Nothing
Exporting estimation tables"
In fixest: Fast Fixed-Effects Estimations
knitr::opts_chunk$set(echo = TRUE, comment = "#>")
is_pander = requireNamespace("pander", quietly = TRUE)
if(is_pander) library(pander)
library(fixest)
setFixest_notes(FALSE)
setFixest_etable(digits = 3)
fixest offers a tool, the function etable, to view estimation tables in R or export them to Latex.
The main advantage of this function is its simplicity: it is completely integrated with other fixest functions, making it exceedingly easy to export multiple estimation results with, say, different types of standard-errors. On the other hand, its main limitations are that i) only fixest objects can be exported, and ii) only Latex is supported (although the use of post-processing functions opens up a lot of possibilities).
It also offers a fair deal of customization, and since you can seamlessly change its default values, you can completely transform the style of your tables without modifying a single line of code.
Note that there exists excellent alternatives to export tables, like for instance modelsummary (if you don't know it already, please do have a look, it's really great!); but they are less integrated with fixest objects, possibly necessitating more lines of code to export the same results.
This document does not describe etable's arguments in details (the help page provides many examples). Rather, it illustrates some features that may be hidden at first sight.
This document applies to fixest version 0.10.2 or higher.
Preliminaries
Throughout this document, we will use data from the airquality data base. We also set a dictionary that will be used to rename the variables used in etable. This dictionary is set once and for all.
library(fixest)
data(airquality)
# Setting a dictionary
setFixest_dict(c(Ozone = "Ozone (ppb)", Solar.R = "Solar Radiation (Langleys)",
Wind = "Wind Speed (mph)", Temp = "Temperature"))
Exporting multiple estimations to data.frames
Let's estimate the following four models and cluster the standard-errors by Day:
# On multiple estimations: see the dedicated vignette
est = feols(Ozone ~ Solar.R + sw0(Wind + Temp) | csw(Month, Day),
airquality, cluster = ~Day)
By default, when the argument file is missing, the function etable returns a data.frame. Let's see the output of the previous estimations:
etable(est)
What can we notice? First, the variables are properly labeled. Second, the fixed-effects section details which fixed-effects is included in which model. Third, the type of standard-error is reminded in a dedicated row.
Starting from this table, two elements are detailed: a) how to change the look of the table with the style.df argument, b) how to leverage tools from other packages with the postprocess.df argument.
Changing the look of the data.frame with style.df
You can change many elements of the data.frame with the argument style.df whose input must come from the function style.df. The style monitors many elements of the table, in particular the titles of the sections. Let's have an example:
etable(est, style.df = style.df(depvar.title = "", fixef.title = "",
fixef.suffix = " fixed effect", yesNo = "yes"))
In the previous example, the dependent variable and fixed-effects (FE) headers have been removed, and this is achieved with the (explicit) arguments depvar.title and fixef.title. Furthermore the suffix "fixed effect" is added to each fixed-effect variable, and the indicator of which FE is included in which model is slightly changed. There are more options that are described in the style.df documentation.
Postprocessing with external functions
Since the output of etable is a data.frame, any formatting function handling data.frames can be leveraged. It is then very easy to integrate it into etable. Let's have an example with the package pander:
# NOTE:
# The evaluation of the code of this section requires the
# package 'pander' which is not installed.
# The code output is not reported.
library(pander)
etable(est, postprocess.df = pandoc.table.return, style = "rmarkdown")
What did it do? First, it called the function pandoc.table.return from within etable. Second, the argument style is not from etable but is from pander's function. Indeed, all the arguments to the postprocessing function are caught and passed to it. So far so good. But you could say: why bother using the posprocessing function when we could just use piping? You're right, but wait a second for the next section.
Setting etable default values
One important feature of etable is that you can set the default values of almost all its arguments. This includes the postprocessing function. Let's change the default values of style.df and postprocess.df:
my_style = style.df(depvar.title = "", fixef.title = "",
fixef.suffix = " fixed effect", yesNo = "yes")
setFixest_etable(style.df = my_style, postprocess.df = pandoc.table.return)
Since now pandoc.table.return is the default postprocessing, all its arguments are added to etable. So calls like that are valid even though style or caption are not arguments from etable:
etable(est[rhs = 2], style = "rmarkdown", caption = "New default values")
Exporting multiple estimations to Latex
We now illustrate the exports to Latex. First, to include all the sections of a table, let's add a fifth estimation to the previous example; this new estimation includes variables with varying slopes:
est_slopes = feols(Ozone ~ Solar.R + Wind | Day + Month[Temp], airquality)
To export to Latex, use the argument tex = TRUE (note that this argument is on when the argument file is not missing):
etable(est, est_slopes, tex = TRUE)
# etable(est, est_slopes, file = "../_VIGNETTES/vignette_etable.tex", replace = TRUE)
# etable(est, est_slopes, file = "../_VIGNETTES/vignette_etable.tex", style.tex = style.tex("aer"), fitstat = ~ r2 + n, signif.code = NA)
The previous code produces the following table:
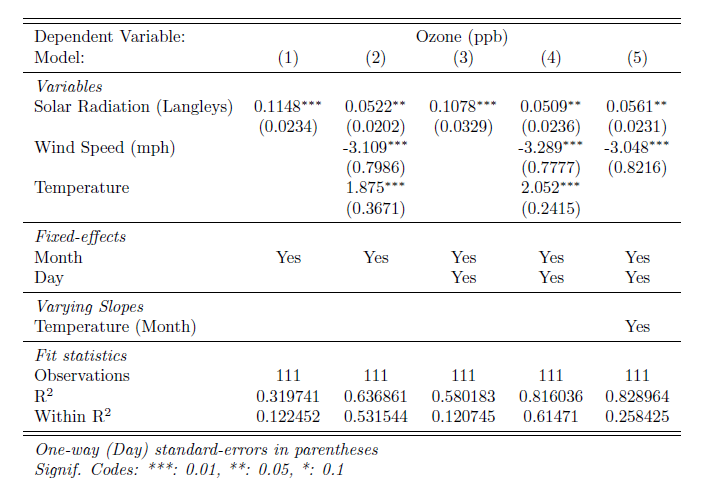
The style of the table is rather sober, but no worries: most of it can be customized. We now illustrate: a) how to change the look of the table with the argument style.tex, and how to include custom features with the argument postproces.tex.
Changing the look of the Latex table with style.tex
The argument style.tex defines how the table looks. It allows an in-depth customization of the table. The table is split into several components, each allowing some customization. The components of a table and some of its associated keywords are described by the following figure:
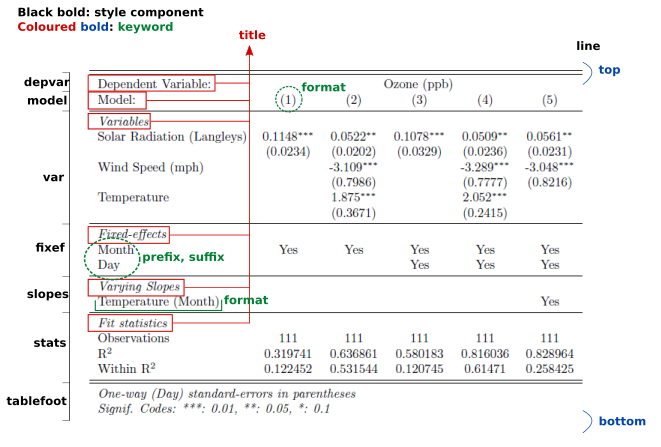
The argument style.tex only accepts outputs from the function style.tex. That function is documented and describes the different components that can be found in the previous illustration.
The function style.tex has two starting points (in the argument main), either the style of the first table displayed, either a much more compact style named "aer". Let's show the same table with the aer style, without stars beside the coefficients, and different fit statistics:
etable(est, est_slopes, style.tex = style.tex("aer"),
signif.code = NA, fitstat = ~ r2 + n, tex = TRUE)
Which yields the following table:

Adding custom features with postprocess.tex
When tex = TRUE etable returns a character vector. It is possible to modify it at will with the argument postprocess.tex. When a postprocessing function is detected, two additional tags are added to the character vector identifying the start and end of the table ("%start:tab\\n" and "%end:tab\\n").
Assume we want to set the rule widths of the table, we could write the following function:
set_rules = function(x, heavy, light){
# x: the character vector returned by etable
tex2add = ""
if(!missing(heavy)){
tex2add = paste0("\\setlength\\heavyrulewidth{", heavy, "}\n")
}
if(!missing(light)){
tex2add = paste0(tex2add, "\\setlength\\lightrulewidth{", light, "}\n")
}
if(nchar(tex2add) > 0){
x[x == "%start:tab\n"] = tex2add
}
x
}
Now we can summon that function from etable:
etable(est, est_slopes, postprocess.tex = set_rules, heavy = "0.14em", tex = TRUE)
Of course it is even more convenient to set set_rules as the default postprocessing function.
Setting etable default values: Latex edition
To set the default values, like for the data.frame output, use setFixest_etable:
setFixest_etable(style.tex = style.tex("aer", signif.code = NA), postprocess.tex = set_rules,
fitstat = ~ r2 + n)
Now we can access directly the arguments of the postprocessing function and the default style is the one of the second table:
etable(est, heavy = "0.14em", tex = TRUE)
Setting custom fit statistics
It is often useful to include in a table some fit statistics that are not standard, or simply that may not be included in fixest built-in fit statistics. While it is possible to include any extra line in the table with the argument extralines, this is rather cumbersome and possibly error-prone if this task has to be repeated.
To avoid that kind of issue, fixest allows the user to register custom fit statistics. Once they are registered, they can be seamlessly called via the fitstat argument in etable.
Let's continue with the previous example using the airquality data set, and now let's display different p-values of statistical significance for the variable Solar.R. These p-values will vary depending on how we compute the VCOV matrix.
Here is an example that will shortly be explained:
fitstat_register(type = "p_s", alias = "pvalue (standard)",
fun = function(x) pvalue(x, vcov = "iid")["Solar.R"])
fitstat_register(type = "p_h", alias = "pvalue (Heterosk.)",
fun = function(x) pvalue(x, vcov = "hetero")["Solar.R"])
fitstat_register(type = "p_day", alias = "pvalue (Day)",
fun = function(x) pvalue(x, vcov = ~Day)["Solar.R"])
fitstat_register(type = "p_month", alias = "pvalue (Month)",
fun = function(x) pvalue(x, vcov = ~Month)["Solar.R"])
# We first reset the default values set in the previous sections
setFixest_etable(reset = TRUE)
# Now we display the results with the new fit statistics
etable(est, fitstat = ~ . + p_s + p_h + p_day + p_month)
The function fitstat_register is a tool to add fit statistics in the fitstat engine. The first argument, type, is the code name by which the statistic is to be summoned. The argument alias provides the row name of the statistics: how it should look in the table. Finally in the fun argument is the function computing the statistic. That function must apply to a fixest estimation and must also return a single value.
Once these statistics are registered, they can seamlessly be summoned with the argument fitstat and will appear in the order the user provide. Note that the dot in fitstat = ~ . + p_s + etc represents the default statistics to be displayed and need not be there.
Using external functions to export multiple results
Thanks to contributors (namely Karl Dunkle Werner), fixest objects are compatible with broom methods. This means that export functions building on broom can be leveraged, like for instance the excellent modelsummary.
In case you use external export tools, here are some tips.
Multiple estimations, like the object est in the previous examples, are a bit special and broom methods can't apply directly. To export them, you first need to coerce the results into a list: by simply using as.list(est).
By default in fixest the estimations are separated from the calculation of the VCOV matrices. That's not a problem when using etable since, after providing the argument vcov or cluster, all VCOVs are calculated at once. Using other tools for exportation requires a call to summary for each model to compute the appropriate standard-errors. But this process can also be automatized. The function .l() can be used to coerce several fixest objects to which summary can then be applied, for example:
summary(.l(est, est_slopes), cluster = ~ Month)
The previous code returns a list of the five estimations for which the standard-errors are all clustered at the Month level, and can then be exported with external software.
Try the fixest package in your browser
Any scripts or data that you put into this service are public.
fixest documentation built on March 18, 2026, 9:06 a.m.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
knitr::opts_chunk$set(echo = TRUE, comment = "#>") is_pander = requireNamespace("pander", quietly = TRUE) if(is_pander) library(pander) library(fixest) setFixest_notes(FALSE) setFixest_etable(digits = 3)
fixest offers a tool, the function etable, to view estimation tables in R or export them to Latex.
The main advantage of this function is its simplicity: it is completely integrated with other fixest functions, making it exceedingly easy to export multiple estimation results with, say, different types of standard-errors. On the other hand, its main limitations are that i) only fixest objects can be exported, and ii) only Latex is supported (although the use of post-processing functions opens up a lot of possibilities).
It also offers a fair deal of customization, and since you can seamlessly change its default values, you can completely transform the style of your tables without modifying a single line of code.
Note that there exists excellent alternatives to export tables, like for instance modelsummary (if you don't know it already, please do have a look, it's really great!); but they are less integrated with fixest objects, possibly necessitating more lines of code to export the same results.
This document does not describe etable's arguments in details (the help page provides many examples). Rather, it illustrates some features that may be hidden at first sight.
This document applies to fixest version 0.10.2 or higher.
Preliminaries
Throughout this document, we will use data from the airquality data base. We also set a dictionary that will be used to rename the variables used in etable. This dictionary is set once and for all.
library(fixest) data(airquality) # Setting a dictionary setFixest_dict(c(Ozone = "Ozone (ppb)", Solar.R = "Solar Radiation (Langleys)", Wind = "Wind Speed (mph)", Temp = "Temperature"))
Exporting multiple estimations to data.frames
Let's estimate the following four models and cluster the standard-errors by Day:
# On multiple estimations: see the dedicated vignette est = feols(Ozone ~ Solar.R + sw0(Wind + Temp) | csw(Month, Day), airquality, cluster = ~Day)
By default, when the argument file is missing, the function etable returns a data.frame. Let's see the output of the previous estimations:
etable(est)
What can we notice? First, the variables are properly labeled. Second, the fixed-effects section details which fixed-effects is included in which model. Third, the type of standard-error is reminded in a dedicated row.
Starting from this table, two elements are detailed: a) how to change the look of the table with the style.df argument, b) how to leverage tools from other packages with the postprocess.df argument.
Changing the look of the data.frame with style.df
You can change many elements of the data.frame with the argument style.df whose input must come from the function style.df. The style monitors many elements of the table, in particular the titles of the sections. Let's have an example:
etable(est, style.df = style.df(depvar.title = "", fixef.title = "", fixef.suffix = " fixed effect", yesNo = "yes"))
In the previous example, the dependent variable and fixed-effects (FE) headers have been removed, and this is achieved with the (explicit) arguments depvar.title and fixef.title. Furthermore the suffix "fixed effect" is added to each fixed-effect variable, and the indicator of which FE is included in which model is slightly changed. There are more options that are described in the style.df documentation.
Postprocessing with external functions
Since the output of etable is a data.frame, any formatting function handling data.frames can be leveraged. It is then very easy to integrate it into etable. Let's have an example with the package pander:
# NOTE: # The evaluation of the code of this section requires the # package 'pander' which is not installed. # The code output is not reported.
library(pander) etable(est, postprocess.df = pandoc.table.return, style = "rmarkdown")
What did it do? First, it called the function pandoc.table.return from within etable. Second, the argument style is not from etable but is from pander's function. Indeed, all the arguments to the postprocessing function are caught and passed to it. So far so good. But you could say: why bother using the posprocessing function when we could just use piping? You're right, but wait a second for the next section.
Setting etable default values
One important feature of etable is that you can set the default values of almost all its arguments. This includes the postprocessing function. Let's change the default values of style.df and postprocess.df:
my_style = style.df(depvar.title = "", fixef.title = "", fixef.suffix = " fixed effect", yesNo = "yes") setFixest_etable(style.df = my_style, postprocess.df = pandoc.table.return)
Since now pandoc.table.return is the default postprocessing, all its arguments are added to etable. So calls like that are valid even though style or caption are not arguments from etable:
etable(est[rhs = 2], style = "rmarkdown", caption = "New default values")
Exporting multiple estimations to Latex
We now illustrate the exports to Latex. First, to include all the sections of a table, let's add a fifth estimation to the previous example; this new estimation includes variables with varying slopes:
est_slopes = feols(Ozone ~ Solar.R + Wind | Day + Month[Temp], airquality)
To export to Latex, use the argument tex = TRUE (note that this argument is on when the argument file is not missing):
etable(est, est_slopes, tex = TRUE)
# etable(est, est_slopes, file = "../_VIGNETTES/vignette_etable.tex", replace = TRUE) # etable(est, est_slopes, file = "../_VIGNETTES/vignette_etable.tex", style.tex = style.tex("aer"), fitstat = ~ r2 + n, signif.code = NA)
The previous code produces the following table:
The style of the table is rather sober, but no worries: most of it can be customized. We now illustrate: a) how to change the look of the table with the argument style.tex, and how to include custom features with the argument postproces.tex.
Changing the look of the Latex table with style.tex
The argument style.tex defines how the table looks. It allows an in-depth customization of the table. The table is split into several components, each allowing some customization. The components of a table and some of its associated keywords are described by the following figure:
The argument style.tex only accepts outputs from the function style.tex. That function is documented and describes the different components that can be found in the previous illustration.
The function style.tex has two starting points (in the argument main), either the style of the first table displayed, either a much more compact style named "aer". Let's show the same table with the aer style, without stars beside the coefficients, and different fit statistics:
etable(est, est_slopes, style.tex = style.tex("aer"), signif.code = NA, fitstat = ~ r2 + n, tex = TRUE)
Which yields the following table:
Adding custom features with postprocess.tex
When tex = TRUE etable returns a character vector. It is possible to modify it at will with the argument postprocess.tex. When a postprocessing function is detected, two additional tags are added to the character vector identifying the start and end of the table ("%start:tab\\n" and "%end:tab\\n").
Assume we want to set the rule widths of the table, we could write the following function:
set_rules = function(x, heavy, light){ # x: the character vector returned by etable tex2add = "" if(!missing(heavy)){ tex2add = paste0("\\setlength\\heavyrulewidth{", heavy, "}\n") } if(!missing(light)){ tex2add = paste0(tex2add, "\\setlength\\lightrulewidth{", light, "}\n") } if(nchar(tex2add) > 0){ x[x == "%start:tab\n"] = tex2add } x }
Now we can summon that function from etable:
etable(est, est_slopes, postprocess.tex = set_rules, heavy = "0.14em", tex = TRUE)
Of course it is even more convenient to set set_rules as the default postprocessing function.
Setting etable default values: Latex edition
To set the default values, like for the data.frame output, use setFixest_etable:
setFixest_etable(style.tex = style.tex("aer", signif.code = NA), postprocess.tex = set_rules, fitstat = ~ r2 + n)
Now we can access directly the arguments of the postprocessing function and the default style is the one of the second table:
etable(est, heavy = "0.14em", tex = TRUE)
Setting custom fit statistics
It is often useful to include in a table some fit statistics that are not standard, or simply that may not be included in fixest built-in fit statistics. While it is possible to include any extra line in the table with the argument extralines, this is rather cumbersome and possibly error-prone if this task has to be repeated.
To avoid that kind of issue, fixest allows the user to register custom fit statistics. Once they are registered, they can be seamlessly called via the fitstat argument in etable.
Let's continue with the previous example using the airquality data set, and now let's display different p-values of statistical significance for the variable Solar.R. These p-values will vary depending on how we compute the VCOV matrix.
Here is an example that will shortly be explained:
fitstat_register(type = "p_s", alias = "pvalue (standard)", fun = function(x) pvalue(x, vcov = "iid")["Solar.R"]) fitstat_register(type = "p_h", alias = "pvalue (Heterosk.)", fun = function(x) pvalue(x, vcov = "hetero")["Solar.R"]) fitstat_register(type = "p_day", alias = "pvalue (Day)", fun = function(x) pvalue(x, vcov = ~Day)["Solar.R"]) fitstat_register(type = "p_month", alias = "pvalue (Month)", fun = function(x) pvalue(x, vcov = ~Month)["Solar.R"]) # We first reset the default values set in the previous sections setFixest_etable(reset = TRUE) # Now we display the results with the new fit statistics etable(est, fitstat = ~ . + p_s + p_h + p_day + p_month)
The function fitstat_register is a tool to add fit statistics in the fitstat engine. The first argument, type, is the code name by which the statistic is to be summoned. The argument alias provides the row name of the statistics: how it should look in the table. Finally in the fun argument is the function computing the statistic. That function must apply to a fixest estimation and must also return a single value.
Once these statistics are registered, they can seamlessly be summoned with the argument fitstat and will appear in the order the user provide. Note that the dot in fitstat = ~ . + p_s + etc represents the default statistics to be displayed and need not be there.
Using external functions to export multiple results
Thanks to contributors (namely Karl Dunkle Werner), fixest objects are compatible with broom methods. This means that export functions building on broom can be leveraged, like for instance the excellent modelsummary.
In case you use external export tools, here are some tips.
Multiple estimations, like the object est in the previous examples, are a bit special and broom methods can't apply directly. To export them, you first need to coerce the results into a list: by simply using as.list(est).
By default in fixest the estimations are separated from the calculation of the VCOV matrices. That's not a problem when using etable since, after providing the argument vcov or cluster, all VCOVs are calculated at once. Using other tools for exportation requires a call to summary for each model to compute the appropriate standard-errors. But this process can also be automatized. The function .l() can be used to coerce several fixest objects to which summary can then be applied, for example:
summary(.l(est, est_slopes), cluster = ~ Month)
The previous code returns a list of the five estimations for which the standard-errors are all clustered at the Month level, and can then be exported with external software.
Try the fixest package in your browser
Any scripts or data that you put into this service are public.
R Package Documentation
Browse R Packages
We want your feedback!
Note that we can't provide technical support on individual packages. You should contact the package authors for that.
Embedding an R snippet on your website
Add the following code to your website.
For more information on customizing the embed code, read Embedding Snippets.