzung mit lavaan sehr viele Ergebnisse und Details zum Schätzverfahren erzeugt, ist es ratsam das angepasste Modell in einem Objekt abzulegen.
fit <- lavaan(mod, fairplayer)
Sofern keine Warn- oder Fehlermeldungen erzeugt werden, war die Schätzung des Modells erfolgreich. Wie auch bei lm oder anderen Funktionen aus dem letzten Semester, kann der Datensatz, der an lavaan gegeben wird, auch Variablen enthalten, die für das Modell irrelevant sind. Alle manifesten Variablen, auf die im Modell bezug genommen wird, sucht sich lavaan aus dem Datensatz heraus.
Ergebnisinspektion
lavaan bietet eine ganze Reihe von Möglichkeiten, die Ergebnisse von Modellen genauer unter die Lupe zu nehmen. Die naheliegendste ist - wie schon bei lm - der allgemeine summary Befehl:
summary(fit)
lavaan::summary(fit)
Diese Ausgabe enthält neben Modellergebnissen auch einige Informationen zur Schätzprozedur, auf die wir hier erst einmal noch nicht eingehen werden. Die erste Zahl, mit der wir uns näher auseinandersetzen können, ist die Number of free parameters in der 3. Zeile der Ausgabe. Hier wird uns gesagt, dass wir vier Paramter schätzen mussten. Wenn wir uns das Pfaddiagramm für diese Regression noch einmal vor Augen führen, wird schnell deutlich, welche vier das sind:
- Regressionsgewicht $\beta_1$ von $SI_1$
- Regressionsgewicht $\beta_2$ von $EM_1$
- Achsenabschnitt / Intercept $\alpha$
- Varianz der Residuen $\epsilon$
Die nächste für uns relevante Information ist die Number of observations, welche in Used und Total unterteilt wird. Hier wird uns verraten, dass wir zwar r nrow(fairplayer) Personen im Datensatz haben, aber für unsere Analyse aufgrund fehlender Werte nur r inspect(fit, 'nobs') genutzt werden konnten.
Dann springen wir direkt runter zu den Modellergebnissen, die mit der Zeile Regressions: beginnen. Wie diese Überschrift verrät, erhalten wir zuerst Informationen über die Regressionsparameter. Hier der relevante Ausschnitt:
abbrev(fit, 'Regressions', 'Intercepts')
Dieser Abschnitt beginnt mit der Zeile rat1 ~, was uns verdeutlichen soll, dass die folgenden Regressionsergebnisse sich auf eine Regression mit relationaler Aggression als abhängige Variable beziehen. Die anschließende Tabelle enthält die gleichen vier Spalten, die wir schon bei der Wiederholung der Regression gesehen haben: das geschätzte Regressionsgewicht (Estimate), den Standardfehler (Std.Err.), den $z$-Wert (z-value) und den daraus resultierenden $p$-Wert (P(>|z|)). Wie Ihnen mit Sicherheit sofort aufgefallen ist, arbeitet lavaan nicht mit $t$- sondern mit $z$-Werten. Das heißt, dass hier von vornherein eine größere Stichprobe angenommen wird, um korrekte inferenzstatistische Schlüsse ziehen zu können. Wir können diese Ergebnisse direkt noch einmal mit den Ergebnissen aus lm vergleichen:
summary(lm(rat1 ~ sit1 + emt1, fairplayer))$coef
Wie Sie sehen, sind die Parameter zwar identisch, die Inferenzstatistik unterscheidet sich zwischen beiden Herangehensweisen aber. Woher das kommt, werden wir im Verlauf des Semesters noch genauer untersuchen.
Anders als bei lm werden in lavaan die Intercepts von den Regressionsgewichten getrennt ausgegeben:
abbrev(fit, 'Intercept', 'Variances')
Hier wird das Intercept von rat1 ausgegeben. Der . vor dem Variablennamen verrät uns, dass es sich um einen bedingten Mittelwert handelt, die Variable rat1 also irgendwo im Modell eine abhängige Variable ist. Diese Notation hilft besonders bei sehr komplexen Modellen, auch wenn es in unserem Beispiel noch leicht ist, den Überblick zu behalten.
Zu guter Letzt folgt ein Abschnitt mit Varianzen - in unserem Fall nur eine:
abbrev(fit, 'Variances', ellipses = 'top', shift = 1)
Auch hier verrät uns der ., dass rat1 irgendwo im Modell eine abhängige Variable ist, sodass es sich bei dieser Varianz um eine Residualvarianz handelt.
Weil der Output der summary Funktion sehr schnell sehr lang wird und es nicht erlaubt, einzelne Ergebnisse direkt als Objekte weiterzuverwenden, gibt es für lavaan die Funktion inspect. Diese nimmt zwei Argumente entgegen:
object: Das Ergebnisobjekt (bei uns alsofit)what: Was inspiziert werden soll
Die Liste mögicher whats ist mehrere Seiten lang. Sie finden Sie bei ?inspect. Eine Sache, die uns schon bei der lm Regression interessiert hat, war das $R^2$. Hierfür können wir inspect nutzen:
inspect(fit, 'rsquare')
Dieser Befehl wird im Verlauf des Semesters noch sehr praktisch, weil wir uns so nicht immer durch den gesamten Output wühlen müssen, sondern uns stets auf das beschränken können, was gerade relevant ist. Sie können im folgenden Feld auch ein paar andere Aspekte der Ergebnisse inspizieren. Probieren Sie gerne aus der Liste möglicher Angaben aus, was Ihnen in den Sinn kommt!
# Anzahl der Beobachtungen inspect(fit, 'nobs') # Anzahl der Parameter inspect(fit, 'npar')
fairplayer$rat1 <- rowMeans(fairplayer[, c('ra1t1', 'ra2t1', 'ra3t1')], na.rm = TRUE) fairplayer$emt1 <- rowMeans(fairplayer[, c('em1t1', 'em2t1', 'em3t1')], na.rm = TRUE) fairplayer$sit1 <- rowMeans(fairplayer[, c('si1t1', 'si2t1', 'si3t1')], na.rm = TRUE) mod <- 'rat1 ~ 1 + sit1 + emt1 rat1 ~~ rat1' fit <- lavaan(mod, fairplayer)
Übungsaufgaben
Die Übungsaufgaben finden Sie als Quiz im OLAT Kurs. Für die Bearbeitung der Aufgaben benötigen Sie den fairplayer Datensatz. Um diesen zu laden, nutzen Sie bitte
data(fairplayer, package = 'PsyMSc1')
Vergessen Sie außerdem nicht, mit
library(lavaan)
lavaan zu laden, bevor Sie loslegen!
Falls Sie die Quiz-Aufgaben lieber im Browser bearbeiten möchten oder diese Sitzung über Shinyapps.io beziehen, können Sie das untenstehende R-Fenster benutzen, um den Code für die Übungen zu schreiben und auszuführen.
Literatur
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden (5. Auflage, 1. Auflage: 2010). Weinheim: Beltz.
Rosseel, Y. (2012). lavaan: [An R Package for Structural Equation Modeling]. Journal of Statistical Software, 48(2), 1 - 36. doi:http://dx.doi.org/10.18637/jss.v048.i02
Schultze, M. (2019). R Crash-Kurs. Retrieved from https://pandar.netlify.com/post/r-crash-kurs/.
- Blau hinterlegte Autorenangaben führen Sie direkt zur universitätsinternen Ressource.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.